使用Python检测和删除异常值
异常值是与其余(所谓的正常)对象显着不同的数据项/对象。它们可能是由测量或执行错误引起的。异常值检测的分析称为异常值挖掘。检测异常值的方法有很多种,去除过程和从panda的数据框中去除一个数据项是一样的数据框。
在这里,pandas 数据框用于更现实的方法,因为在实际项目中需要检测数据分析步骤中引起的异常值,同样的方法可用于列表和系列类型的对象。
数据集:
使用的数据集是波士顿住房数据集,因为它已预加载到 sklearn 库中。
Python3
# Importing
import sklearn
from sklearn.datasets import load_boston
import pandas as pd
import matplotlib.pyplot as plt
# Load the dataset
bos_hou = load_boston()
# Create the dataframe
column_name = bos_hou.feature_names
df_boston = pd.DataFrame(bos_hou.data)
df_boston.columns = column_name
df_boston.head()Python3
# Box Plot
import seaborn as sns
sns.boxplot(df_boston['DIS'])Python3
# Position of the Outlier
print(np.where(df_boston['DIS']>10))Python3
# Scatter plot
fig, ax = plt.subplots(figsize = (18,10))
ax.scatter(df_boston['INDUS'], df_boston['TAX'])
# x-axis label
ax.set_xlabel('(Proportion non-retail business acres)/(town)')
# y-axis label
ax.set_ylabel('(Full-value property-tax rate)/( $10,000)')
plt.show()Python3
# Position of the Outlier
print(np.where((df_boston['INDUS']>20) & (df_boston['TAX']>600)))Python3
# Z score
from scipy import stats
import numpy as np
z = np.abs(stats.zscore(df_boston['DIS']))
print(z)Python3
threshold = 3
# Position of the outlier
print(np.where(z > 3))Python3
# IQR
Q1 = np.percentile(df_boston['DIS'], 25,
interpolation = 'midpoint')
Q3 = np.percentile(df_boston['DIS'], 75,
interpolation = 'midpoint')
IQR = Q3 - Q1Python3
# Above Upper bound
upper = df_boston['DIS'] >= (Q3+1.5*IQR)
print("Upper bound:",upper)
print(np.where(upper))
# Below Lower bound
lower = df_boston['DIS'] <= (Q1-1.5*IQR)
print("Lower bound:", lower)
print(np.where(lower))Python3
# Importing
import sklearn
from sklearn.datasets import load_boston
import pandas as pd
# Load the dataset
bos_hou = load_boston()
# Create the dataframe
column_name = bos_hou.feature_names
df_boston = pd.DataFrame(bos_hou.data)
df_boston.columns = column_name
df_boston.head()
''' Detection '''
# IQR
Q1 = np.percentile(df_boston['DIS'], 25,
interpolation = 'midpoint')
Q3 = np.percentile(df_boston['DIS'], 75,
interpolation = 'midpoint')
IQR = Q3 - Q1
print("Old Shape: ", df_boston.shape)
# Upper bound
upper = np.where(df_boston['DIS'] >= (Q3+1.5*IQR))
# Lower bound
lower = np.where(df_boston['DIS'] <= (Q1-1.5*IQR))
''' Removing the Outliers '''
df_boston.drop(upper[0], inplace = True)
df_boston.drop(lower[0], inplace = True)
print("New Shape: ", df_boston.shape)输出:
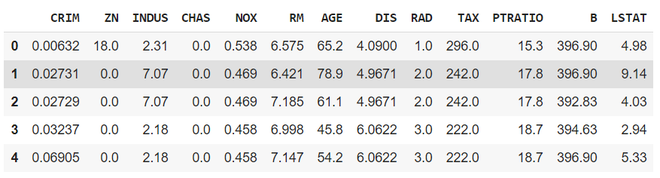
数据集的一部分
检测异常值
可以使用可视化、在数据集上实施数学公式或使用统计方法来检测异常值。所有这些都在下面讨论。
1. 可视化
示例 1:使用箱线图
它只用一个简单的盒子和胡须就能有效和高效地捕获数据的摘要。箱线图使用第 25、50 和 75 个百分位数汇总样本数据。只需查看其箱线图,就可以了解数据集(四分位数、中位数和异常值)。
蟒蛇3
# Box Plot
import seaborn as sns
sns.boxplot(df_boston['DIS'])
输出:
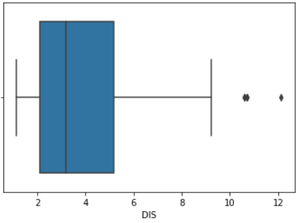
箱线图- DIS 列
在上图中,可以清楚地看到 10 以上的值作为异常值。
蟒蛇3
# Position of the Outlier
print(np.where(df_boston['DIS']>10))
输出:
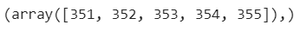
离群指数
示例 2:使用ScatterPlot 。
当您配对数值数据时,或者当您的因变量对于每个读数自变量具有多个值时,或者在尝试确定两个变量之间的关系时,将使用它。在利用散点图的过程中,还可以将其用于离群点检测。
要绘制散点图,需要两个以某种方式相互关联的变量。因此,这里使用了“每个城镇的非零售业务英亩的比例”和“每 10,000 美元的全值财产税率”,其列名称分别为“INDUS”和“TAX”。
蟒蛇3
# Scatter plot
fig, ax = plt.subplots(figsize = (18,10))
ax.scatter(df_boston['INDUS'], df_boston['TAX'])
# x-axis label
ax.set_xlabel('(Proportion non-retail business acres)/(town)')
# y-axis label
ax.set_ylabel('(Full-value property-tax rate)/( $10,000)')
plt.show()
输出:
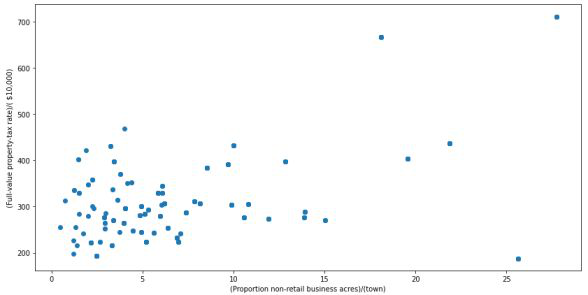
散点图
查看图表可以总结出大多数数据点位于图表的左下角,但很少有点正好相反,即图表的右上角。右上角的那些点可以被视为异常值。
使用近似可以说所有 x>20 和 y>600 的数据点都是异常值。以下代码可以获取满足这些条件的所有点的确切位置。
蟒蛇3
# Position of the Outlier
print(np.where((df_boston['INDUS']>20) & (df_boston['TAX']>600)))
输出:
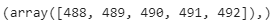
离群指数
2. Z-score
Z-Score 也称为标准分数。此值/分数有助于了解数据点与平均值之间的距离。设置阈值后,可以利用数据点的 z 分值来定义异常值。
Zscore = (data_point -mean) / std. deviation
蟒蛇3
# Z score
from scipy import stats
import numpy as np
z = np.abs(stats.zscore(df_boston['DIS']))
print(z)
输出:

列表的一部分(z)
以上输出只是部分数据的快照; list(z) 的实际长度是 506,即行数。它打印列的每个数据项的 z 得分值
现在要定义一个异常值阈值,通常选择 3.0。由于 99.7% 的数据点位于 +/- 3 标准偏差之间(使用高斯分布方法)。
蟒蛇3
threshold = 3
# Position of the outlier
print(np.where(z > 3))
输出:

离群指数
3.IQR(四分位距)
IQR (Inter Quartile Range) 寻找异常值的四分位间距方法是研究领域中最常用和最受信任的方法。
IQR = Quartile3 – Quartile1
蟒蛇3
# IQR
Q1 = np.percentile(df_boston['DIS'], 25,
interpolation = 'midpoint')
Q3 = np.percentile(df_boston['DIS'], 75,
interpolation = 'midpoint')
IQR = Q3 - Q1
输出:
要定义异常值基值,定义在数据集正常范围之上和之下,即上限和下限,定义上限和下限(考虑 1.5*IQR 值):
upper = Q3 +1.5*IQR
lower = Q1 – 1.5*IQR
上述公式中,根据统计,将IQR的0.5倍放大(new_IQR = IQR + 0.5*IQR),考虑了高斯分布中2.7个标准差之间的所有数据。
蟒蛇3
# Above Upper bound
upper = df_boston['DIS'] >= (Q3+1.5*IQR)
print("Upper bound:",upper)
print(np.where(upper))
# Below Lower bound
lower = df_boston['DIS'] <= (Q1-1.5*IQR)
print("Lower bound:", lower)
print(np.where(lower))
输出:
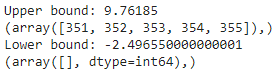
定义的边界和与边界相关的异常值索引
去除异常值
为了去除异常值,必须遵循使用其在数据集中的确切位置从数据集中删除条目的相同过程,因为在上述所有检测异常值的方法中,最终结果是满足异常值定义的所有数据项的列表根据使用的方法。
参考资料: 如何在Python精确删除一行?
dataframe.drop( row_index, inplace = True
给定要删除的 row_indexes,上面的代码可用于从数据集中删除一行。 Inplace =True 用于告诉Python在原始数据集中进行所需的更改。 row_index 只能是一个值或值列表或 NumPy 数组,但它必须是一维的。
例子:
df_boston.drop(lists[0],inplace = True)
完整代码:使用 IQR 检测异常值并删除它们。
蟒蛇3
# Importing
import sklearn
from sklearn.datasets import load_boston
import pandas as pd
# Load the dataset
bos_hou = load_boston()
# Create the dataframe
column_name = bos_hou.feature_names
df_boston = pd.DataFrame(bos_hou.data)
df_boston.columns = column_name
df_boston.head()
''' Detection '''
# IQR
Q1 = np.percentile(df_boston['DIS'], 25,
interpolation = 'midpoint')
Q3 = np.percentile(df_boston['DIS'], 75,
interpolation = 'midpoint')
IQR = Q3 - Q1
print("Old Shape: ", df_boston.shape)
# Upper bound
upper = np.where(df_boston['DIS'] >= (Q3+1.5*IQR))
# Lower bound
lower = np.where(df_boston['DIS'] <= (Q1-1.5*IQR))
''' Removing the Outliers '''
df_boston.drop(upper[0], inplace = True)
df_boston.drop(lower[0], inplace = True)
print("New Shape: ", df_boston.shape)
输出:
