本文讨论了Softmax回归的基础及其使用TensorFlow库在Python的实现。
什么是Softmax回归?
Softmax回归(或多项式logistic回归)是对我们要处理多个类的情况的logistic回归的概括。
线性回归的简要介绍可以在这里找到:
了解逻辑回归
在二进制逻辑回归中,我们假设标签是二进制的,即对于![]() 观察,
观察, ![]()
但是考虑一个场景,在该场景中,我们需要从两个或多个类标签中对观察进行分类。例如,数字分类。在这里,可能的标签是: ![]()
在这种情况下,我们可以使用Softmax回归。
让我们首先定义我们的模型:
- 让数据集具有“ m”个特征和“ n”个观测值。此外,还有“ k”个类别标签,即,每个观察值都可以归类为“ k”个可能的目标值之一。例如,如果我们有一个包含100个手写矢量图像的数据集,用于矢量分类,其尺寸为28×28,则n = 100,m = 28×28 = 784和k = 10。
- 特征矩阵
特征矩阵 ,表示为:
,表示为:  这里,
这里,  表示的值
表示的值 的功能
的功能 观察。矩阵的尺寸为:
观察。矩阵的尺寸为: 
- 权重矩阵
我们定义一个权重矩阵 作为:
作为:  这里,
这里,  代表分配给的权重
代表分配给的权重 的功能
的功能 类标签。矩阵的尺寸为:
类标签。矩阵的尺寸为:  。最初,权重矩阵是使用一些正态分布填充的。
。最初,权重矩阵是使用一些正态分布填充的。
- Logit得分矩阵
然后,我们定义净输入矩阵(也称为logit得分矩阵), , 作为:
, 作为:  矩阵的尺寸为:
矩阵的尺寸为:  。
。
Currently, we are taking an extra column in feature matrix,
 and an extra row in weight matrix,
and an extra row in weight matrix,  . These extra columns and rows correspond to the bias terms associated with each prediction. This could be simplified by defining an extra matrix for bias,
. These extra columns and rows correspond to the bias terms associated with each prediction. This could be simplified by defining an extra matrix for bias,  of size
of size  where
where  . (In practice, all we need is a vector of size
. (In practice, all we need is a vector of size  and some broadcasting techniques for the bias terms!)
and some broadcasting techniques for the bias terms!)So, the final score matrix,
 is:
is: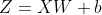
where
 matrix has dimensions
matrix has dimensions  while
while  has dimensions
has dimensions  . But
. But  matrix still has same value and dimensions!
matrix still has same value and dimensions!但是矩阵是什么
 表示?实际上,
表示?实际上,  是标签j的可能性
是标签j的可能性 观察。这不是一个适当的概率值,但是可以视为对每个观察结果给每个类别标签的分数!
观察。这不是一个适当的概率值,但是可以视为对每个观察结果给每个类别标签的分数!让我们定义
 作为logit得分向量
作为logit得分向量 观察。
观察。例如,让向量
![Z_5 = [1.1, 2.0, 3.1, 5.2, 1.0, 1.5, 0.2, 0.1, 1.2, 0.4]](https://mangdo-1254073825.cos.ap-chengdu.myqcloud.com//front_eng_imgs/geeksforgeeks2021/Softmax%20Regression%20using%20TensorFlow_36.jpg "由QuickLaTeX.com渲染") 代表每个班级标签的分数
代表每个班级标签的分数 在手写数字分类问题
在手写数字分类问题 观察。在这里,最高分是5.2,对应于类别标签“ 3”。因此,我们的模型目前预测
观察。在这里,最高分是5.2,对应于类别标签“ 3”。因此,我们的模型目前预测 观察结果/图像为“ 3”。
观察结果/图像为“ 3”。
- Softmax层
使用得分值训练模型比较困难,因为在实现梯度下降算法以最小化成本函数时很难区分它们。因此,我们需要一些函数来标准化logit分数并使它们易于区分!为了转换分数矩阵 对于概率,我们使用Softmax函数。
对于概率,我们使用Softmax函数。
对于矢量
 ,softmax函数
,softmax函数 定义为:
定义为: 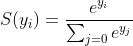 因此,softmax函数将执行以下两项操作:
因此,softmax函数将执行以下两项操作: 1. convert all scores to probabilities. 2. sum of all probabilities is 1.回想一下,在Binary Logistic分类器中,我们将sigmoid函数用于同一任务。 Softmax函数不过是S型函数的推广!现在,这个softmax函数计算出
 训练样本属于班级
训练样本属于班级 给定logits向量
给定logits向量 作为:
作为: 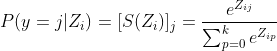
以矢量形式,我们可以简单地写成:
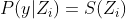
为简单起见,让
 表示用于的softmax概率向量
表示用于的softmax概率向量 观察。
观察。
- 一键编码目标矩阵
由于softmax函数为我们提供了给定观察值的每个类别标签的概率向量,因此我们需要以相同格式转换目标向量以计算成本函数!对应于每个观察值,都有一个目标矢量(而不是目标值!),该目标矢量仅由零和一个组成,其中仅将正确的标签设置为1。此技术称为“单热编码”。有关更好的信息,请参见下图理解:
现在,我们为
 观察为
观察为
- 成本函数
现在,我们需要定义一个成本函数,为此,我们必须比较softmax概率和一个热编码目标向量的相似度。我们同样使用交叉熵的概念。交叉熵是一种距离计算函数,它从softmax函数和创建的单编码矩阵中获取计算出的概率来计算距离。对于正确的目标类别,距离值将较小,而对于错误的目标类别,距离值将较大。我们定义了交叉熵, 为了
为了 使用softmax概率向量进行观察
使用softmax概率向量进行观察 和一热目标向量
和一热目标向量 作为:
作为: 
现在,成本函数
 可以定义为平均交叉熵,即:
可以定义为平均交叉熵,即: 
而任务是使这个成本函数最小化!
- 梯度下降算法
为了通过梯度下降学习我们的softmax模型,我们需要计算导数: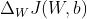 和
和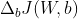 然后,我们将其用于更新梯度相反方向上的权重和偏差:
然后,我们将其用于更新梯度相反方向上的权重和偏差: 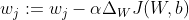 和
和 每堂课
每堂课 在哪里
在哪里 和
和 就是学习率。使用此成本梯度,我们迭代更新权重矩阵,直到达到指定的纪元数(经过训练集)或达到所需的成本阈值为止。
就是学习率。使用此成本梯度,我们迭代更新权重矩阵,直到达到指定的纪元数(经过训练集)或达到所需的成本阈值为止。
执行
现在让我们使用TensorFlow库在MNIST手写数字数据集上实现Softmax回归。
有关TensorFlow的简要介绍,请遵循以下教程:
TensorFlow简介
步骤1:导入依赖项
首先,我们导入依赖项。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
步骤2:下载资料
TensorFlow允许您自动下载和读取MNIST数据。考虑下面给出的代码。它将下载数据并将其保存到当前项目目录中的文件夹MNIST_data中,并将其加载到当前程序中。
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
Extracting MNIST_data/train-images-idx3-ubyte.gz
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
步骤3:了解资料
现在,我们尝试了解数据集的结构。
MNIST数据分为三个部分:55,000个数据训练数据( mnist.train ),10,000个测试数据( mnist.test )和5,000个验证数据( mnist.validation )。
每个图像为28像素x 28像素,已被展平为大小为784的1-D numpy数组。类标签的数量为10。每个目标标签已经以一种热编码的形式提供。
print("Shape of feature matrix:", mnist.train.images.shape)
print("Shape of target matrix:", mnist.train.labels.shape)
print("One-hot encoding for 1st observation:\n", mnist.train.labels[0])
# visualize data by plotting images
fig,ax = plt.subplots(10,10)
k = 0
for i in range(10):
for j in range(10):
ax[i][j].imshow(mnist.train.images[k].reshape(28,28), aspect='auto')
k += 1
plt.show()
输出:
特征矩阵的形状:(55000,784)目标矩阵的形状:(55000,10)第一次观察的一次热编码:[0. 0. 0. 0. 0. 0. 0. 1. 0. 0.] 
步骤4:定义计算图
现在,我们创建一个计算图。
# number of features
num_features = 784
# number of target labels
num_labels = 10
# learning rate (alpha)
learning_rate = 0.05
# batch size
batch_size = 128
# number of epochs
num_steps = 5001
# input data
train_dataset = mnist.train.images
train_labels = mnist.train.labels
test_dataset = mnist.test.images
test_labels = mnist.test.labels
valid_dataset = mnist.validation.images
valid_labels = mnist.validation.labels
# initialize a tensorflow graph
graph = tf.Graph()
with graph.as_default():
"""
defining all the nodes
"""
# Inputs
tf_train_dataset = tf.placeholder(tf.float32, shape=(batch_size, num_features))
tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels))
tf_valid_dataset = tf.constant(valid_dataset)
tf_test_dataset = tf.constant(test_dataset)
# Variables.
weights = tf.Variable(tf.truncated_normal([num_features, num_labels]))
biases = tf.Variable(tf.zeros([num_labels]))
# Training computation.
logits = tf.matmul(tf_train_dataset, weights) + biases
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
labels=tf_train_labels, logits=logits))
# Optimizer.
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
# Predictions for the training, validation, and test data.
train_prediction = tf.nn.softmax(logits)
valid_prediction = tf.nn.softmax(tf.matmul(tf_valid_dataset, weights) + biases)
test_prediction = tf.nn.softmax(tf.matmul(tf_test_dataset, weights) + biases)
需要注意的一些重要点:
- 对于训练数据,我们使用一个占位符,该占位符将在运行时与一个训练小批量进给。将微型批次用于梯度下降训练模型的技术称为随机梯度下降。
In both gradient descent (GD) and stochastic gradient descent (SGD), you update a set of parameters in an iterative manner to minimize an error function. While in GD, you have to run through ALL the samples in your training set to do a single update for a parameter in a particular iteration, in SGD, on the other hand, you use ONLY ONE or SUBSET of training sample from your training set to do the update for a parameter in a particular iteration. If you use SUBSET, it is called Minibatch Stochastic gradient Descent. Thus, if the number of training samples are large, in fact very large, then using gradient descent may take too long because in every iteration when you are updating the values of the parameters, you are running through the complete training set. On the other hand, using SGD will be faster because you use only one training sample and it starts improving itself right away from the first sample. SGD often converges much faster compared to GD but the error function is not as well minimized as in the case of GD. Often in most cases, the close approximation that you get in SGD for the parameter values are enough because they reach the optimal values and keep oscillating there.
- 使用遵循(截断的)正态分布的随机值初始化权重矩阵。这是使用tf.truncated_normal方法实现的。使用tf.zeros方法将偏差初始化为零。
- 现在,我们将输入与权重矩阵相乘,然后加上偏差。我们使用tf.nn.softmax_cross_entropy_with_logits来计算softmax和交叉熵(这是TensorFlow中的一项操作,因为它非常常见,可以对其进行优化)。我们使用tf.reduce_mean方法对所有训练示例中的交叉熵取平均值。
- 我们将使用梯度下降来最大程度地减少损失。为此,我们使用tf.train.GradientDescentOptimizer 。
- train_prediction , valid_prediction和test_prediction不是训练的一部分,而只是在这里,以便我们可以在训练时报告准确性数据。
步骤5:运行计算图
既然我们已经构建了计算图,那么现在是时候在会话中运行它了。
# utility function to calculate accuracy
def accuracy(predictions, labels):
correctly_predicted = np.sum(np.argmax(predictions, 1) == np.argmax(labels, 1))
accu = (100.0 * correctly_predicted) / predictions.shape[0]
return accu
with tf.Session(graph=graph) as session:
# initialize weights and biases
tf.global_variables_initializer().run()
print("Initialized")
for step in range(num_steps):
# pick a randomized offset
offset = np.random.randint(0, train_labels.shape[0] - batch_size - 1)
# Generate a minibatch.
batch_data = train_dataset[offset:(offset + batch_size), :]
batch_labels = train_labels[offset:(offset + batch_size), :]
# Prepare the feed dict
feed_dict = {tf_train_dataset : batch_data,
tf_train_labels : batch_labels}
# run one step of computation
_, l, predictions = session.run([optimizer, loss, train_prediction],
feed_dict=feed_dict)
if (step % 500 == 0):
print("Minibatch loss at step {0}: {1}".format(step, l))
print("Minibatch accuracy: {:.1f}%".format(
accuracy(predictions, batch_labels)))
print("Validation accuracy: {:.1f}%".format(
accuracy(valid_prediction.eval(), valid_labels)))
print("\nTest accuracy: {:.1f}%".format(
accuracy(test_prediction.eval(), test_labels)))
输出:
Initialized
Minibatch loss at step 0: 11.68728256225586
Minibatch accuracy: 10.2%
Validation accuracy: 14.3%
Minibatch loss at step 500: 2.239773750305176
Minibatch accuracy: 46.9%
Validation accuracy: 67.6%
Minibatch loss at step 1000: 1.0917563438415527
Minibatch accuracy: 78.1%
Validation accuracy: 75.0%
Minibatch loss at step 1500: 0.6598564386367798
Minibatch accuracy: 78.9%
Validation accuracy: 78.6%
Minibatch loss at step 2000: 0.24766433238983154
Minibatch accuracy: 91.4%
Validation accuracy: 81.0%
Minibatch loss at step 2500: 0.6181786060333252
Minibatch accuracy: 84.4%
Validation accuracy: 82.5%
Minibatch loss at step 3000: 0.9605385065078735
Minibatch accuracy: 85.2%
Validation accuracy: 83.9%
Minibatch loss at step 3500: 0.6315320730209351
Minibatch accuracy: 85.2%
Validation accuracy: 84.4%
Minibatch loss at step 4000: 0.812285840511322
Minibatch accuracy: 82.8%
Validation accuracy: 85.0%
Minibatch loss at step 4500: 0.5949224233627319
Minibatch accuracy: 80.5%
Validation accuracy: 85.6%
Minibatch loss at step 5000: 0.47554320096969604
Minibatch accuracy: 89.1%
Validation accuracy: 86.2%
Test accuracy: 86.5%
需要注意的一些重要点:
- 在每次迭代中,通过使用np.random.randint方法选择一个随机偏移值来选择一个小批量。
- 为了提供占位符tf_train_dataset和tf_train_label ,我们创建了一个feed_dict,如下所示:
feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels} - 一种执行计算步骤的快捷方式是:
_, l, predictions = session.run([optimizer, loss, train_prediction], feed_dict=feed_dict)执行优化步骤后,此节点返回损失和预测的新值。
这使我们结束了实现。完整的代码可以在这里找到。
最后,需要考虑以下几点:
- 您可以尝试调整学习率,批处理大小,时期数等参数,以获得更好的结果。您也可以尝试使用其他优化器,例如tf.train.AdamOptimizer。
- 通过使用具有一个或多个隐藏层的神经网络,可以提高上述模型的准确性。我们将在以后的一些文章中讨论使用TensorFlow的实现。
- Softmax回归与k个二元分类器
人们应该知道softmax回归在哪些情况下起作用以及在哪些情况下不起作用。在许多情况下,您可能需要为类标签的k个可能值中的每一个使用k个不同的二进制逻辑分类器。假设您正在处理计算机视觉问题,正在尝试将图像分为三个不同的类别:
情况1:假设您的班级是Indoor_scene,outdoor_urban_scene和outdoor_wilderness_scene。
情况2:假设您的班级是Indoor_scene,black_and_white_image和image_has_people。
在哪种情况下,您将使用Softmax回归分类器,在哪种情况下,您将使用3个二元Logistic回归分类器?
这将取决于3个类是否互斥。
在情况1中,场景可以是Indoor_scene,outdoor_urban_scene或outdoor_wilderness_scene。因此,假设每个训练示例都恰好用3个类别中的一个标记,我们应该建立一个k = 3的softmax分类器。
但是,在情况2中,类不是相互排斥的,因为场景既可以是室内的,也可以有室内的人。因此,在这种情况下,构建3个二元logistic回归分类器将更为合适。这样,对于每个新场景,您的算法都可以分别决定它是否属于3类。
参考:
- http://www.kdnuggets.com/2016/07/softmax-regression-related-logistic-regression.html
- https://classroom.udacity.com/courses/ud730
- http://ufldl.stanford.edu/wiki/index。的PHP/ Softmax_Regression