自动机器学习
Tpot 是Python中的自动化机器学习包,它使用遗传编程概念来优化机器学习管道。它通过智能探索数以千计的可能性来找到适合您数据的最佳参数,从而自动化机器学习中最乏味的部分。 Tpot 是 Tpot 建立在 scikit-learn 之上,所以它的代码看起来类似于 scikit-learn。
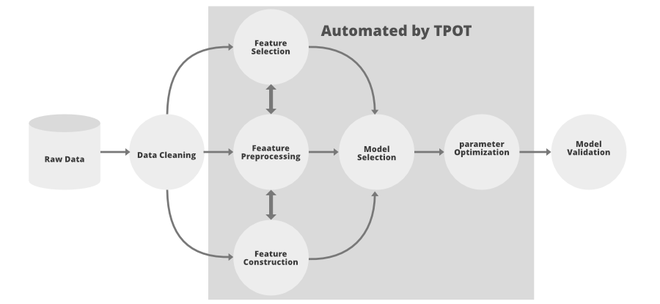
Tpot 自动化的 ML 管道的一部分
Tpot 使用遗传编程来生成优化的搜索空间,它们受到达尔文自然选择思想的启发,遗传编程使用以下特性:
- 选择:在这个阶段,在每个个体上评估适应度函数并将它们的值归一化,这样每个个体的值都在 0 到 1 之间,它们的总和为 1。之后,我们决定一个随机数 R b/w 0 和 1。 现在,我们保留那些适应度函数值大于或等于 R 的个体。
- 交叉:现在,我们可以从上面选择最适合的个体并在它们之间进行交叉以生成新的种群。
- 变异:变异交叉产生的个体并执行一些随机修改并重复几步或直到我们得到最佳种群
以下是Tpot的一些重要功能:
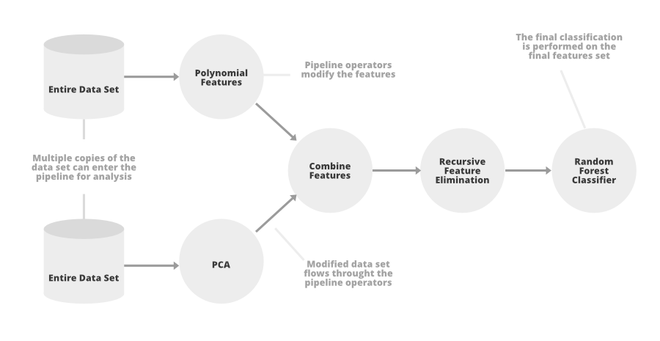
TpoT管道
- TpotClassifier:为监督分类任务执行自动学习的模块。以下是它需要的一些重要参数:
- 代:运行管道过程的迭代次数(默认值:100)。
- population_size :每代保留遗传编程种群的个体数(默认为 100)。
- offspring_size : 在每次遗传编程迭代中生成的后代数量。 (默认 100)。
- 突变率:突变率 b/w [0,1](默认 0.9)
- crossover_rate: 交叉率 b/w [0,1] (默认 0.1) {mutation rate + crossover_rate <= 1}。
- 评分:评估管道质量的指标。这里的评分采用精度、F1 分数等参数
- cv : 交叉验证方法,如果给定值是整数,那么在K-Fold交叉验证中它将是K。
- n_job :可以并行运行的进程数(默认为 1)。
- max_time_mins :Tpot 允许优化管道的最长时间(默认值:无)。
- max_eval_time_mins : TPOT评估单个管道需要多少分钟(默认值:无)。
- 详细程度: TPOT 在运行时显示的信息量。 {0:无,1:最少信息,2:更多信息和进度条,3:一切}(默认:0)
- TpotRegressor:为回归任务执行自动深度学习的模块。大多数参数与上面描述的 TpotClassifier 相同。这里唯一不同的参数是score 。在 TpotRegression 中,我们需要对回归进行评估,因此我们使用的参数如: 'neg_median_absolute_error'、'neg_mean_absolute_error'、'neg_mean_squared_error'、'r2'
这两个模块都提供了 4 个函数来拟合和评估数据集。这些是:
- fit(features, target):在给定数据上运行 TPOT 优化管道。
- predict(features):使用优化的管道来预测示例/特征集示例的目标值。
- score(test_features, test_target):在测试数据上评估模型并返回生成的最优化的分数
- export(output_file_name):将优化后的管道导出为Python代码。
执行
- 在这个实现中,我们将使用波士顿住房数据集,我们将使用“neg_mean_squared error”作为我们的评分函数。
Python3
# install TPot and other dependencies
!pip install sklearn fsspec xgboost
%pip install -U distributed scikit-learn dask-ml dask-glm
%pip install "tornado>=5"
%pip install "dask[complete]"
!pip install TPOT
# import required modules
from tpot import TPOTRegressor
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
import numpy as np
# load boston dataset
X, y = load_boston(return_X_y=True)
# divide the data into train and test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= .25)
# define TpotRegressor
reg = TPOTRegressor(verbosity=2, population_size=50, generations=10, random_state=35)
# fit the regressor on training data
reg.fit(X_train, y_train)
# print the results on test data
print(reg.score(X_test, y_test))
#save the model in top_boston.py
reg.export('top_boston.py')Generation 1 - Current best internal CV score: -13.196955982336481
Generation 2 - Current best internal CV score: -13.196955982336481
Generation 3 - Current best internal CV score: -13.196955982336481
Generation 4 - Current best internal CV score: -13.196015224855723
Generation 5 - Current best internal CV score: -13.143264025811806
Generation 6 - Current best internal CV score: -12.800705944988994
Generation 7 - Current best internal CV score: -12.717234303495596
Generation 8 - Current best internal CV score: -12.717234303495596
Generation 9 - Current best internal CV score: -11.707932909438588
Generation 10 - Current best internal CV score: -11.707932909438588
Best pipeline: ExtraTreesRegressor(input_matrix, bootstrap=False, max_features=0.7000000000000001, min_samples_leaf=1, min_samples_split=3, n_estimators=100)
-8.098697897637797- 现在,我们查看 TpotRegressor 生成的文件,即:该文件包含使用 Pandas 读取数据的代码和最佳回归器模型。
#tpot_boston.py
import numpy as np
import pandas as pd
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.model_selection import train_test_split
# NOTE: Make sure that the outcome column is labeled 'target' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = tpot_data.drop('target', axis=1)
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['target'], random_state=35)
# Average CV score on the training set was: -11.707932909438588
exported_pipeline = ExtraTreesRegressor(bootstrap=False, max_features=0.7000000000000001,
min_samples_leaf=1, min_samples_split=3, n_estimators=100)
# Fix random state in exported estimator
if hasattr(exported_pipeline, 'random_state'):
setattr(exported_pipeline, 'random_state', 35)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)参考:
- Tpot 文档