- 自动机器学习
- 自动机器学习(1)
- 使用 Pycaret 的机器学习工作流程
- 使用 Pycaret 的机器学习工作流程(1)
- 机器学习 (1)
- 机器学习中的 P 值(1)
- C++中的机器学习
- C++中的机器学习(1)
- 机器学习中的 P 值
- 工作流程流程(1)
- 工作流程流程
- 机器学习的通用工作流(1)
- 机器学习的通用工作流
- 机器学习 python (1)
- 机器学习 python 代码示例
- 量子机器学习的工作
- 机器学习 - 任何代码示例
- 机器学习-什么是P值(1)
- 什么是机器学习?
- 什么是机器学习?(1)
- 机器学习-什么是P值
- 在机器学习中什么是“i” (1)
- 学习 python 机器学习 - 任何代码示例
- 机器学习-什么是机器学习? -指导点
- 机器学习-什么是机器学习? -指导点(1)
- 机器学习算法
- 机器学习算法(1)
- 使用Python机器学习-方法(1)
- 使用Python机器学习-方法
📅 最后修改于: 2020-12-10 05:43:18 🧑 作者: Mango
介绍
为了成功执行并产生结果,机器学习模型必须使某些标准工作流程自动化。这些标准工作流程的自动化过程可以在Scikit-learn Pipelines的帮助下完成。从数据科学家的角度来看,管道是一个通用的但非常重要的概念。它基本上允许数据从其原始格式流向一些有用的信息。下图可以帮助理解管道的工作方式-
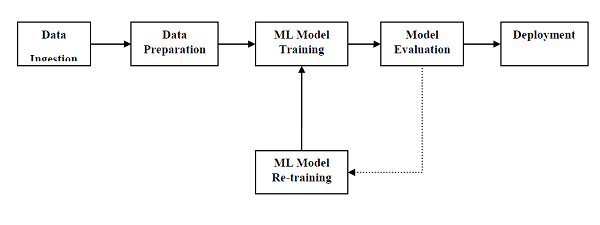
ML管道的块如下-
数据提取-顾名思义,这是导入数据以供ML项目使用的过程。可以从单个或多个系统实时或批量提取数据。这是最具挑战性的步骤之一,因为数据质量会影响整个ML模型。
数据准备-导入数据后,我们需要准备要用于ML模型的数据。数据预处理是最重要的数据准备技术之一。
机器学习模型训练-下一步是训练我们的机器学习模型。我们有各种ML算法,例如有监督,无监督,强化,可以从数据中提取特征并进行预测。
模型评估-接下来,我们需要评估ML模型。如果是AutoML管道,则可以借助各种统计方法和业务规则来评估ML模型。
ML模型再训练-在AutoML管道的情况下,第一个模型不一定是最佳模型。第一个模型被认为是基线模型,我们可以重复地训练它以提高模型的准确性。
部署-最后,我们需要部署模型。此步骤涉及将模型应用并迁移到业务操作以供使用。
ML管道带来的挑战
为了创建ML管道,数据科学家面临许多挑战。这些挑战分为以下三类-
数据质量
任何ML模型的成功都在很大程度上取决于数据质量。如果我们提供给ML模型的数据不准确,可靠且健壮,那么我们将以错误或误导的输出结束。
数据可靠性
与ML管道相关的另一个挑战是我们提供给ML模型的数据的可靠性。众所周知,数据科学家可以从各种来源获取数据,但要获得最佳结果,必须确保数据来源可靠且值得信赖。
数据可访问性
为了从ML管道中获得最佳结果,数据本身必须可访问,这需要对数据进行合并,清理和整理。由于数据可访问性属性,元数据将使用新标签进行更新。
ML管道建模和数据准备
从训练数据集到测试数据集的数据泄漏是数据科学家在为ML模型准备数据时要处理的重要问题。通常,在准备数据时,数据科学家会在学习之前对整个数据集使用诸如标准化或规范化之类的技术。但是这些技术无法帮助我们避免数据泄漏,因为训练数据集会受到测试数据集中数据规模的影响。
通过使用ML管道,我们可以防止这种数据泄漏,因为管道可确保将诸如标准化之类的数据准备工作限制在交叉验证过程的每一步。
例
以下是Python中的示例,演示了数据准备和模型评估工作流程。为此,我们使用了Sklearn的Pima印度糖尿病数据集。首先,我们将创建标准化数据的管道。然后,将创建线性判别分析模型,最后将使用10倍交叉验证对管道进行评估。
首先,导入所需的软件包,如下所示:
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
现在,我们需要像之前的示例一样加载Pima糖尿病数据集-
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=headernames)
array = data.values
接下来,我们将在以下代码的帮助下创建管道-
estimators = []
estimators.append(('standardize', StandardScaler()))
estimators.append(('lda', LinearDiscriminantAnalysis()))
model = Pipeline(estimators)
最后,我们将评估此管道并输出其准确性,如下所示:
kfold = KFold(n_splits=20, random_state=7)
results = cross_val_score(model, X, Y, cv=kfold)
print(results.mean())
输出
0.7790148448043184
上面的输出是数据集上设置准确性的摘要。
ML管道建模和特征提取
在ML模型的特征提取步骤中也可能发生数据泄漏。这就是为什么也应该限制特征提取过程以阻止我们的训练数据集中数据泄漏的原因。与数据准备一样,通过使用ML管道,我们也可以防止这种数据泄漏。 ML管道提供的FeatureUnion工具可用于此目的。
例
以下是Python中的示例,该示例演示了特征提取和模型评估工作流程。为此,我们使用了Sklearn的Pima印度糖尿病数据集。
首先,将使用PCA(主成分分析)提取3个特征。然后,将使用统计分析提取6个特征。特征提取后,多个特征选择和提取过程的结果将通过组合使用
FeatureUnion工具。最后,将创建Logistic回归模型,并使用10倍交叉验证对管道进行评估。
首先,导入所需的软件包,如下所示:
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.pipeline import FeatureUnion
from sklearn.linear_model import LogisticRegression
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest
现在,我们需要像之前的示例一样加载Pima糖尿病数据集-
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=headernames)
array = data.values
接下来,将按如下方式创建要素联合-
features = []
features.append(('pca', PCA(n_components=3)))
features.append(('select_best', SelectKBest(k=6)))
feature_union = FeatureUnion(features)
接下来,将在以下脚本行的帮助下创建管道-
estimators = []
estimators.append(('feature_union', feature_union))
estimators.append(('logistic', LogisticRegression()))
model = Pipeline(estimators)
最后,我们将评估此管道并输出其准确性,如下所示:
kfold = KFold(n_splits=20, random_state=7)
results = cross_val_score(model, X, Y, cv=kfold)
print(results.mean())
输出
0.7789811066126855
上面的输出是数据集上设置准确性的摘要。