机器学习中的 P 值
P 值可帮助我们确定在假设原假设为真时获得特定结果的可能性有多大。如果零假设是正确的,那么它是获得像我们这样或比我们更极端的样本的概率。因此,如果假设原假设为真,则 p 值可以让我们估计我们的样本有多“奇怪”。
如果 p 值非常小(通常认为 <0.05),那么我们的样本是“奇怪的”,这意味着我们关于原假设正确的假设很可能是错误的。因此,我们拒绝它。让我们通过几个例子来理解什么是 p 值:
例子:
1.抛硬币–
有两种可能的结果——正面(H),反面(T)。设原假设为 H 0 ,备择假设为 H 1 。 H 0 :这是一枚公平的硬币; H 1这是一个有偏见或不公平的硬币。让我们假设我们处于一个零假设为真的宇宙中。考虑以下事件——
| Event | p-value |
|---|---|
T | 0.5 |
T | 0.25 |
T | 0.12 |
T | 0.06 |
T | 0.03 |
T | 0.01 |
p 值是事件发生的概率,假设 H 0为真;也就是说,硬币是公平的(如果我们在 H 1为真的宇宙中,那么所有事件的 p 值将为 1)。尾部出现一次是很规律的,对于一枚公平的硬币,事件 1 的发生概率是 0.5。然而,每次我们抛硬币,结果都是一个尾巴!有什么值得怀疑的事情发生。因此,p 值在表中减小。尾部连续出现 6 次的概率为 0.01,相当低。该事件发生在 H 0为真的宇宙中的可能性只有 1%(我们必须非常幸运才能发生这样的事情)。
因此,当 p 值低于 0.05(在第 4 次事件之后)时,我们拒绝了假设成立的说法。 0.05 通常被认为是统计显着性。
2.饼干和坚果!! ——
玛丽卖巧克力坚果饼干。可悲的是,有人抱怨巧克力坚果饼干中的花生比预期的要少(一包 200 克的花生应该有 70 克)。因此,她想检查投诉是否有效。为此,她从 400 个饼干中随机抽取 20 个样品,打开包装并融化巧克力以称量每包中的坚果。如果所有20个样本的花生重量都远远超过70克,而平均值约为95克,则投诉肯定不成立。事实上,坚果的数量更多。考虑到所有20个样品中花生的重量都远小于70g,平均值约为30g。在这种情况下,cookie 有问题。
这里我们的原假设 (H 0 ) 和备择假设 (H 1 ) 如下:
- H 0 – 一包花生的平均重量 = 70 克(饼干没有问题)。
- H 1 – 一包花生的平均重量 < 70g。
如果所有包装中花生的重量都在接近 70g 的范围 (65,75) 内,并且平均值在 68.5g 左右,则很难确定我们关于 H 0为真的说法是否正确。在这种情况下,我们会找到此数据的 p 值与 70g 的平均值进行比较。假设我们得到的 p 值为 0.18。因此,如果饼干没有任何问题(H 0为真),即饼干中花生的平均重量 >= 70 克(玛丽松了一口气),则有 18% 的机会获得如此低的平均值(68.5 克) !)。
如果我们获得的 p 值小于显着性水平 0.05,我们将拒绝原假设。
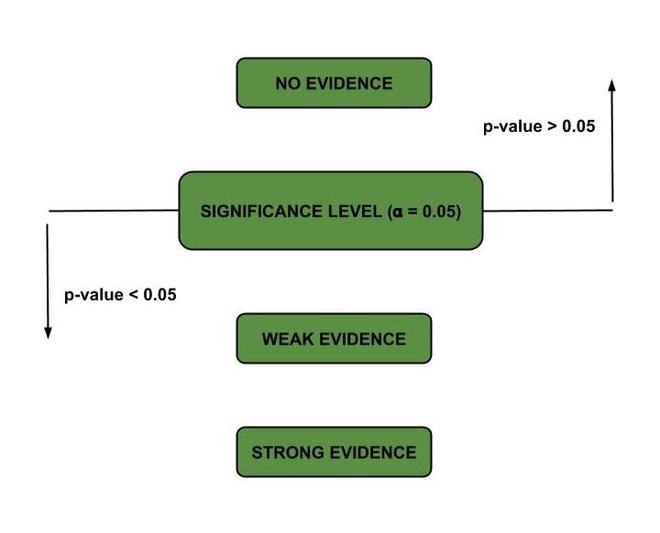
P值演示
因此,p 值告诉我们是否有来自样本的证据表明对总体有影响。如果 p 值高于显着性水平,我们就没有证据。当 p 值低于显着性水平时,我们的证据变得更有力,因此我们可以拒绝原假设正确的说法。
我们用来确定证据强度的程序如下:
- 假设H 0为真。
- 取一个样本,获取统计量(平均值),并计算出如果 H 0为真,获得这些数字的可能性有多大。告诉我们前者的参数是 p 值。
- 如果 p 值非常小,则 H 0可能是错误的。 p 值越低,我们就越有证据表明原假设为假。
- 如果 p 值很大,我们最初假设 H 0为真的想法可能是正确的。因此,我们不拒绝 H 0 –非显着结果。
- 与显着性水平(通常为 0.05)相比,P 值可小可大。它根据实验以及我们如何使用其结果进行调整。
因此,p 值不是–
- 声明有效的概率。
- 原假设为真的概率。
它是帮助我们确定在零假设正确的假设下样本有多“奇怪”的参数。因此,它有助于我们相应地修改原假设。