具有可教机器的机器学习模型
机器学习和人工智能提高了应用水平。许多组织正在研究人工智能,以对社会产生影响。机器学习是人工智能的支柱。但是每个人都不知道机器学习是如何工作的,以及如何创建可用于智能的模型。别担心,现在有可能。你可能想知道怎么做?对于非编码人员或非机器学习背景的编码人员来说,创建机器学习模型并将其集成到应用程序中非常容易。在本文中,我们将构建一个机器学习模型,而无需编写一行代码。
我们将创建一个食品分类模型。因此,我们将使用来自 Kaggle 的食物数据集,其中包含不同的食物,如蛋糕、沙拉、土豆等。您可以从 https://www.kaggle.com/cristeaioan/ffml-dataset 下载数据集。
可教机器
是的,我们将在可教机器的帮助下完成。可示教机器是一种基于 Web 的应用程序,可以轻松快速地创建模型。它服务于三个目的——图像、声音和姿势识别。好的部分是它很灵活。它可以教模型通过图像或实时网络摄像头对图像或姿势进行分类。它是免费的,最适合学生。通过 Teachable Machine 创建的模型是真正的 Tensorflow 模型,可以与 Web 应用程序、Android 应用程序或任何平台集成。也不需要创建帐户。它让一切变得如此简单。
让我们建立一个模型
第 1 步:转到 Teachable Machine (https://teachablemachine.withgoogle.com/train),您应该会被引导到下图所示的屏幕,该屏幕包含三个选项——图像、音频和姿势。
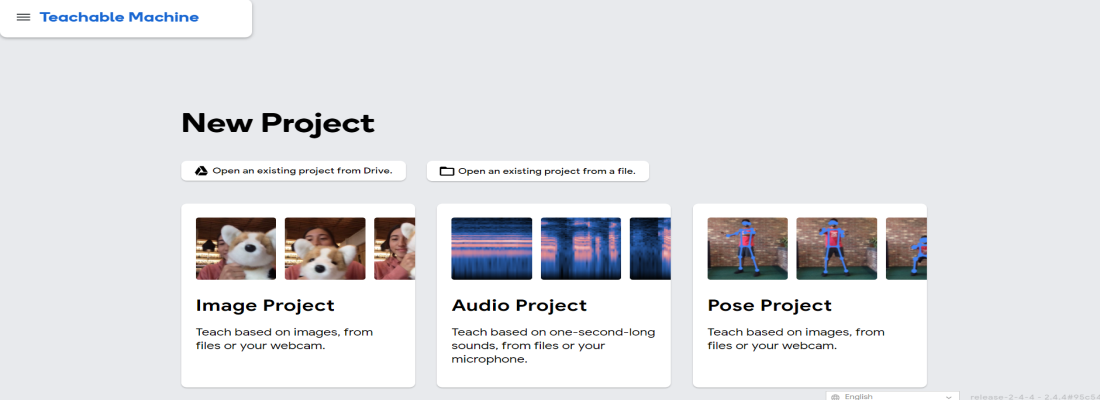
第二步:选择镜像项目,你会再次看到两个选项,标准和嵌入。选择标准,因为我们不是为了微控制器而制作它。好吧,如果您选择嵌入式图像模型。即使你选择了嵌入式,整个过程都是一样的,只是模式不同而已。

单击标准图像项目后,您将被定向到下图所示的屏幕,我们将在其中添加我们想要借助模型进行分类的类。有两种选择——要么从数据集中上传图像,要么使用实时摄像头捕捉图像。
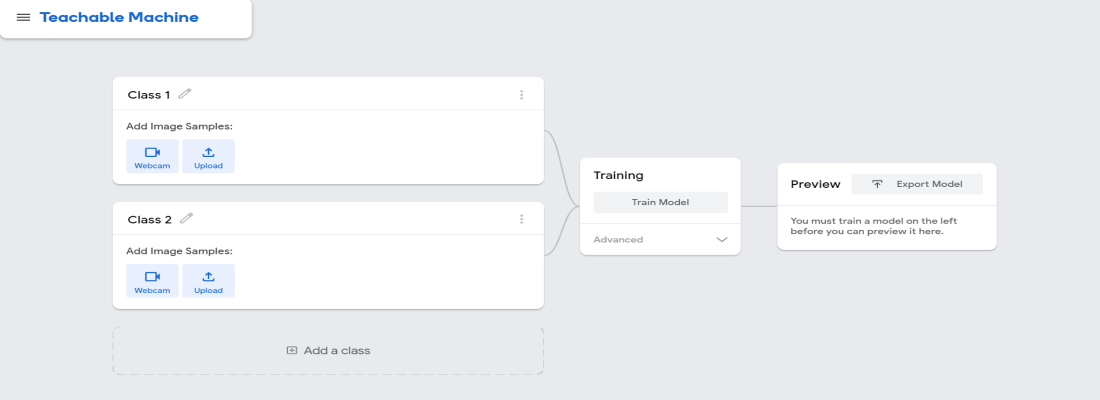
第 3 步:现在,创建类并开始上传图像,就像我正在做的那样。为简单起见,我只创建了三个类——Cake、Salad 和 Potato。因此,我将 class1 替换为 Cake,将 class2 名称替换为 Salad,将 class3 名称替换为 Potato。您可以根据需要创建任意数量。
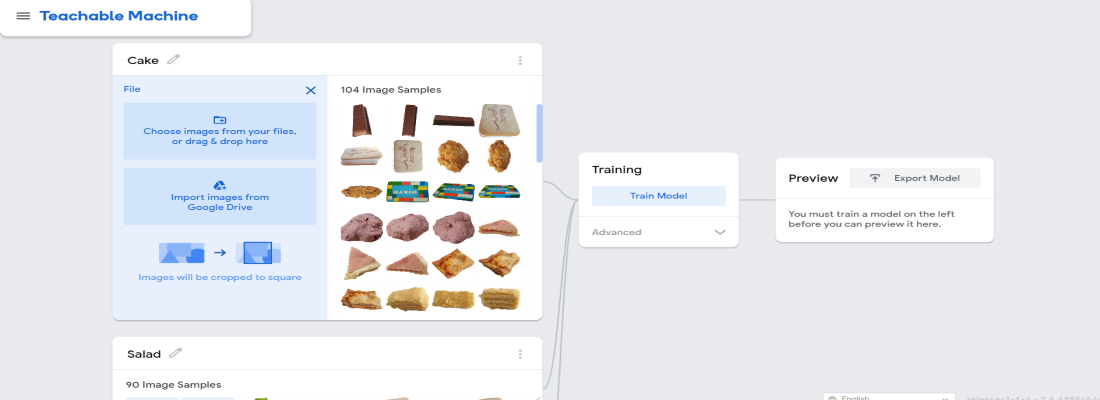
上传图片后,点击训练模型。您将看到不同的选项——时期、批量大小、学习率。如果您在生活中没有听说过这些,请不要担心。为了使模型更有效,重要的是要与它们一起玩并找出模型在哪个值下提供最高的准确性。当然,如果不够准确,模型就没有任何意义。因此,您可以更改它们的值并找出最佳值。在这里,我将使用默认值。
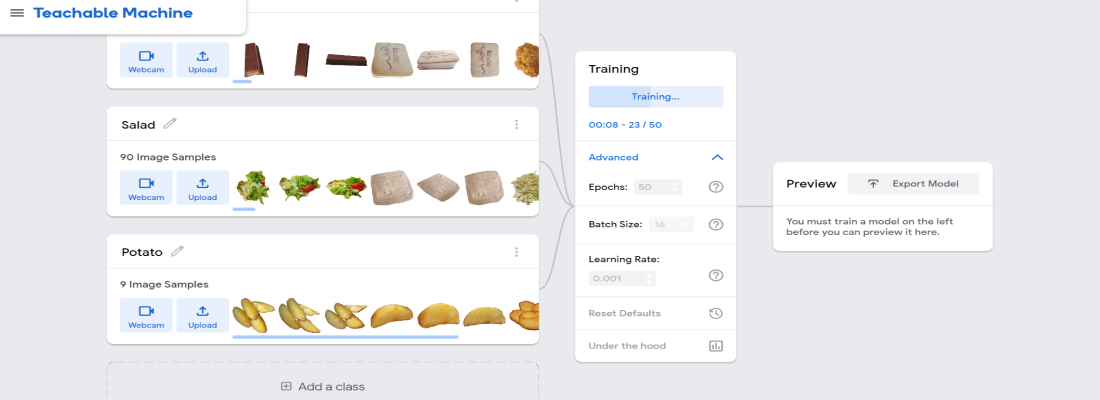
第 4 步:模型训练完成后,就可以导出模型了。
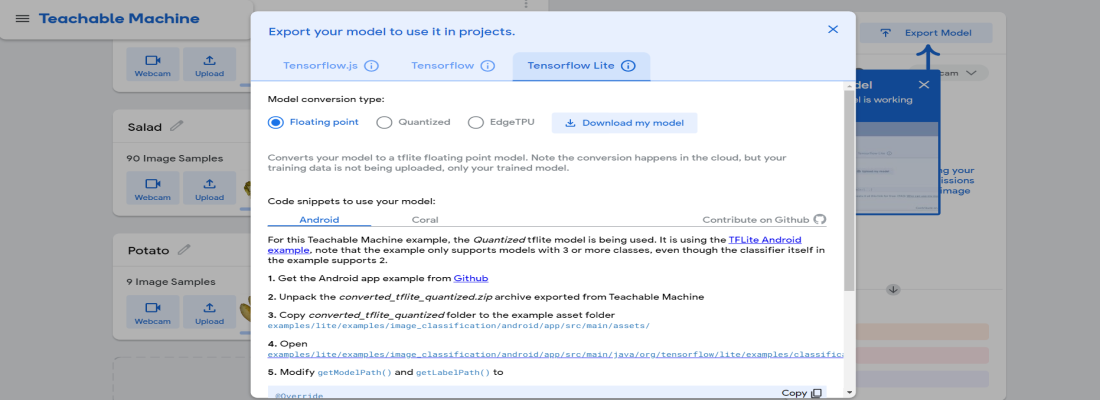
当您再次单击导出模型时,您将获得几个选项。甚至提供了代码片段来帮助您将模型与您的应用程序集成。 Tensorflow.js 模型适用于每个 JavaScript 库或框架。一些框架仅支持特定类型的模型。因此,请检查您的框架或库是否支持哪一个。
下载模型可能需要很长时间,所以请坐下来享受您的咖啡。您刚刚创建了一个没有编码的机器学习模型。
与图像姿势类似,我们也可以为音频和姿势创建模型。让我们看看如何做到这一点。
姿势模型
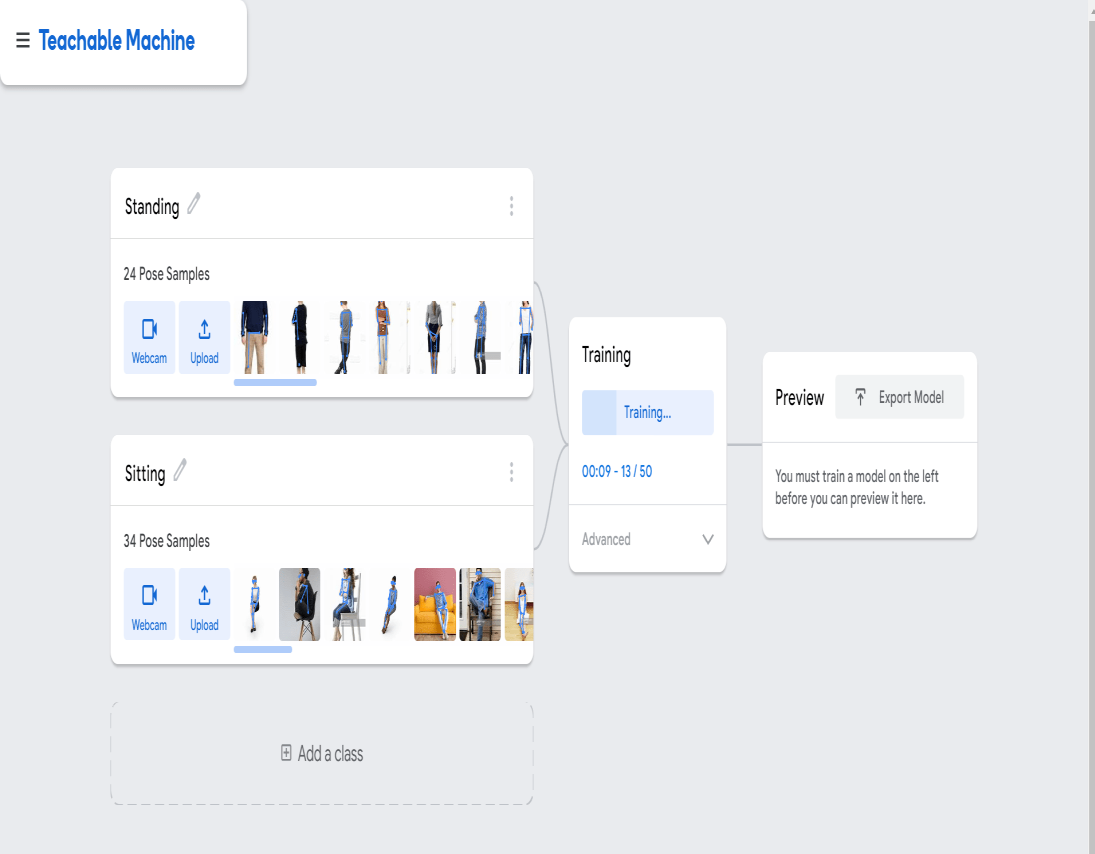
要创建姿势模型,我们必须在可教机器中选择姿势项目。在示例中,我们创建了两个不同的类,用于站立和坐着,并上传各自的图像。在我们开始训练模型之后。
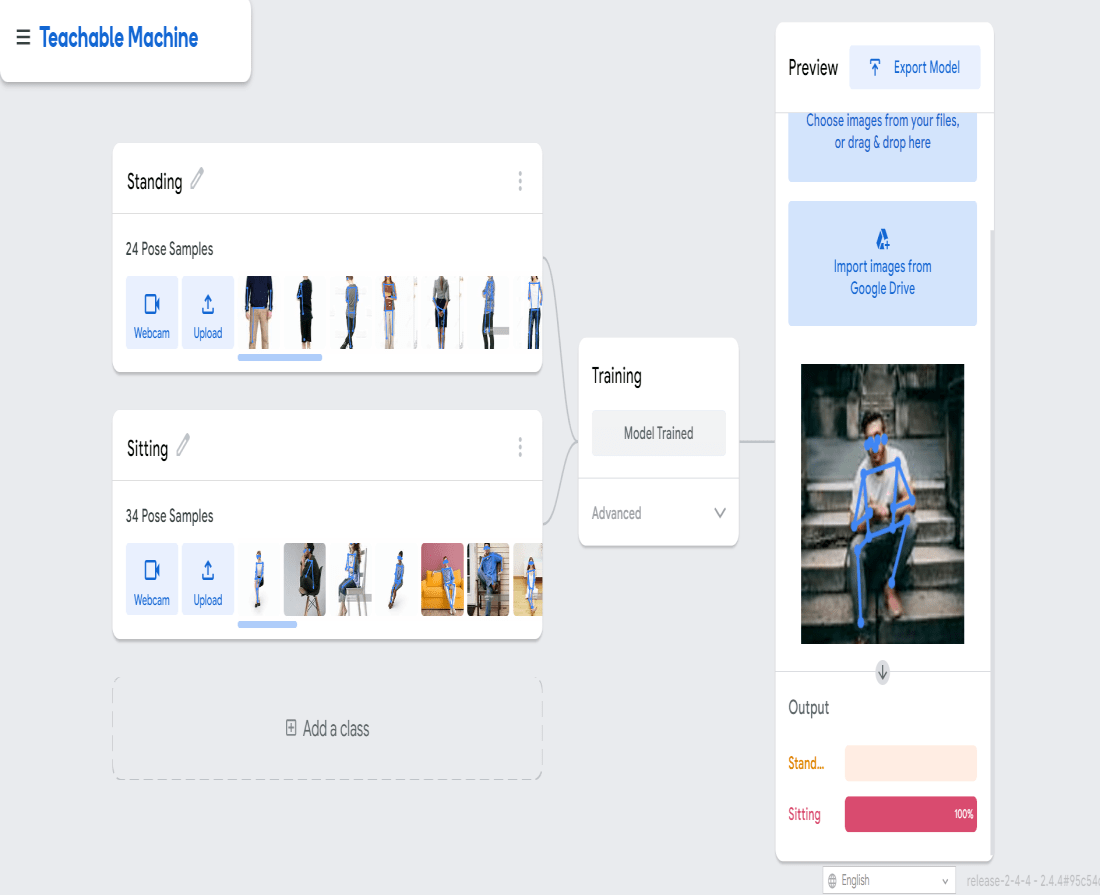
训练完成后,我们通过上传任何图像来预览模型的输出以查看输出,并在导出之前查看模型的效率。在下图中,我们可以看到我们上传用于预览的图像的输出是正确的,即坐着。这意味着模型做得很好。
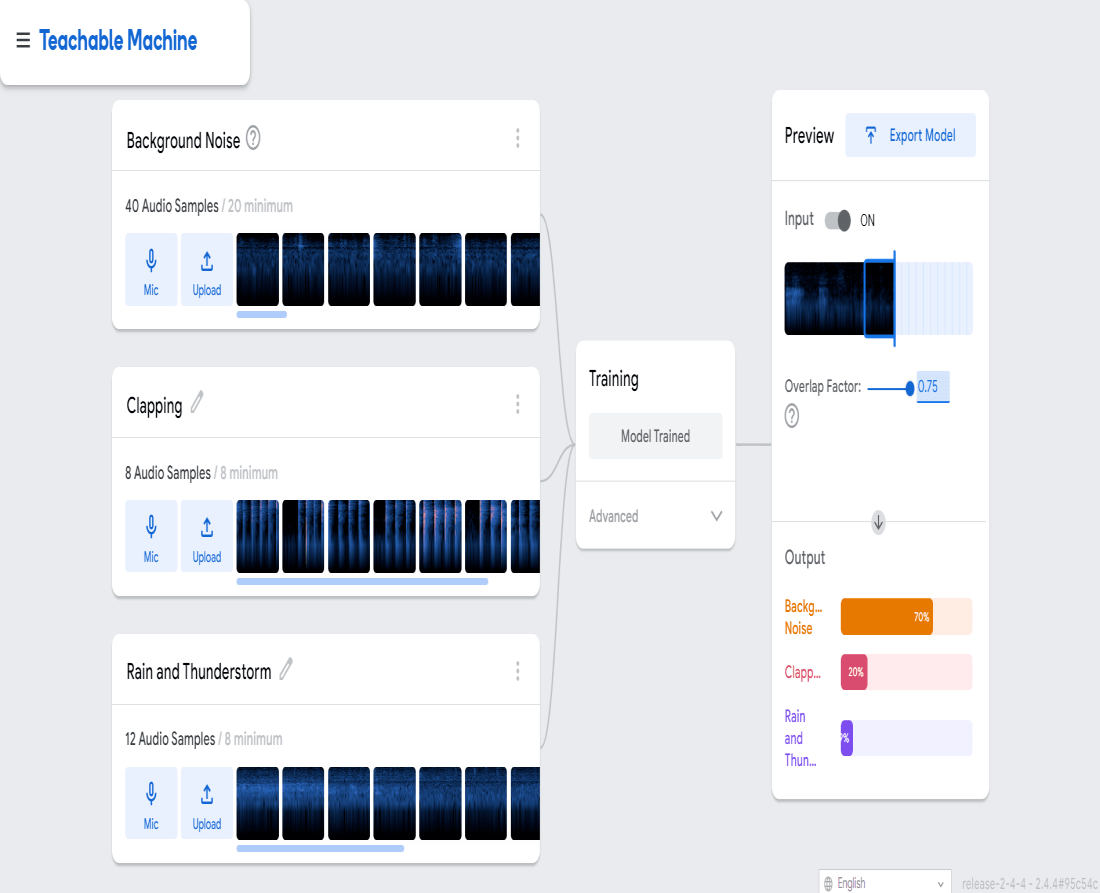
音频模型
为了创建一个检测声音的模型,我们将创建一个音频项目。我们创建了三个类——背景噪声、拍手声、雨声和雷暴。训练模型后,在预览部分,我们使用噪声来测试模型效率。在预览的输出中,我们可以看到背景噪声的百分比更高。为了使模型更高效,我们需要添加数千个样本,以便更好地从数据中学习模型。