- 机器学习教程(1)
- 机器学习教程(1)
- 使用Python机器学习的教程
- 使用Python机器学习的教程(1)
- 机器学习js教程——Javascript代码示例
- C++中的机器学习(1)
- C++中的机器学习
- 机器学习中的 P 值
- 机器学习 (1)
- 机器学习中的 P 值(1)
- 机器学习 python (1)
- 学习F#教程
- 学习F#教程(1)
- 机器学习 python 代码示例
- 机器学习 - 任何代码示例
- 机器学习-什么是P值
- 什么是机器学习?
- 什么是机器学习?(1)
- 机器学习-什么是P值(1)
- 在机器学习中什么是“i” (1)
- 学习 python 机器学习 - 任何代码示例
- 机器学习-什么是机器学习? -指导点
- 机器学习-什么是机器学习? -指导点(1)
- 学习PHP教程(1)
- 学习PHP教程
- 机器学习算法
- 机器学习算法(1)
- 使用Python机器学习-方法
- 使用Python机器学习-方法(1)
📅 最后修改于: 2020-09-26 13:58:44 🧑 作者: Mango
机器学习教程
![]()
机器学习教程提供了机器学习的基本和高级概念。我们的机器学习教程专为学生和工作专业人士设计。
机器学习是一项正在发展的技术,它使计算机能够从过去的数据中自动学习。机器学习使用各种算法来构建数学模型并使用历史数据或信息进行预测。当前,它被用于各种任务,例如图像识别,语音识别,电子邮件过滤,Facebook自动标记,推荐系统等等。
本机器学习教程为您介绍了机器学习以及各种机器学习技术,例如监督学习,无监督学习和强化学习。您将了解回归和分类模型,聚类方法,隐马尔可夫模型以及各种顺序模型。
什么是机器学习
在现实世界中,我们周围都是人,他们可以通过他们的学习能力学习所有东西,并且我们拥有可以按照指令工作的计算机或机器。但是,机器还能像人类一样从经验或过去的数据中学习吗?因此,这就是机器学习的作用。

据说机器学习是人工智能的一个子集,主要涉及算法的开发,这些算法使计算机可以自行学习数据和过去的经验。机器学习一词由Arthur Samuel于1959年首次提出。我们可以将其概括地定义为:
机器学习使机器无需显式编程即可自动从数据中学习,从体验中提高性能以及预测事物。
借助样本历史数据(称为训练数据),机器学习算法可以建立数学模型,帮助您进行预测或决策而无需进行显式编程。机器学习将计算机科学和统计学结合在一起,以创建预测模型。机器学习构造或使用从历史数据中学习的算法。我们提供的信息越多,性能就越高。
一台机器具有学习是否可以通过获取更多数据来提高其性能的能力。
机器学习如何工作
机器学习系统从历史数据中学习,建立预测模型,并且每当接收到新数据时,就为其预测输出。预测输出的准确性取决于数据量,因为大量数据有助于建立更好的模型,从而更准确地预测输出。
假设我们有一个复杂的问题,我们需要执行一些预测,因此无需为它编写代码,我们只需将数据输入通用算法即可,并在这些算法的帮助下,按照数据并预测输出。机器学习已经改变了我们对问题的思考方式。下面的框图说明了机器学习算法的工作原理:
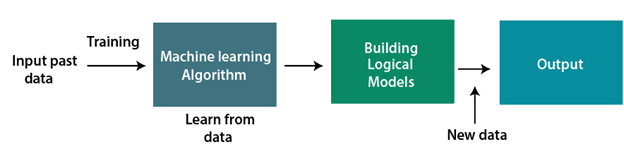
机器学习的特点:
- 机器学习使用数据来检测给定数据集中的各种模式。
- 它可以从过去的数据中学习并自动改进。
- 它是一种数据驱动的技术。
- 机器学习与数据挖掘非常相似,因为它还处理大量数据。
机器学习的需要
机器学习的需求日益增长。之所以需要机器学习,是因为它能够执行过于复杂的任务,以至于无法直接实现。作为一个人类,我们由于无法手动访问大量数据而受到一些限制,因此,为此,我们需要一些计算机系统,并且通过机器学习来简化我们的工作。
我们可以为机器学习算法提供大量数据,然后让他们探索数据,构建模型并自动预测所需的输出,从而训练机器学习算法。机器学习算法的性能取决于数据量,并且可以由成本函数确定。借助机器学习,我们可以节省时间和金钱。
机器学习的重要性可以通过其用例轻松理解。目前,机器学习已用于自动驾驶汽车,网络欺诈检测,面部识别和Facebook的好友建议等。Netflix和Amazon等多家顶级公司都拥有建立使用大量数据来分析用户兴趣并相应推荐产品的机器学习模型。
以下是显示机器学习重要性的一些关键点:
- 快速增加数据量
- 解决人类难以解决的复杂问题
- 包括金融在内的各个部门的决策
- 查找隐藏的模式并从数据中提取有用的信息。
机器学习分类
从广义上讲,机器学习可以分为三种类型:
- 监督学习
- 无监督学习
- 强化学习
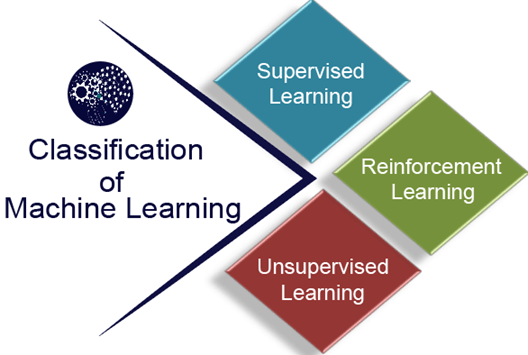
1)监督学习
监督学习是一种机器学习方法,在这种方法中,我们向机器学习系统提供了带有标签的样本数据以对其进行训练,并在此基础上预测输出。
该系统使用标记的数据创建一个模型,以理解数据集并了解每个数据,一旦训练和处理完成,我们将通过提供样本数据来检查模型,以检查其是否预测了准确的输出。
监督学习的目标是将输入数据与输出数据进行映射。监督学习是基于监督的,它与学生在老师的监督下学习事物时相同。监督学习的示例是垃圾邮件过滤。
监督学习可以进一步分为两类算法:
- 分类
- 回归
2)无监督学习
无监督学习是一种机器无需任何监督即可学习的学习方法。
训练是通过未标记,分类或分类的数据集提供给机器的,算法需要对该数据进行操作而无需任何监督。无监督学习的目的是将输入数据重组为新特征或具有相似模式的一组对象。
在无监督学习中,我们没有预定的结果。机器尝试从大量数据中找到有用的见解。可以将其进一步分为两类算法:
- 聚类
- 协会
3)强化学习
强化学习是一种基于反馈的学习方法,其中学习代理为每个正确的行为获得奖励,并为每个错误的行为获得惩罚。代理会根据这些反馈自动学习并提高其性能。在强化学习中,主体与环境互动并对其进行探索。代理的目标是获得最大的奖励积分,因此可以提高其绩效。
自动学习狗手臂运动的机器狗是强化学习的一个例子。
注意:我们将在后面的章节中详细了解上述机器学习类型。
机器学习的历史
几年前(大约40至50年),机器学习是科幻小说,但今天它已成为我们日常生活的一部分。机器学习使我们的日常工作变得轻松,从无人驾驶汽车到亚马逊虚拟助手“ Alexa”。但是,机器学习背后的思想太古老了,历史悠久。下面给出了机器学习历史中发生的一些里程碑:
机器学习的早期历史(1940年前):
- 1834年: 1834年,计算机之父查尔斯·巴贝奇(Charles Babbage)构思了一种可以用打孔卡编程的设备。但是,该机器从未被制造过,而是所有现代计算机都依赖于其逻辑结构。
- 1936年: 1936年,艾伦·图灵(Alan Turing)提出了一种理论,即机器如何确定并执行一组指令。
存储程序计算机的时代:
- 1940年: 1940年,发明了第一台手动计算机“ ENIAC”,这是第一台电子通用计算机。之后,发明了存储程序计算机,例如1949年的EDSAC和1951年的EDVAC。
- 1943年: 1943年,用电路为人类神经网络建模。 1950年,科学家开始将他们的想法应用到工作中,并分析了人类神经元如何工作。
计算机机械与智能:
- 1950年: 1950年,艾伦·图灵(Alan Turing)发表了有关人工智能的开创性论文“ 计算机技术与智能 “。 他在论文中问:“机器可以思考吗?”
游戏中的机器智能:
- 1952年:机器学习的先驱Arthur Samuel创建了一个程序,该程序帮助IBM计算机玩跳棋游戏。它的演奏表现更好。
- 1959年: 1959年,“机器学习”一词由Arthur Samuel首次提出。
第一个“ AI”冬季:
- 1974年至1980年是AI和ML研究人员的艰难时期,这一时期被称为AI冬季 。
- 在这段时间内,机器翻译失败,人们对AI的兴趣减少了,这导致政府对研究的资金减少。
从理论到现实的机器学习
- 1959年: 1959年,第一个神经网络应用于实际问题,以使用自适应滤波器消除电话线上的回声。
- 1985年: 1985年,特里· 塞诺夫斯基 (Terry Sejnowski)和查尔斯·罗森伯格(Charles Rosenberg)发明了神经网络NETtalk ,该网络能够教自己如何在一周内正确发音20,000个单词。
- 1997年: IBM的Deep blue智能计算机在国际象棋专家加里·卡斯帕罗夫(Garry Kasparov)的国际象棋比赛中胜出,成为第一台击败人类国际象棋专家的计算机。
21世纪的机器学习
- 2006年: 2006年,计算机科学家Geoffrey Hinton将神经网络研究的新名称称为“ 深度学习 “,如今,它已成为最流行的技术之一。
- 2012年: 2012年,Google创建了一个深度神经网络,该网络学会了识别YouTube视频中人和猫的图像。
- 2014年: 2014年,Chabot机器人“ Eugen Goostman “通过了图灵测试。这是第一个让33%的人类判断者相信它不是机器的Chabot。
- 2014年: DeepFace是Facebook创建的一个深度神经网络,他们声称它可以像人一样精确地识别一个人。
- 2016年: AlphaGo在围棋比赛中击败了世界第二大选手李·塞多尔 。在2017年,它击败了该游戏的第一名柯杰 。
- 2017年: 2017年,Alphabet的拼图团队构建了一个智能系统,该系统能够学习在线拖钓 。它曾经阅读过数百万个不同网站的评论,以学习停止在线拖钓。
目前的机器学习:
现在,机器学习的研究取得了长足的进步,无所不在,例如无人驾驶汽车,亚马逊Alexa,Catboats,推荐系统等等。它包括带聚类,分类,决策树,SVM算法等的有监督,无监督和强化学习。
现代机器学习模型可用于做出各种预测,包括天气预报,疾病预测,股票市场分析等。
先决条件
在学习机器学习之前,您必须具有以下基本知识,以便您可以轻松理解机器学习的概念:
- 概率和线性代数的基础知识。
- 可以使用任何计算机语言(尤其是Python语言)进行编码的能力。
- 微积分知识,尤其是单变量和多元函数的导数。
听众
我们的机器学习教程旨在帮助初学者和专业人士。
问题
我们向您保证,在学习我们的机器学习教程时不会遇到任何困难。但是,如果本教程中有任何错误,请将问题或错误张贴在联系表中,以便我们进行改进。