毫升 |模型得分和错误
在机器学习中,主要任务之一是使用各种分类和回归算法对数据进行建模并预测输出。但是由于算法太多,要选择哪一个来预测最终数据真的很困难。因此,我们需要比较我们的模型并选择准确率最高的模型。
使用 sklearn 库,我们可以找出我们的 ML 模型的分数,从而选择具有更高分数的算法来预测我们的输出。另一个好方法是计算误差,例如平均绝对误差和均方误差,并尝试将它们最小化以改进我们的模型。
平均绝对误差(MAE) : 它是所有绝对误差的平均值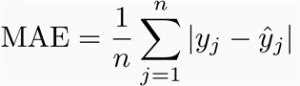
均方误差 (MSE)它是所有误差的平方均值。 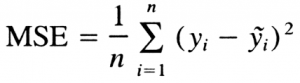
在这里,我们使用 Titanic 数据集作为分类问题的输入,并仅使用逻辑回归和 KNN 对我们的数据进行建模。虽然,您也可以使用其他算法进行建模。你可以在这里找到数据集
# importing libraries
import numpy as np
import sklearn
from sklearn import metrics
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
data = pd.read_csv("gfg_data")
x = data[['Pclass', 'Sex', 'Age', 'Parch', 'Embarked', 'Fare',
'Has_Cabin', 'FamilySize', 'title', 'IsAlone']]
y = data[['Survived']]
X_train, X_test, Y_train, Y_test = train_test_split(x, y,
test_size = 0.3, random_state = None)
# logistic Regression
lr = LogisticRegression()
lr.fit(X_train, Y_train)
Y_pred = lr.predict(X_test)
LogReg = round(lr.score(X_test, Y_test), 2)
mae_lr = round(metrics.mean_absolute_error(Y_test, Y_pred), 4)
mse_lr = round(metrics.mean_squared_error(Y_test, Y_pred), 4)
# KNN
knn = KNeighborsClassifier(n_neighbors = 2)
knn.fit(X_train, Y_train)
Y_pred = knn.predict(X_test)
KNN = round(knn.score(X_test, Y_test), 2)
mae_knn = metrics.mean_absolute_error(Y_test, Y_pred)
mse_knn = metrics.mean_squared_error(Y_test, Y_pred)
compare_models = pd.DataFrame(
{ 'Model' : ['LogReg', 'KNN'],
'Score' : [LogReg, KNN],
'MAE' : [mae_lr, mae_knn],
'MSE' : [mse_lr, mse_knn]
})
print(compare_models)
输出: 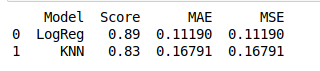
我们现在可以查看模型的得分和误差并进行比较。 Logistic Regression 的分数大于 KNN,误差也较小。因此,逻辑回归将是我们模型的正确选择。