在 PySpark 数据框中显示不同的列值
在本文中,我们将使用Python的pyspark 显示来自数据帧的不同列值。为此,我们使用了 distinct() 和 dropDuplicates() 函数以及 select()函数。
让我们创建一个示例数据框。
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data with 5 row values
data =[["1", "sravan", "company 1"],
["3", "bobby", "company 3"],
["2", "ojaswi", "company 2"],
["1", "sravan", "company 1"],
["3", "bobby", "company 3"],
["4", "rohith", "company 2"],
["5", "gnanesh", "company 1"]]
# specify column names
columns = ['Employee ID','Employee NAME','Company Name']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data,columns)
dataframe.show()Python3
# select first column to get
# unique data using distinct function()
dataframe.select("Employee ID").distinct().show()Python3
# select first and second column
# to get unique data using distinct function()
dataframe.select(["Employee ID",
"Employee NAME"]).distinct().show()Python3
#select first column to get
# unique data using dropDuplicates function()
dataframe.select("Employee ID").dropDuplicates().show()Python3
#select first and second column
# to get unique data using dropDuplicates function()
dataframe.select(["Employee ID",
"Employee NAME"]).dropDuplicates().show()输出:
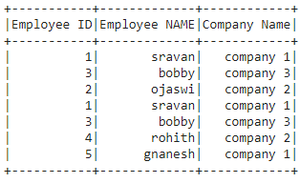
方法一:使用distinct()
此函数使用 distinct()函数从列返回不同的值。
Syntax: dataframe.select(“column_name”).distinct().show()
示例 1:对于单个列。
蟒蛇3
# select first column to get
# unique data using distinct function()
dataframe.select("Employee ID").distinct().show()
输出:
+-----------+
|Employee ID|
+-----------+
| 3|
| 5|
| 1|
| 4|
| 2|
+-----------+示例 2:对于多列。
使用 distinct()函数显示 2 列中的唯一数据的Python代码。
Syntax: dataframe.select(“column_name 1, column_name 2 “).distinct().show()
代码:
蟒蛇3
# select first and second column
# to get unique data using distinct function()
dataframe.select(["Employee ID",
"Employee NAME"]).distinct().show()
输出:
+-----------+-------------+
|Employee ID|Employee NAME|
+-----------+-------------+
| 5| gnanesh|
| 4| rohith|
| 1| sravan|
| 2| ojaswi|
| 3| bobby|
+-----------+-------------+方法 2:使用 dropDuplicates()
此函数使用 dropDuplicates()函数在数据框中的一列中显示唯一数据。
Syntax: dataframe.select(“column_name”).dropDuplicates().show()
示例 1:对于单列。
蟒蛇3
#select first column to get
# unique data using dropDuplicates function()
dataframe.select("Employee ID").dropDuplicates().show()
输出:
+-----------+
|Employee ID|
+-----------+
| 3|
| 5|
| 1|
| 4|
| 2|
+-----------+示例 2:对于多列
使用 dropDuplicates()函数显示来自 2 列的唯一数据的Python代码
蟒蛇3
#select first and second column
# to get unique data using dropDuplicates function()
dataframe.select(["Employee ID",
"Employee NAME"]).dropDuplicates().show()
输出:
+-----------+-------------+
|Employee ID|Employee NAME|
+-----------+-------------+
| 5| gnanesh|
| 4| rohith|
| 1| sravan|
| 2| ojaswi|
| 3| bobby|
+-----------+-------------+