在 PySpark 数据框中选择列
在本文中,我们将学习如何在 PySpark 数据框中选择列。
使用的函数:
在 PySpark 中,我们可以使用select()函数选择列。 select()函数允许我们选择不同格式的单列或多列。
Syntax: dataframe_name.select( columns_names )
注意:我们正在使用findspark.init()函数指定我们的 spark 目录路径,以使我们的程序能够在我们的本地机器中找到 apache spark 的位置。如果您在云上运行程序,请忽略此行。假设我们在 c 驱动器中有我们的 spark 文件夹,名称为 spark,所以函数看起来像: findspark.init('c:/spark') 。在本地运行程序时,不指定路径有时可能会导致py4j.protocol.Py4JError错误。
示例 1:选择单列或多列
我们可以使用 select()函数通过指定特定的列名来选择单个或多个列。这里我们使用我们的自定义数据集,因此我们需要连同它一起指定我们的模式以创建数据集。
Python3
# select single and multiple columns
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType
from pyspark.sql import SparkSession
import findspark
findspark.init('c:/spark')
# Initialize our data
data2 = [("Pulkit", 12, "CS32", 82, "Programming"),
("Ritika", 20, "CS32", 94, "Writing"),
("Atirikt", 4, "BB21", 78, None),
("Reshav", 18, None, 56, None)
]
# Start spark session
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
# Define schema
schema = StructType([
StructField("Name", StringType(), True),
StructField("Roll Number", IntegerType(), True),
StructField("Class ID", StringType(), True),
StructField("Marks", IntegerType(), True),
StructField("Extracurricular", StringType(), True)
])
# read the dataframe
df = spark.createDataFrame(data=data2, schema=schema)
# slelct columns
df.select("Name", "Marks").show()
# stop the session
spark.stop()Python3
from pyspark.sql.functions import col
df.select(col("Name"),col("Marks")).show()Python3
# select spark
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType
from pyspark.sql import SparkSession
import findspark
findspark.init('c:/spark')
# Initialize our data
data2 = [("Pulkit", 12, "CS32", 82, "Programming"),
("Ritika", 20, "CS32", 94, "Writing"),
("Atirikt", 4, "BB21", 78, None),
("Reshav", 18, None, 56, None)
]
# Start spark session
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
# Define schema
schema = StructType([
StructField("Name", StringType(), True),
StructField("Roll Number", IntegerType(), True),
StructField("Class ID", StringType(), True),
StructField("Marks", IntegerType(), True),
StructField("Extracurricular", StringType(), True)
])
# read the dataframe
df = spark.createDataFrame(data=data2, schema=schema)
# select the columns
df.select(df.columns[:4]).show()
# stop session
spark.stop()Python3
# findspark
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType
from pyspark.sql import SparkSession
import findspark
findspark.init('c:/spark')
# initialize the data
data = [
(("Pulkit", "Dhingra"), 12, "CS32", 82, "Programming"),
(("Ritika", "Pandey"), 20, "CS32", 94, "Writing"),
(("Atirikt", "Sans"), 4, "BB21", 78, None),
(("Reshav", None), 18, None, 56, None)
]
# start spark session
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
# initialize the schema of the data
schema = StructType([
StructField('name', StructType([
StructField('firstname', StringType(), True),
StructField('lastname', StringType(), True)
])),
StructField("Roll Number", IntegerType(), True),
StructField("Class ID", StringType(), True),
StructField("Marks", IntegerType(), True),
StructField("Extracurricular", StringType(), True)
])
# create a dataframe
df2 = spark.createDataFrame(data=data, schema=schema)
# display the schema
df2.printSchema()
# select operation
df2.select("name.firstname", "name.lastname").show(truncate=False)
# stop session
spark.stop()输出:

注意:有很多方法可以为 select()函数指定列名。这里我们使用“column_name”来指定列。其他方式包括(所有示例均参考上述代码):
- df.select(df.Name,df.Marks)
- df.select(df[“名称”],df[“标记”])
- 我们可以使用 pyspark.sql.functions 模块中的 col()函数来指定特定的列
蟒蛇3
from pyspark.sql.functions import col
df.select(col("Name"),col("Marks")).show()
注意:以上所有方法都会产生与上面相同的输出
示例 2:使用索引选择列
索引提供了一种访问数据帧内列的简单方法。索引从 0 开始,总共有 n-1 个数字代表每列,0 作为第一列,n-1 作为最后的第 n 列。我们可以使用 df.columns 访问所有列,并使用索引在 select函数传入所需的列。下面是代码的样子。我们正在使用我们的自定义数据集,因此我们需要连同它一起指定我们的模式以创建数据集。
蟒蛇3
# select spark
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType
from pyspark.sql import SparkSession
import findspark
findspark.init('c:/spark')
# Initialize our data
data2 = [("Pulkit", 12, "CS32", 82, "Programming"),
("Ritika", 20, "CS32", 94, "Writing"),
("Atirikt", 4, "BB21", 78, None),
("Reshav", 18, None, 56, None)
]
# Start spark session
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
# Define schema
schema = StructType([
StructField("Name", StringType(), True),
StructField("Roll Number", IntegerType(), True),
StructField("Class ID", StringType(), True),
StructField("Marks", IntegerType(), True),
StructField("Extracurricular", StringType(), True)
])
# read the dataframe
df = spark.createDataFrame(data=data2, schema=schema)
# select the columns
df.select(df.columns[:4]).show()
# stop session
spark.stop()
输出:

示例 3:访问数据框的嵌套列
在创建数据框时,可能有一个表格,我们在其中嵌套了列,例如,在列名称“标记”中,我们可能有内部或外部标记的子列,或者我们可能有单独的列用于第一个中间名和姓氏名称下的列。为了使用 select()函数访问数据帧内的嵌套列,我们可以指定具有关联列的子列。这里我们使用我们的自定义数据集,因此我们需要连同它一起指定我们的模式以创建数据集。
蟒蛇3
# findspark
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType
from pyspark.sql import SparkSession
import findspark
findspark.init('c:/spark')
# initialize the data
data = [
(("Pulkit", "Dhingra"), 12, "CS32", 82, "Programming"),
(("Ritika", "Pandey"), 20, "CS32", 94, "Writing"),
(("Atirikt", "Sans"), 4, "BB21", 78, None),
(("Reshav", None), 18, None, 56, None)
]
# start spark session
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
# initialize the schema of the data
schema = StructType([
StructField('name', StructType([
StructField('firstname', StringType(), True),
StructField('lastname', StringType(), True)
])),
StructField("Roll Number", IntegerType(), True),
StructField("Class ID", StringType(), True),
StructField("Marks", IntegerType(), True),
StructField("Extracurricular", StringType(), True)
])
# create a dataframe
df2 = spark.createDataFrame(data=data, schema=schema)
# display the schema
df2.printSchema()
# select operation
df2.select("name.firstname", "name.lastname").show(truncate=False)
# stop session
spark.stop()
输出:
在这里我们可以看到我们有一个以下模式的数据集
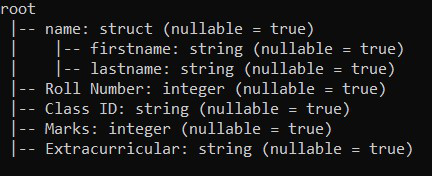
我们有一个列名,子列作为名字和姓氏。现在,当我们执行选择操作时,我们有一个输出,如
