从 PySpark 数据框中获取特定行
在本文中,我们将讨论如何从 PySpark 数据框中获取特定行。
创建用于演示的数据框:
Python3
# importing module
import pyspark
# importing sparksession
# from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession
# and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data with 5 row values
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 2"],
["3", "bobby", "company 3"],
["4", "rohith", "company 2"],
["5", "gnanesh", "company 1"]]
# specify column names
columns = ['Employee ID', 'Employee NAME',
'Company Name']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# display dataframe
dataframe.show()Python3
# get first row
print(dataframe.collect()[0])
# get second row
print(dataframe.collect()[1])
# get last row
print(dataframe.collect()[-1])
# get third row
print(dataframe.collect()[2])Python3
# display dataframe only top 2 rows
print(dataframe.show(2))
# display dataframe only top 1 row
print(dataframe.show(1))
# display dataframe
print(dataframe.show())Python3
# display first row of the dataframe
print(dataframe.first())Python3
# display only 1 row
print(dataframe.head(1))
# display only top 3 rows
print(dataframe.head(3))
# display only top 2 rows
print(dataframe.head(2))Python3
# display only 1 row from last
print(dataframe.tail(1))
# display only top 3 rows from last
print(dataframe.tail(3))
# display only top 2 rows from last
print(dataframe.tail(2))Python3
# select first row
print(dataframe.select(['Employee ID',
'Employee NAME',
'Company Name']).collect()[0])
# select third row
print(dataframe.select(['Employee ID',
'Employee NAME',
'Company Name']).collect()[2])
# select forth row
print(dataframe.select(['Employee ID',
'Employee NAME',
'Company Name']).collect()[3])Python3
# select top 2 rows
print(dataframe.take(2))
# select top 4 rows
print(dataframe.take(4))
# select top 1 row
print(dataframe.take(1))输出:
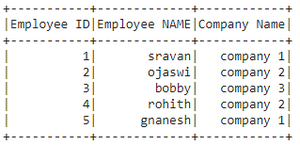
方法 1:使用 collect()
这用于以列表格式从数据框中获取所有行的数据。
Syntax: dataframe.collect()[index_position]
Where,
- dataframe is the pyspark dataframe
- index_position is the index row in dataframe
示例:访问行的Python代码
蟒蛇3
# get first row
print(dataframe.collect()[0])
# get second row
print(dataframe.collect()[1])
# get last row
print(dataframe.collect()[-1])
# get third row
print(dataframe.collect()[2])
输出:
Row(Employee ID=’1′, Employee NAME=’sravan’, Company Name=’company 1′)
Row(Employee ID=’2′, Employee NAME=’ojaswi’, Company Name=’company 2′)
Row(Employee ID=’5′, Employee NAME=’gnanesh’, Company Name=’company 1′)
Row(Employee ID=’3′, Employee NAME=’bobby’, Company Name=’company 3′)
方法 2:使用 show()
此函数用于从 pyspark 数据框中获取前 n 行。
Syntax: dataframe.show(no_of_rows)
where, no_of_rows is the row number to get the data
示例:使用 show()函数获取数据的Python代码
蟒蛇3
# display dataframe only top 2 rows
print(dataframe.show(2))
# display dataframe only top 1 row
print(dataframe.show(1))
# display dataframe
print(dataframe.show())
输出:

方法 3:使用 first()
此函数用于仅返回数据帧中的第一行。
Syntax: dataframe.first()
示例:用于选择数据框中第一行的Python代码。
蟒蛇3
# display first row of the dataframe
print(dataframe.first())
输出:
Row(Employee ID=’1′, Employee NAME=’sravan’, Company Name=’company 1′)
方法 4:使用 head()
此方法用于显示数据框中的前 n 行。
Syntax: dataframe.head(n)
where, n is the number of rows to be displayed
示例:显示要显示的行数的Python代码。
蟒蛇3
# display only 1 row
print(dataframe.head(1))
# display only top 3 rows
print(dataframe.head(3))
# display only top 2 rows
print(dataframe.head(2))
输出:
[Row(Employee ID=’1′, Employee NAME=’sravan’, Company Name=’company 1′)]
[Row(Employee ID=’1′, Employee NAME=’sravan’, Company Name=’company 1′),
Row(Employee ID=’2′, Employee NAME=’ojaswi’, Company Name=’company 2′),
Row(Employee ID=’3′, Employee NAME=’bobby’, Company Name=’company 3′)]
[Row(Employee ID=’1′, Employee NAME=’sravan’, Company Name=’company 1′),
Row(Employee ID=’2′, Employee NAME=’ojaswi’, Company Name=’company 2′)]
方法五:使用tail()
用于返回数据框中的最后 n 行
Syntax: dataframe.tail(n)
where n is the no of rows to be returned from last in the dataframe.
示例:获取最后 n 行的Python代码
蟒蛇3
# display only 1 row from last
print(dataframe.tail(1))
# display only top 3 rows from last
print(dataframe.tail(3))
# display only top 2 rows from last
print(dataframe.tail(2))
输出:
[Row(Employee ID=’5′, Employee NAME=’gnanesh’, Company Name=’company 1′)]
[Row(Employee ID=’3′, Employee NAME=’bobby’, Company Name=’company 3′),
Row(Employee ID=’4′, Employee NAME=’rohith’, Company Name=’company 2′),
Row(Employee ID=’5′, Employee NAME=’gnanesh’, Company Name=’company 1′)]
[Row(Employee ID=’4′, Employee NAME=’rohith’, Company Name=’company 2′),
Row(Employee ID=’5′, Employee NAME=’gnanesh’, Company Name=’company 1′)]
方法 6:使用 select() 和 collect() 方法
此方法用于从数据框中选择特定行,它可以与 collect()函数。
Syntax: dataframe.select([columns]).collect()[index]
where,
- dataframe is the pyspark dataframe
- Columns is the list of columns to be displayed in each row
- Index is the index number of row to be displayed.
示例:选择特定行的Python代码。
蟒蛇3
# select first row
print(dataframe.select(['Employee ID',
'Employee NAME',
'Company Name']).collect()[0])
# select third row
print(dataframe.select(['Employee ID',
'Employee NAME',
'Company Name']).collect()[2])
# select forth row
print(dataframe.select(['Employee ID',
'Employee NAME',
'Company Name']).collect()[3])
输出:
Row(Employee ID=’1′, Employee NAME=’sravan’, Company Name=’company 1′)
Row(Employee ID=’3′, Employee NAME=’bobby’, Company Name=’company 3′)
Row(Employee ID=’4′, Employee NAME=’rohith’, Company Name=’company 2′)
方法七:使用 take() 方法
此方法也用于选择前 n 行
Syntax: dataframe.take(n)
where n is the number of rows to be selected
蟒蛇3
# select top 2 rows
print(dataframe.take(2))
# select top 4 rows
print(dataframe.take(4))
# select top 1 row
print(dataframe.take(1))
输出:
[Row(Employee ID=’1′, Employee NAME=’sravan’, Company Name=’company 1′),
Row(Employee ID=’2′, Employee NAME=’ojaswi’, Company Name=’company 2′)]
[Row(Employee ID=’1′, Employee NAME=’sravan’, Company Name=’company 1′),
Row(Employee ID=’2′, Employee NAME=’ojaswi’, Company Name=’company 2′),
Row(Employee ID=’3′, Employee NAME=’bobby’, Company Name=’company 3′),
Row(Employee ID=’4′, Employee NAME=’rohith’, Company Name=’company 2′)]
[Row(Employee ID=’1′, Employee NAME=’sravan’, Company Name=’company 1′)]