人工智能中的搜索算法
人工智能是对构建理性行为的代理的研究。大多数时候,这些代理在后台执行某种搜索算法以完成它们的任务。
- 搜索问题包括:
- 状态空间。设置所有可能的状态。
- 一个开始状态。搜索开始的状态。
- 目标测试。查看当前状态的函数返回它是否是目标状态。
- 搜索问题的解决方案是一系列动作,称为将开始状态转换为目标状态的计划。
- 这个计划是通过搜索算法实现的。
搜索算法的类型:
有太多强大的搜索算法可以放在一篇文章中。相反,本文将讨论六种基本搜索算法,分为两类,如下所示。
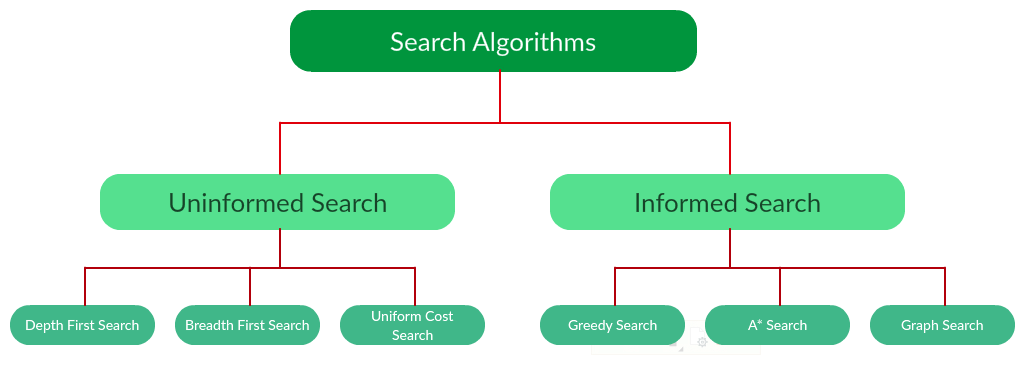
请注意,搜索算法比我上面提供的图表要多得多。然而,本文将主要坚持上面的图表,探索那里给出的算法。
不知情的搜索算法:
本节中的搜索算法除了问题定义中提供的信息外,没有关于目标节点的其他信息。从开始状态达到目标状态的计划仅在动作的顺序和/或长度上有所不同。不知情的搜索也称为盲搜索。
本节将讨论以下不知情的搜索算法。
- 深度优先搜索
- 广度优先搜索
- 统一成本搜索
这些算法中的每一个都将具有:
- 一个问题图,包含起始节点 S 和目标节点 G。
- 一种策略,描述遍历图到达 G 的方式。
- 边缘,这是一种数据结构,用于存储您可以从当前状态进入的所有可能状态(节点)。
- 一棵树,在遍历目标节点时产生。
- 一个解决方案,它的节点序列从 S 到 G。
深度优先搜索:
深度优先搜索 (DFS) 是一种用于遍历或搜索树或图数据结构的算法。该算法从根节点开始(在图的情况下选择某个任意节点作为根节点)并在回溯之前沿着每个分支尽可能地探索。
例子:
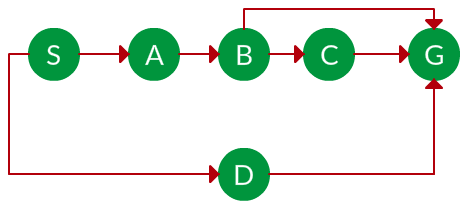
题。如果在下图中运行,DFS 会发现哪种解决方案从节点 S 移动到节点 G?
解决方案。上图的等效搜索树如下。当 DFS “最深节点优先”遍历树时,它总是会选择更深的分支,直到它到达解决方案(或者它用完节点,然后转到下一个分支)。遍历显示为蓝色箭头。
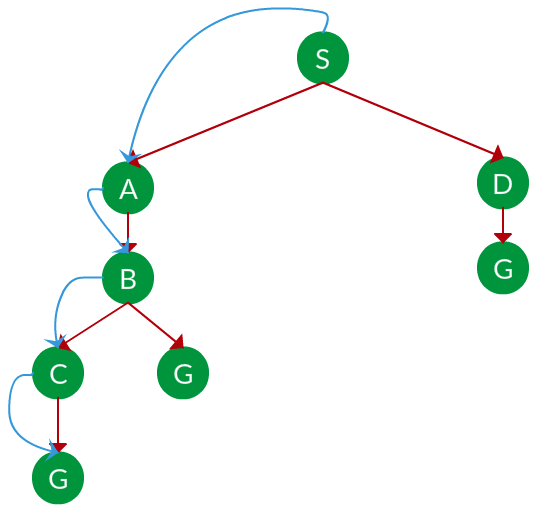
路径: S -> A -> B -> C -> G
 = the depth of the search tree = the number of levels of the search tree.
= the depth of the search tree = the number of levels of the search tree. = number of nodes in level
 .
.
Time complexity: Equivalent to the number of nodes traversed in DFS.
Space complexity: Equivalent to how large can the fringe get.
Completeness: DFS is complete if the search tree is finite, meaning for a given finite search tree, DFS will come up with a solution if it exists.
Optimality: DFS is not optimal, meaning the number of steps in reaching the solution, or the cost spent in reaching it is high.
广度优先搜索:
广度优先搜索 (BFS) 是一种用于遍历或搜索树或图数据结构的算法。它从树根(或图的某个任意节点,有时称为“搜索键”)开始,并在移动到下一个深度级别的节点之前探索当前深度的所有相邻节点。
例子:
题。如果在下图中运行,BFS 会发现哪种解决方案从节点 S 移动到节点 G?
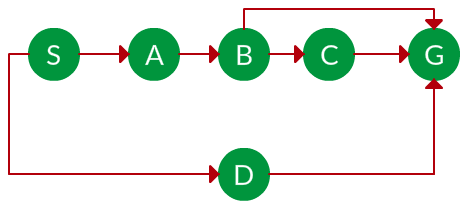
解决方案。上图的等效搜索树如下。当 BFS “最浅节点优先”遍历树时,它总是会选择较浅的分支,直到它到达解决方案(或者它用完节点,然后转到下一个分支)。遍历显示为蓝色箭头。
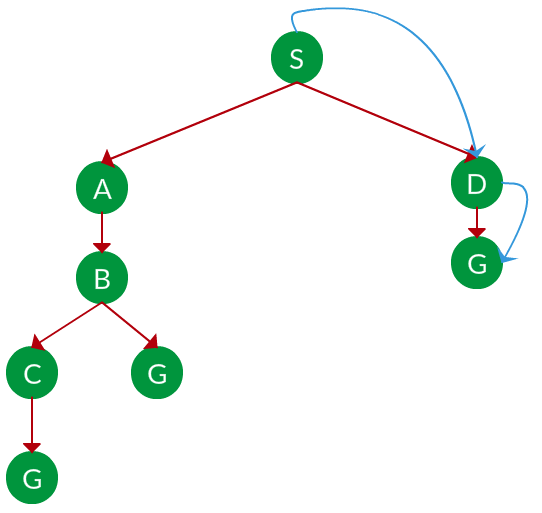
路径: S -> D -> G
= the depth of the shallowest solution.
= number of nodes in level
 .
.
Time complexity: Equivalent to the number of nodes traversed in BFS until the shallowest solution. 
Space complexity: Equivalent to how large can the fringe get.
Completeness: BFS is complete, meaning for a given search tree, BFS will come up with a solution if it exists.
Optimality: BFS is optimal as long as the costs of all edges are equal.
统一成本搜索:
UCS 与 BFS 和 DFS 不同,因为在这里成本开始发挥作用。换句话说,通过不同的边遍历可能不会有相同的成本。目标是找到一条总成本最小的路径。
一个节点的成本定义为:
cost(node) = cumulative cost of all nodes from root
cost(root) = 0例子:
题。如果在下图中运行,UCS 会发现哪种解决方案从节点 S 移动到节点 G?
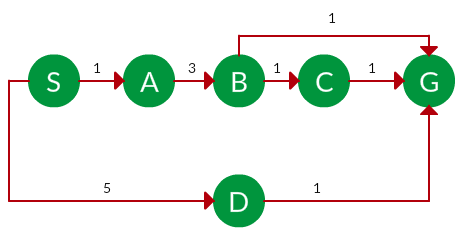
解决方案。上图的等效搜索树如下。每个节点的成本是从根到达该节点的累积成本。基于UCS策略,选择累积成本最小的路径。请注意,由于边缘选项众多,算法会探索其中的大部分,只要它们的成本较低,并在找到成本较低的路径时将其丢弃;下面没有显示这些丢弃的遍历。实际遍历显示为蓝色。

路径: S -> A -> B -> G
费用: 5
让 = 解决方案的成本。
= 解决方案的成本。 =弧线成本。
然后有效深度
时间复杂度:
空间复杂度:
优点:
- 只有当状态是有限的并且不应该有零权重的循环时,UCS 才是完整的。
- 只有在没有负成本的情况下,UCS 才是最优的。
缺点:
- 探索每个“方向”的选项。
- 没有关于目标位置的信息。
知情搜索算法:
在这里,算法有关于目标状态的信息,这有助于更有效的搜索。该信息是通过一种称为启发式的方法获得的。
在本节中,我们将讨论以下搜索算法。
- 贪婪搜索
- A* 树搜索
- A* 图形搜索
搜索启发式:在知情搜索中,启发式是一种估计状态与目标状态的接近程度的函数。例如——曼哈顿距离、欧几里得距离等(距离越小,目标越近。)在下面讨论的不同知情算法中使用了不同的启发式方法。
贪婪搜索:
在贪心搜索中,我们展开离目标节点最近的节点。 “接近度”由启发式 h(x) 估计。
启发式:启发式 h 定义为-
h(x) = 估计节点 x 到目标节点的距离。
h(x) 的值越小,离目标的节点越近。
策略:展开离目标状态最近的节点,即展开h值较低的节点。
例子:
题。使用贪心搜索找到从 S 到 G 的路径。节点名称下方的每个节点的启发式值 h。
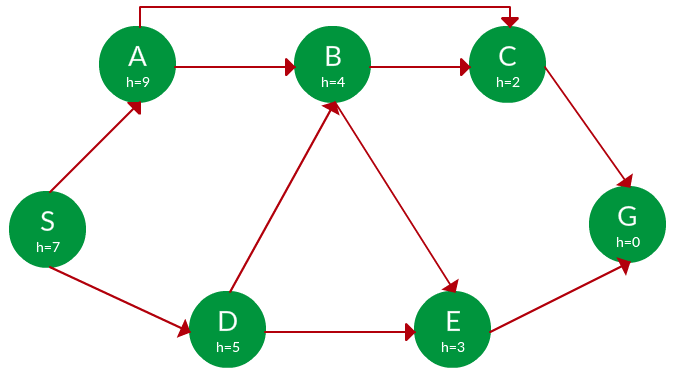
解决方案。从S开始,我们可以遍历到A(h=9)或者D(h=5)。我们选择 D,因为它具有较低的启发式成本。现在从 D,我们可以移动到 B(h=4) 或 E(h=3)。我们选择具有较低启发成本的 E。最后,从 E 到 G(h=0)。整个遍历在下面的搜索树中以蓝色显示。
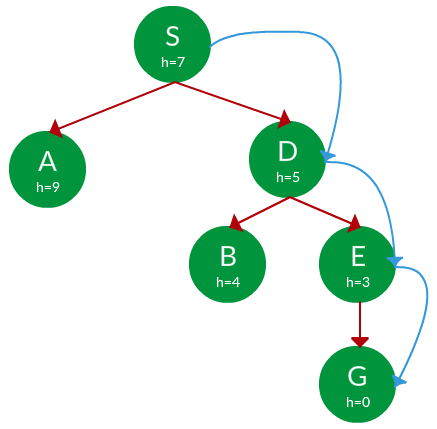
路径: S -> D -> E -> G
优点:适用于知情的搜索问题,实现目标的步骤更少。
缺点:在最坏的情况下会变成无引导的 DFS。
A* 树搜索:
A* 树搜索,或简称为 A* 搜索,结合了统一成本搜索和贪心搜索的优势。在此搜索中,启发式算法是 UCS 中的成本(用 g(x) 表示)和贪心搜索中的成本(用 h(x) 表示)的总和。总成本用 f(x) 表示。
启发式:在 A* 搜索中应注意以下几点启发式。
- 这里,h(x) 称为前向成本,是对当前节点到目标节点的距离的估计。
- 并且,g(x) 称为后向成本,是从根节点到节点的累积成本。
- 只有当对于所有节点,节点的前向成本 h(x) 低估了达到目标的实际成本 h*(x) 时,A* 搜索才是最优的。 A*启发式的这种性质称为可接纳性。

策略:选择具有最低 f(x) 值的节点。
例子:
题。使用 A* 搜索找到从 S 到 G 的路径。
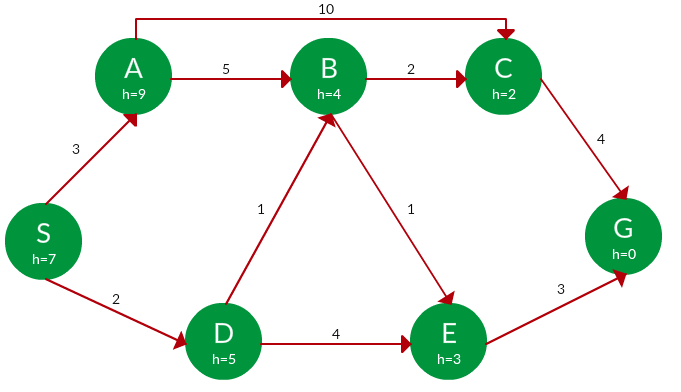
解决方案。从 S 开始,算法在每一步计算边缘中所有节点的 g(x) + h(x),选择总和最小的节点。整个工作如下表所示。
请注意,在第四组迭代中,我们得到两条总成本 f(x) 相等的路径,因此我们在下一组中将它们都展开。进一步扩展成本较低的路径是选择的路径。Path h(x) g(x) f(x) S 7 0 7 S -> A 9 3 12 S -> D ✔ 5 2 7 S -> D -> B ✔ 4 2 + 1 = 3 7 S -> D -> E 3 2 + 4 = 6 9 S -> D -> B -> C ✔ 2 3 + 2 = 5 7 S -> D -> B -> E ✔ 3 3 + 1 = 4 7 S -> D -> B -> C -> G 0 5 + 4 = 9 9 S -> D -> B -> E -> G ✔ 0 4 + 3 = 7 7
费用: 7
A* 图表搜索:
- A* 树搜索效果很好,只是重新探索已经探索过的分支需要时间。换句话说,如果同一个节点在搜索树的不同分支中扩展了两次,A* 搜索可能会探索这两个分支,从而浪费时间
- A* Graph Search,或简称 Graph Search,通过添加以下规则来消除此限制:不要多次展开同一个节点。
- 启发式。仅当两个连续节点 A 和 B 之间的前向成本(由 h(A) – h (B) 给出)小于或等于这两个节点之间的后向成本 g(A -> B) 时,图搜索才是最优的。图搜索启发式的这个属性称为一致性。
例子:
题。使用图形搜索在下图中查找从 S 到 G 的路径。
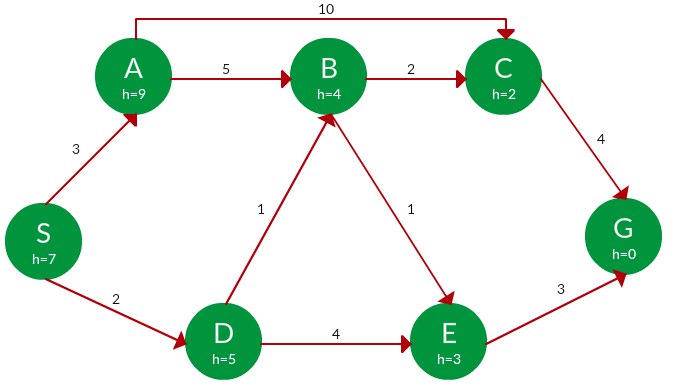
解决方案。我们解决这个问题的方式与解决上一个问题的方式几乎相同,但在这种情况下,我们会跟踪探索过的节点,这样我们就不会重新探索它们。
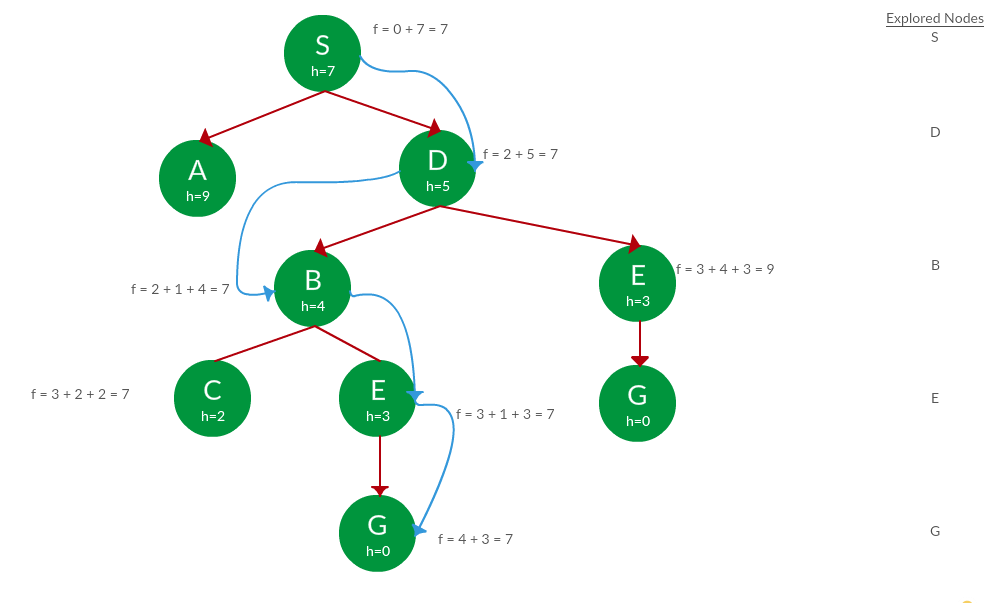
路径: S -> D -> B -> C -> E -> G
费用: 7
参考:
- CS 188 讲座幻灯片
- 人工智能:现代方法,3e