ML – 不同的回归类型
回归分析:
它是一种预测建模技术,用于研究因变量(目标)和自变量(预测变量)之间的关系。
为了建立不同变量之间可能的关系,实施了各种统计方法模式,称为回归分析。基本上,回归分析建立了一个方程来解释一个或多个预测变量与响应变量之间的显着关系,并估计当前的观察结果。回归模型属于监督学习,我们试图在连续输出中预测结果,这意味着我们试图将输入变量映射到某个连续函数。根据房屋的大小、价格等特征预测房屋的价格是回归的常见示例之一
ML 中的回归类型
- 线性回归:
线性回归试图通过将线性方程拟合到观测数据来模拟两个变量之间的关系。一个变量被认为是一个解释变量,另一个被认为是一个因变量。它用一个方程表示:Y = a + b*X + e其中 a 是截距,b 是直线的斜率,e 是误差项。该等式可用于基于给定的预测变量来预测目标变量的值。这可以使用矢量化形式更简洁地编写,如下所示:

哪里啊?是假设函数,使用模型参数 ?。 - 逻辑回归:一些回归算法也可用于分类。逻辑回归通常用于估计实例属于特定类的概率。例如,这封电子邮件是垃圾邮件的概率是多少?如果估计概率大于 50%,则该实例属于称为正类 (1) 的那个类,否则它预测它不属于负类 (0)。这使其成为二元分类。
为了将预测值映射到概率,我们使用 sigmoid函数。该函数将任何实际值映射到 0 到 1 之间的另一个值。y = 1/(1 + e(-x)).这种线性关系可以写成以下数学形式:

- 多项式回归:如果我们的数据实际上比简单的直线更复杂怎么办?令人惊讶的是,我们实际上可以使用线性模型来拟合非线性数据。一个简单的方法是将每个特征的幂添加为新特征,然后在这个扩展的特征集上训练一个线性模型。这种技术称为多项式回归。 下面的方程表示一个多项式方程:

- Softmax Regression: Logistic Regression 模型可以推广到直接支持多个类,而无需训练和组合多个二元分类器。这被称为 So max Regression,或 Multinomial Logistic Regression。 想法很简单:当给定一个实例 x 时,Softmax Regression 模型首先计算每个类 k 的分数 sk(x),然后通过应用估计每个类的概率so max函数(也称为归一化指数)到分数。 softmax 回归方程:

- 岭回归:刚性回归是线性回归的正则化版本,其中将正则化项添加到成本函数。这迫使学习算法不仅要拟合数据,还要使模型权重尽可能小。请注意,在训练期间不应将正则化项添加到成本函数中。训练模型后,您希望使用非正则化性能度量来评估模型的性能。刚性回归的公式为:

- 套索回归:类似于岭回归,套索(最小绝对收缩和选择算子)是线性回归的另一个正则化版本:它为成本函数添加了一个正则化项,但它使用加权向量的 l1 范数而不是平方的一半l2 项 Lasso 回归的表达式为:

- Elastic Net Regression: ElasticNet 是 Lasso 和 Ridge Regression 技术之间的中间地带。正则化项是刚性和 Lasso 正则化项的简单组合。当 r=0 时,Elastic Net 等价于 Rigid Regression,当 r=1 时,Elastic Net 等价于 Lasso Regression。 Elastic Net Regression 的表达式为:

需要回归:
如果我们想对给定的数据进行任何类型的数据分析,我们需要在因变量和自变量之间建立适当的关系来进行预测,这是我们评估的基础。这些关系由回归模型给出,因此它们构成了任何数据分析的核心。梯度下降:
梯度下降是一种非常通用的优化算法,能够为各种问题找到最佳解决方案。梯度下降的一般思想是迭代地调整参数以最小化成本函数。这里的函数是我们的损失函数。损失是我们预测的 m(slope) 和 c(constant) 值的误差。我们的目标是最小化这个误差以获得最准确的 m 和 c 值。
我们将使用均方误差函数来计算损失。这个函数分为三个步骤:- 对于给定的 x,找出实际 y 值和预测 y 值之间的差异(y = mx + c)。
- 平方这个差异。
- 求 X 中每个值的平方均值。

这里 y 是实际值,y' 是预测值。让我们替换 y' 的值: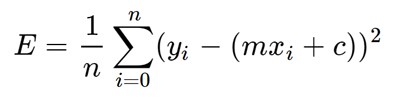
现在使用梯度下降算法通过对 m 和 c 进行部分微分来最小化上述方程。

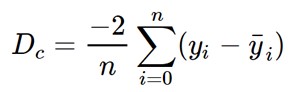
最后我们更新 m 和 c 的值如下:
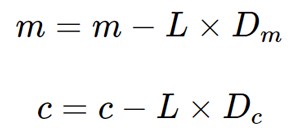
代码:梯度下降的简单演示
# Making the imports % matplotlib inline import pandas as pd import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt X = np.arange(1, 7) Y = X**2 plt.figure(figsize =(10, 10)) plt.scatter(X, y, color ="yellow") plt.title('sample demonstration of gradient descent') plt.ylabel('squared value-y') plt.xlabel('linear value-x')输出:

散点图
代码:m = 0 c = 0 L = 0.0001 # The learning Rate epochs = 1000 # The number of iterations to perform gradient descent n = float(len(X)) # Number of elements in X # Performing Gradient Descent for i in range(epochs): # The current predicted value of Y Y_pred = m * X + c # Derivative wrt m D_m = (-2 / n) * sum(X * (Y - Y_pred)) # Derivative wrt c D_c = (-2 / n) * sum(Y - Y_pred) # Update m m = m - L * D_m # Update c c = c - L * D_c print (m, c)输出:
4.471681318702568 0.6514172394787497代码:
Y_pred = m * X + c plt.figure(figsize =(10, 10)) plt.scatter(X, Y, color ="yellow") # regression line plt.plot([min(X), max(X)], [min(Y_pred), max(Y_pred)], color ='red') plt.title('sample demonstration of gradient descent') plt.ylabel('squared value-y') plt.xlabel('linear value-x') plt.show()输出:
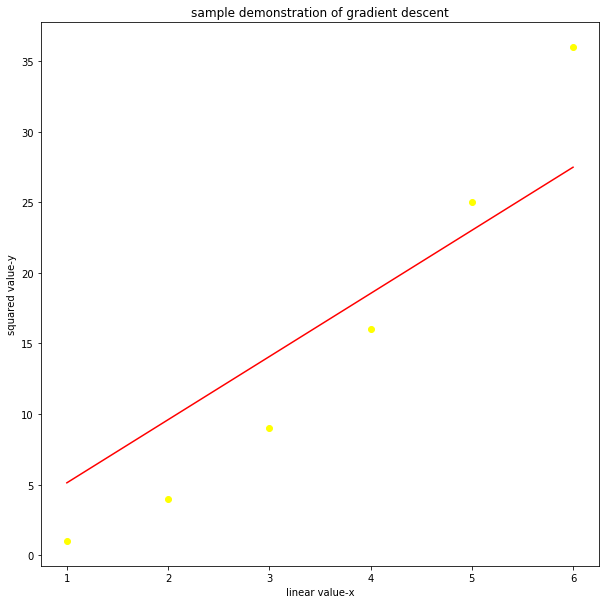
最后结果