- 使用Python的支持向量机(SVM)对数据进行分类(1)
- 使用Python的支持向量机(SVM)对数据进行分类
- 在Python使用支持向量机(SVM)对数据进行分类(1)
- 在Python使用支持向量机(SVM)对数据进行分类
- 使用R中的支持向量机(SVM)对数据进行分类
- 支持向量机(SVM)(1)
- 支持向量机(SVM)
- 支持向量机 svm 使用 python 数值示例 - Python (1)
- 支持向量机 (SVM) 简介
- 支持向量机 (SVM) 简介(1)
- 支持向量机 svm 使用 python 数值示例 - Python 代码示例
- 支持向量机 (SVM) 中的主要核函数
- 支持向量机 (SVM) 中的主要核函数(1)
- 机器学习-支持向量机(SVM)(1)
- 机器学习-支持向量机(SVM)
- 双支持向量机
- 双支持向量机(1)
- ML |使用SVM对非线性数据集执行分类(1)
- ML |使用SVM对非线性数据集执行分类
- Python|对列表中的输入数据进行分类
- Python|对列表中的输入数据进行分类(1)
- 数据分类
- 数据分类(1)
- 使用 JavaScript 进行图像分类
- 使用 JavaScript 进行图像分类(1)
- 支持向量机算法
- Python Pandas-分类数据(1)
- Python Pandas-分类数据
- 5.4.7 分类python(1)
📅 最后修改于: 2020-04-28 01:12:31 🧑 作者: Mango
SVM简介:
在机器学习中,支持向量机(SVM)是带有相关学习算法的监督学习模型,该算法分析用于分类和回归分析的数据。
支持向量机(SVM)是由分离超平面正式定义的判别式分类器。换句话说,给定带标签的训练数据(监督学习),该算法会输出对新示例进行分类的最佳超平面。
什么是支持向量机?
SVM模型是将示例表示为空间中的点,并进行了映射,以使各个类别的示例被尽可能宽的明显间隙分开。
除了执行线性分类外,SVM还可以有效地执行非线性分类,将其输入隐式映射到高维特征空间。
SVM有什么作用?
给定一组训练示例,每个训练示例都标记为属于两个类别中的一个或另一个,则SVM训练算法将构建一个模型,该模型将新示例分配给一个类别或另一个类别,使其成为非概率二进制线性分类器。
让我们快速了解一下支持向量分类。首先,我们需要创建一个数据集:
# 使用make_blobs导入scikit学习
from sklearn.datasets.samples_generator import make_blobs
# 创建包含n_samples的数据集X
# Y containing two classes
X, Y = make_blobs(n_samples=500, centers=2,
random_state=0, cluster_std=0.40)
# 散点图
plt.scatter(X[:, 0], X[:, 1], c=Y, s=50, cmap='spring');
plt.show()输出:
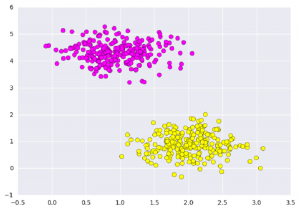
支持向量机所做的不仅是在此处在两个类之间画一条线,而且还要考虑围绕某个给定宽度的线的区域。这是一个看起来像的例子:
# 创建-1至3.5之间的行距
xfit = np.linspace(-1, 3.5)
# 散点图
plt.scatter(X[:, 0], X[:, 1], c=Y, s=50, cmap='spring')
# 在不同的数据集之间划一条线
for m, b, d in [(1, 0.65, 0.33), (0.5, 1.6, 0.55), (-0.2, 2.9, 0.2)]:
yfit = m * xfit + b
plt.plot(xfit, yfit, '-k')
plt.fill_between(xfit, yfit - d, yfit + d, edgecolor='none',
color='#AAAAAA', alpha=0.4)
plt.xlim(-1, 3.5);
plt.show()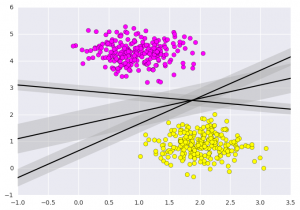
导入数据集
这是支持向量机的直观功能,它可以优化表示数据集之间垂直距离的线性判别模型。现在,让我们使用我们的训练数据来训练分类器。在训练之前,我们需要将癌症数据集导入为csv文件,从中我们将训练所有特征中的两个特征。
# 导入所需的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 读取csv文件并将类列提取到y.
x = pd.read_csv("C:\...\cancer.csv")
a = np.array(x)
y = a[:,30] # classes having 0 and 1
# 提取两个特征
x = np.column_stack((x.malignant,x.benign))
x.shape # 569 samples and 2 features
print (x),(y)输出:
[[122.8 1001.]
[132.9 1326.]
[130. 1203.]
...,
[108.3 858.1]
[140.1 1265.]
[47.92 181.]]
array([0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,
0.,0.,0.,0.,0.,0.,1.,1.,1.,0.,0.,0.,0.,
0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,1.,0.,
0.,0.,0.,0.,0.,0.,0.,1.,0.,1.,1.,1.,1.,
1.,0.,0.,1.,0.,0.,1.,1.,1.,1.,0.,1.,....,
1.])拟合支持向量机
现在,我们将为这些要点提供支持向量机分类器。尽管似然模型的数学细节很有趣,但我们将在其他地方进行介绍。相反,我们将scikit-learn算法视为完成上述任务的黑匣子。
# 导入支持向量分类器
from sklearn.svm import SVC# "Support Vector Classifier"
clf = SVC(kernel='linear')
# 拟合x样本和y类
clf.fit(x, y)拟合后,该模型可用于预测新值:
clf.predict([[120, 990]])
clf.predict([[85, 550]])输出:
array([ 0.])
array([ 1.])让我们在图表上看一下如何显示。

这是通过分析数据和使用matplotlib函数制作最佳超平面的预处理方法来获得的。