- 支持向量机 (SVM) 简介
- 支持向量机 (SVM) 简介(1)
- 支持向量机 (SVM) 中的主要核函数(1)
- 支持向量机 (SVM) 中的主要核函数
- 机器学习-支持向量机(SVM)(1)
- 机器学习-支持向量机(SVM)
- 支持向量机 svm 使用 python 数值示例 - Python (1)
- 使用R中的支持向量机(SVM)对数据进行分类
- 在Python使用支持向量机(SVM)对数据进行分类(1)
- 在Python使用支持向量机(SVM)对数据进行分类
- 使用Python中的支持向量机(SVM)对数据进行分类
- 使用Python的支持向量机(SVM)对数据进行分类(1)
- 使用Python的支持向量机(SVM)对数据进行分类
- 使用Python中的支持向量机(SVM)对数据进行分类(1)
- 支持向量机 svm 使用 python 数值示例 - Python 代码示例
- 双支持向量机(1)
- 双支持向量机
- 支持向量机算法
- sklearn 支持向量机 (1)
- 在Python中创建线性核 SVM
- 在Python中创建线性核 SVM(1)
- 如何在 r 中构建 svm 模型 (1)
- sklearn 支持向量机 - 任何代码示例
- gradle 中的支持向量 - 无论代码示例
- 机器学习中的支持向量机
- 机器学习中的支持向量机(1)
- 如何在 r 中构建 svm 模型 - 无论代码示例
- 向量之和 c++ (1)
- 向量的向量 c++ (1)
📅 最后修改于: 2020-12-10 05:35:59 🧑 作者: Mango
SVM简介
支持向量机(SVM)是强大而灵活的有监督的机器学习算法,可用于分类和回归。但通常,它们用于分类问题。在1960年代,SVM首次推出,但在1990年得到了完善。与其他机器学习算法相比,SVM具有其独特的实现方式。最近,由于它们能够处理多个连续和分类变量,它们非常受欢迎。
SVM的工作
SVM模型基本上是多维空间中超平面中不同类的表示。 SVM将以迭代方式生成超平面,从而可以最大程度地减少误差。 SVM的目标是将数据集划分为几类,以找到最大边缘超平面(MMH)。
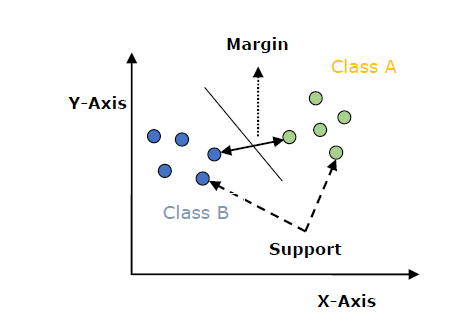
以下是SVM中的重要概念-
-
支持向量-最接近超平面的数据点称为支持向量。将在这些数据点的帮助下定义分隔线。
-
超平面-从上图中可以看出,它是一个决策平面或空间,被划分为一组具有不同类的对象。
-
裕度-可以定义为不同类别的壁橱数据点上两条线之间的间隙。可以将其计算为从线到支持向量的垂直距离。大保证金被认为是好的保证金,小保证金被认为是坏的保证金。
SVM的主要目标是将数据集划分为类以找到最大边缘超平面(MMH),可以通过以下两个步骤完成-
-
首先,SVM将迭代生成超平面,以最佳方式隔离类。
-
然后,它将选择能正确分隔类的超平面。
在Python实现SVM
为了在Python实现SVM,我们将从标准库导入开始,如下所示-
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
import seaborn as sns; sns.set()
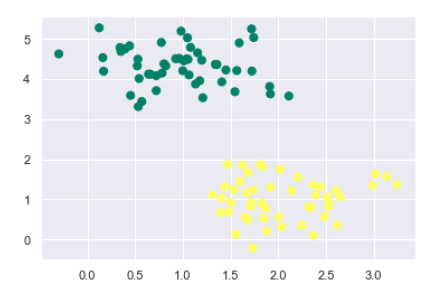
接下来,我们从sklearn.dataset.sample_generator创建具有线性可分离数据的样本数据集,以使用SVM进行分类-
from sklearn.datasets.samples_generator import make_blobs
X, y = make_blobs(n_samples=100, centers=2, random_state=0, cluster_std=0.50)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='summer');
以下是生成具有100个样本和2个聚类的样本数据集后的输出-
我们知道SVM支持判别分类。它通过在二维的情况下简单地找到一条线,在多维的情况下通过歧管来简单地将类彼此划分。它在上述数据集上实现如下-
xfit = np.linspace(-1, 3.5)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='summer')
plt.plot([0.6], [2.1], 'x', color='black', markeredgewidth=4, markersize=12)
for m, b in [(1, 0.65), (0.5, 1.6), (-0.2, 2.9)]:
plt.plot(xfit, m * xfit + b, '-k')
plt.xlim(-1, 3.5);
输出如下-
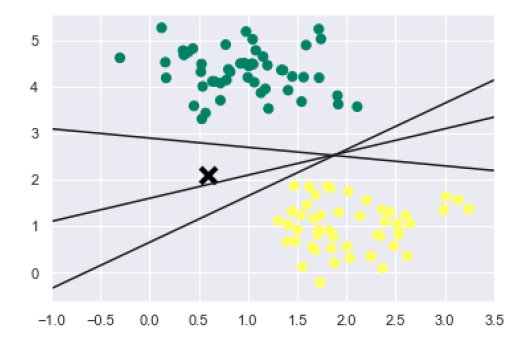
从上面的输出中我们可以看到,有三种不同的分隔符可以完美地区分以上示例。
正如讨论的那样,SVM的主要目标是将数据集划分为类,以找到最大的边缘超平面(MMH),因此,我们不必在类之间绘制零线,而可以在每条线周围画出一定宽度的边缘,直到最近的点。它可以做到如下-
xfit = np.linspace(-1, 3.5)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='summer')
for m, b, d in [(1, 0.65, 0.33), (0.5, 1.6, 0.55), (-0.2, 2.9, 0.2)]:
yfit = m * xfit + b
plt.plot(xfit, yfit, '-k')
plt.fill_between(xfit, yfit - d, yfit + d, edgecolor='none',
color='#AAAAAA', alpha=0.4)
plt.xlim(-1, 3.5);
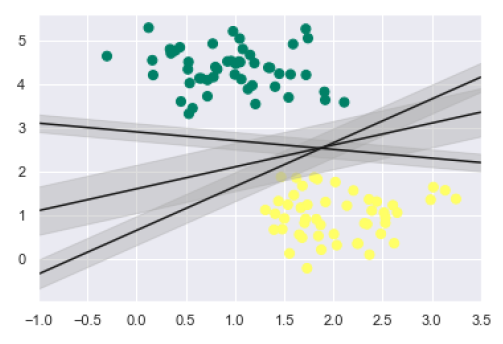
从上面的输出图像中,我们可以轻松地观察到判别式分类器中的“边距”。 SVM将选择最大化边距的线。
接下来,我们将使用Scikit-Learn的支持向量分类器在此数据上训练SVM模型。在这里,我们使用线性内核来拟合SVM,如下所示:
from sklearn.svm import SVC # "Support vector classifier"
model = SVC(kernel='linear', C=1E10)
model.fit(X, y)
输出如下-
SVC(C=10000000000.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto_deprecated',
kernel='linear', max_iter=-1, probability=False, random_state=None,
shrinking=True, tol=0.001, verbose=False)
现在,为了更好地理解,以下内容将绘制2D SVC的决策函数-
def decision_function(model, ax=None, plot_support=True):
if ax is None:
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
为了评估模型,我们需要创建网格,如下所示:
x = np.linspace(xlim[0], xlim[1], 30)
y = np.linspace(ylim[0], ylim[1], 30)
Y, X = np.meshgrid(y, x)
xy = np.vstack([X.ravel(), Y.ravel()]).T
P = model.decision_function(xy).reshape(X.shape)
接下来,我们需要绘制决策边界和边际,如下所示:
ax.contour(X, Y, P, colors='k',
levels=[-1, 0, 1], alpha=0.5,
linestyles=['--', '-', '--'])
现在,类似地绘制支持向量,如下所示:
if plot_support:
ax.scatter(model.support_vectors_[:, 0],
model.support_vectors_[:, 1],
s=300, linewidth=1, facecolors='none');
ax.set_xlim(xlim)
ax.set_ylim(ylim)
现在,使用此函数来拟合我们的模型,如下所示:
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='summer')
decision_function(model);
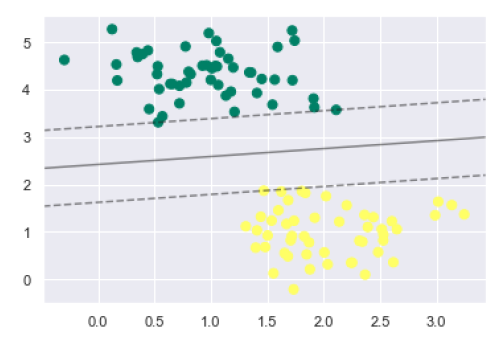
我们可以从上面的输出中观察到,SVM分类器以边距(即虚线和支持向量)拟合数据,该拟合的关键要素触及虚线。这些支持向量点存储在分类器的support_vectors_属性中,如下所示:
model.support_vectors_
输出如下-
array([[0.5323772 , 3.31338909],
[2.11114739, 3.57660449],
[1.46870582, 1.86947425]])
SVM内核
实际上,SVM算法是用内核实现的,该内核将输入数据空间转换为所需的形式。 SVM使用一种称为内核技巧的技术,其中内核占用低维输入空间并将其转换为高维空间。简而言之,内核通过增加更多维度来将不可分离的问题转换为可分离的问题。它使SVM更加强大,灵活和准确。以下是SVM使用的一些内核类型-
线性核
它可以用作任意两个观测值之间的点积。线性核的公式如下-
k(x,x i )=和(x * x i )
从上面的公式中,我们可以看到两个向量之间的乘积𝑥和𝑥𝑖是每对输入值的乘积之和。
多项式内核
它是线性核的更广义形式,可以区分弯曲或非线性输入空间。以下是多项式内核的公式-
K(x,xi)= 1 +和(x * xi)^ d
这里d是多项式的阶数,我们需要在学习算法中手动指定它。
径向基函数(RBF)内核
RBF内核(主要用于SVM分类)将输入空间映射到不确定的维空间中。以下公式在数学上对其进行了解释-
K(x,xi)= exp(-伽玛* sum((x – xi ^ 2))
此处,伽马的范围是0到1。我们需要在学习算法中手动指定它。好的伽玛默认值为0.1。
当我们为线性可分离的数据实现SVM时,我们可以在Python为不可线性分离的数据实现它。可以通过使用内核来完成。
例
以下是使用内核创建SVM分类器的示例。我们将使用来自scikit-learn的虹膜数据集-
我们将从导入以下包开始-
import pandas as pd
import numpy as np
from sklearn import svm, datasets
import matplotlib.pyplot as plt
现在,我们需要加载输入数据-
iris = datasets.load_iris()
从此数据集中,我们采用以下两个特征:
X = iris.data[:, :2]
y = iris.target
接下来,我们将使用原始数据绘制SVM边界,如下所示:
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = (x_max / x_min)/100
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
X_plot = np.c_[xx.ravel(), yy.ravel()]
现在,我们需要提供正则化参数的值,如下所示:
C = 1.0
接下来,可以如下创建SVM分类器对象-
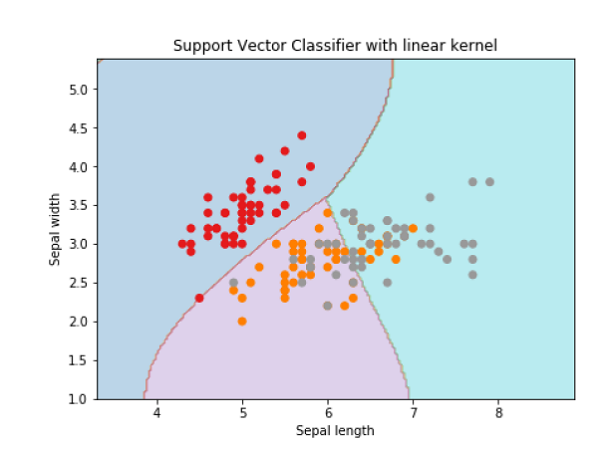
Svc_classifier = svm.SVC(内核=’线性’,C = C).fit(X,y)
Z = svc_classifier.predict(X_plot)
Z = Z.reshape(xx.shape)
plt.figure(figsize=(15, 5))
plt.subplot(121)
plt.contourf(xx, yy, Z, cmap=plt.cm.tab10, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('Support Vector Classifier with linear kernel')
输出
Text(0.5, 1.0, 'Support Vector Classifier with linear kernel')
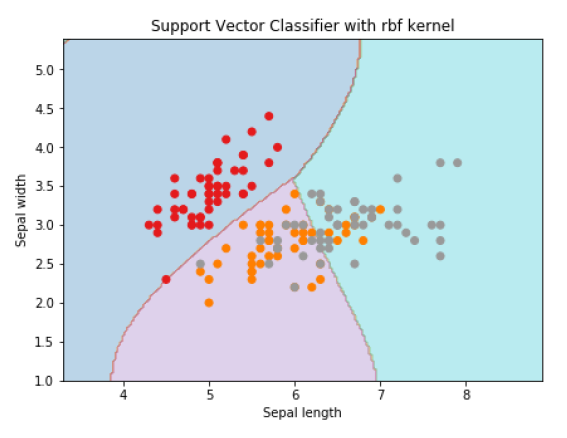
为了使用rbf内核创建SVM分类器,我们可以将内核更改为rbf ,如下所示-
Svc_classifier = svm.SVC(kernel='rbf', gamma =‘auto’,C=C).fit(X, y)
Z = svc_classifier.predict(X_plot)
Z = Z.reshape(xx.shape)
plt.figure(figsize=(15, 5))
plt.subplot(121)
plt.contourf(xx, yy, Z, cmap=plt.cm.tab10, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('Support Vector Classifier with rbf kernel')
输出
Text(0.5, 1.0, 'Support Vector Classifier with rbf kernel')
我们将gamma的值设置为“ auto”,但您也可以提供0到1之间的值。
SVM分类器的优缺点
SVM分类器的优点
SVM分类器具有很高的准确性,并且可以在高维空间中很好地工作。 SVM分类器基本上使用训练点的子集,因此结果使用的内存非常少。
SVM分类器的缺点
他们训练时间长,因此在实践中不适合大型数据集。另一个缺点是SVM分类器不能与重叠的类一起很好地工作。