Julia 中的聚类
Julia 中的聚类是无监督学习中非常常用的方法。在这种方法中,我们根据它们具有的共同特征的数量将相似的数据点放入一个集群中。在聚类过程中创建的聚类数量是根据数据集的复杂性和大小决定的。集群中的所有点都有一些相似性,这些相似性可以根据在开始训练之前选择的特征数量来增加或减少。
聚类在 Julia 中的应用
- 营销:营销中的聚类对于寻找某种产品的潜在买家非常有用。聚类用于在市场中寻找模式,帮助公司为未来做出正确的决策。
- 医学科学:随着科学的飞速发展,新的发现非常频繁。为了识别和分类新的微生物物种,聚类非常有用。聚类用于根据生物体的特征识别其所属的家族。
- 网站:许多网站使用聚类通过找出可能相关的用户来推广他们的网站。网站设计也受到使用聚类的影响,以找出吸引用户的设计类型。
聚类类型
聚类可以分为两个主要部分:
硬聚类:这是一种聚类,其中一个数据点只能属于一个聚类。一个数据点要么完全属于一个集群,要么根本不属于一个集群。这种类型的聚类不使用概率将数据点放入聚类。硬聚类最常见的例子是 K 均值聚类。
软聚类:在这种类型的聚类中,一个数据点可能存在于许多或所有聚类中。这种聚类方法并没有将一个数据点完全放入一个聚类中。每个数据点都有一定的概率存在于每个集群中。这种类型的聚类用于模糊编程或软计算。
Julia 中的 K 均值聚类
K-means 聚类属于无监督学习。这是一种迭代方法,其中数据点根据其特征的相似性被放置在一个预定义的集群中。集群的数量由用户在训练前设置。该方法还找出簇的质心。
算法:
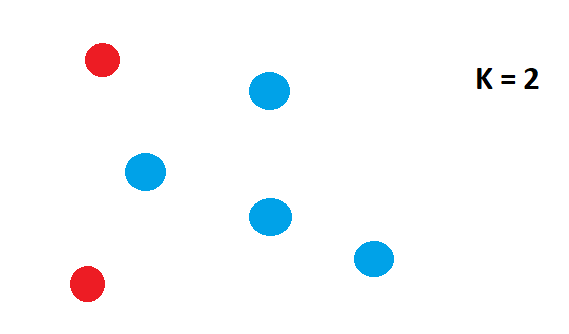
- 指定簇数 (K):让我们以 2 个簇和 6 个数据点为例。

- 将每个数据点随机分配给一个集群:在下面的示例中,我们为确定两个集群的数据点随机分配了颜色。
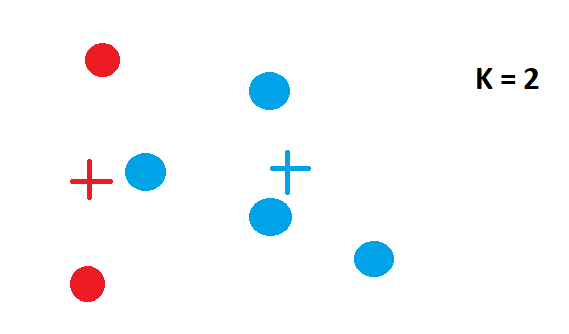
- 计算聚类质心:计算出的聚类质心由其对应的颜色表示。
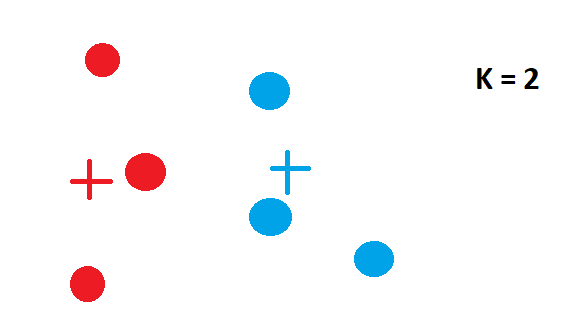
- 检查所有数据点并将它们放入质心最近的集群中:在下图中,上一步中的蓝色点移动到红色集群,因为它最靠近红色集群质心。
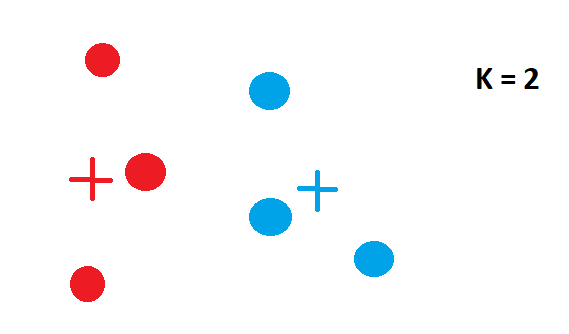
- 重新计算每个簇的质心:现在重新计算后质心会稍微移动。
Syntax: kmeans(X,k)
where,
X: represents the features
k: represents the number of clusters
Julia
using RDatasets, Clustering, Plots
# loading the dataset
iris = dataset("datasets", "iris");
# features for clustering
features = collect(Matrix(iris[:, 1:4])');
# result after running K-means for the 3 clusters
result = kmeans(features, 3);
# plotting the result
scatter(iris.PetalLength, iris.PetalWidth,
marker_z = result.assignments,
color =:lightrainbow, legend = false)
# saving the result in PNG form
savefig("D:\\iris.png")输出:
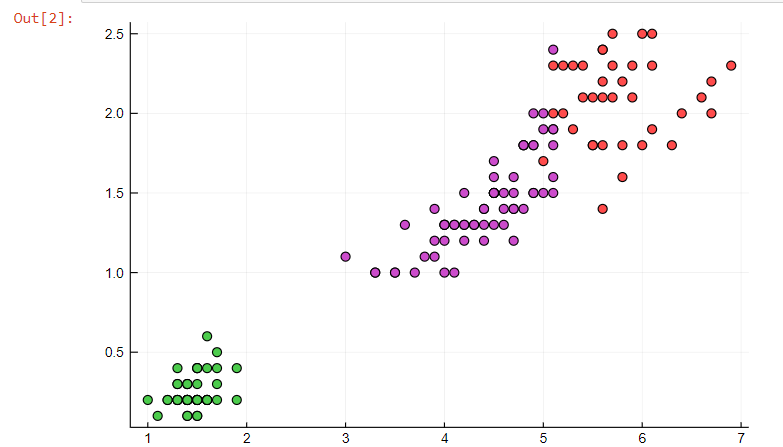
相似聚合聚类
这是另一种类型的聚类,其中将每个数据点与成对的每个其他数据点进行比较。这种聚类方法也称为 Condorcet 方法或关系聚类。对于一对值 X 和 Y,将值分配给两个向量 m(X, Y) 和 d(X, Y)。 X 和 Y 的值在 m(X, Y) 中相同,但在 d(X, Y) 中不同。

其中,S 是集群
第一个条件用于创建集群。第二个条件用于计算全局 Condorcet 标准。这是一个迭代过程,迭代发生直到不满足特定迭代条件或全局 Condorcet 标准没有改进。