获取 PySpark 数据框的行数和列数
在本文中,我们将讨论如何获取 PySpark 数据帧的行数和列数。为了找到行数和列数,我们将分别使用 count() 和 columns() 和 len()函数。
- df.count():该函数用于从 Dataframe 中提取行数。
- df.distinct().count():此函数用于提取数据帧中不重复/重复的不同数字行。
- df.columns():此函数用于提取 Dataframe 中存在的列名称列表。
- len(df.columns):此函数用于计算列表中存在的项目数。
示例1:获取pyspark中dataframe的行数和列数。
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Products.com") \
.getOrCreate()
return spk
# function to create Dataframe
def create_df(spark,data,schema):
df1 = spark.createDataFrame(data,schema)
return df1
# main function
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [(1,"Direct-Cool Single Door Refrigerator",12499),
(2,"Full HD Smart LED TV",49999),
(3,"8.5 kg Washing Machine",69999),
(4,"T-shirt",1999),
(5,"Jeans",3999),
(6,"Men's Running Shoes",1499),
(7,"Combo Pack Face Mask",999)]
schm = ["Id","Product Name","Price"]
# calling function to create dataframe
df = create_df(spark,input_data,schm)
df.show()
# extracting number of rows from the Dataframe
row = df.count()
# extracting number of columns from the Dataframe
col = len(df.columns)
# printing
print(f'Dimension of the Dataframe is: {(row,col)}')
print(f'Number of Rows are: {row}')
print(f'Number of Columns are: {col}')Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Student_report.com") \
.getOrCreate()
return spk
# function to create Dataframe
def create_df(spark,data,schema):
df1 = spark.createDataFrame(data,schema)
return df1
# main function
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [(1,"Shivansh","Male",20,80),
(2,"Arpita","Female",18,66),
(3,"Raj","Male",21,90),
(4,"Swati","Female",19,91),
(5,"Arpit","Male",20,50),
(6,"Swaroop","Male",23,65),
(6,"Swaroop","Male",23,65),
(6,"Swaroop","Male",23,65),
(7,"Reshabh","Male",19,70),
(7,"Reshabh","Male",19,70),
(8,"Dinesh","Male",20,75),
(9,"Rohit","Male",21,85),
(9,"Rohit","Male",21,85),
(10,"Sanjana","Female",22,87)]
schm = ["Id","Name","Gender","Age","Percentage"]
# calling function to create dataframe
df = create_df(spark,input_data,schm)
df.show()
# extracting number of distinct rows
# from the Dataframe
row = df.distinct().count()
# extracting total number of rows from
# the Dataframe
all_rows = df.count()
# extracting number of columns from the
# Dataframe
col = len(df.columns)
# printing
print(f'Dimension of the Dataframe is: {(row,col)}')
print(f'Distinct Number of Rows are: {row}')
print(f'Total Number of Rows are: {all_rows}')
print(f'Number of Columns are: {col}')Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Student_report.com") \
.getOrCreate()
return spk
# function to create Dataframe
def create_df(spark,data,schema):
df1 = spark.createDataFrame(data,schema)
return df1
# main function
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [(1,"Shivansh","Male",20,80),
(2,"Arpita","Female",18,66),
(3,"Raj","Male",21,90),
(4,"Swati","Female",19,91),
(5,"Arpit","Male",20,50),
(6,"Swaroop","Male",23,65),
(7,"Reshabh","Male",19,70),
(8,"Dinesh","Male",20,75),
(9,"Rohit","Male",21,85),
(10,"Sanjana","Female",22,87)]
schm = ["Id","Name","Gender","Age","Percentage"]
# calling function to create dataframe
df = create_df(spark,input_data,schm)
df.show()
# extracting number of rows from the Dataframe
row = df.count()
# extracting number of columns from the Dataframe using dtypes function
col = len(df.dtypes)
# printing
print(f'Dimension of the Dataframe is: {(row,col)}')
print(f'Number of Rows are: {row}')
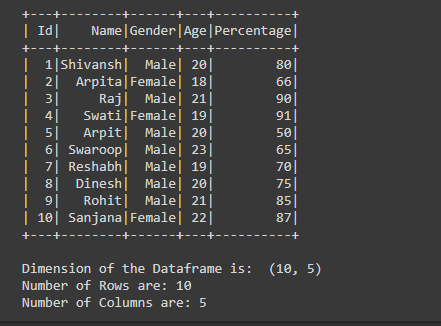
print(f'Number of Columns are: {col}')Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Student_report.com") \
.getOrCreate()
return spk
# function to create Dataframe
def create_df(spark,data,schema):
df1 = spark.createDataFrame(data,schema)
return df1
# main function
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [(1,"Shivansh","Male",20,80),
(2,"Arpita","Female",18,66),
(3,"Raj","Male",21,90),
(4,"Swati","Female",19,91),
(5,"Arpit","Male",20,50),
(6,"Swaroop","Male",23,65),
(7,"Reshabh","Male",19,70),
(8,"Dinesh","Male",20,75),
(9,"Rohit","Male",21,85),
(10,"Sanjana","Female",22,87)]
schm = ["Id","Name","Gender","Age","Percentage"]
# calling function to create dataframe
df = create_df(spark,input_data,schm)
df.show()
# converting PySpark df to Pandas df using
# toPandas() function
new_df = df.toPandas()
# using Pandas shape function for getting the
# dimension of the df
dimension = new_df.shape
# printing
print("Dimension of the Dataframe is: ",dimension)
print(f'Number of Rows are: {dimension[0]}')
print(f'Number of Columns are: {dimension[1]}')输出:

解释:
- 为了计算行数,我们使用了 count()函数df.count() ,它从 Dataframe 中提取行数并将其存储在名为“row”的变量中
- 为了计算列数,我们使用df.columns()但由于此函数返回列名称列表,因此对于列表中存在的项目数的计数,我们使用len()函数,我们在其中传递df .columns()这为我们提供了总列数并将其存储在名为“col”的变量中。
示例 2:获取Dataframe的不同行数和列数。
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Student_report.com") \
.getOrCreate()
return spk
# function to create Dataframe
def create_df(spark,data,schema):
df1 = spark.createDataFrame(data,schema)
return df1
# main function
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [(1,"Shivansh","Male",20,80),
(2,"Arpita","Female",18,66),
(3,"Raj","Male",21,90),
(4,"Swati","Female",19,91),
(5,"Arpit","Male",20,50),
(6,"Swaroop","Male",23,65),
(6,"Swaroop","Male",23,65),
(6,"Swaroop","Male",23,65),
(7,"Reshabh","Male",19,70),
(7,"Reshabh","Male",19,70),
(8,"Dinesh","Male",20,75),
(9,"Rohit","Male",21,85),
(9,"Rohit","Male",21,85),
(10,"Sanjana","Female",22,87)]
schm = ["Id","Name","Gender","Age","Percentage"]
# calling function to create dataframe
df = create_df(spark,input_data,schm)
df.show()
# extracting number of distinct rows
# from the Dataframe
row = df.distinct().count()
# extracting total number of rows from
# the Dataframe
all_rows = df.count()
# extracting number of columns from the
# Dataframe
col = len(df.columns)
# printing
print(f'Dimension of the Dataframe is: {(row,col)}')
print(f'Distinct Number of Rows are: {row}')
print(f'Total Number of Rows are: {all_rows}')
print(f'Number of Columns are: {col}')
输出:

解释:
- 为了计算不同行的数量,我们使用了distinct().count()函数,该函数从 Dataframe 中提取不同行的数量并将其存储在名为“row”的变量中
- 为了计算列数,我们使用df.columns()但由于此函数返回列名列表,因此为了计算列表中存在的项目数,我们使用len()函数,我们在其中传递df .columns()这为我们提供了总列数并将其存储在名为“col”的变量中
示例 3:使用 dtypes函数获取列数。
在示例中,在创建 Dataframe 后,我们使用 count()函数计算行数,此处使用 dtypes函数计算列数。因为我们知道 dtypes函数返回包含列名和列数据类型的元组列表。所以对于每一列,都有一个包含列的名称和数据类型的元组,从列表中我们只是计算元组元组的数量等于列的数量所以这也是获得数字的一种方法使用 dtypes函数的列数。
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Student_report.com") \
.getOrCreate()
return spk
# function to create Dataframe
def create_df(spark,data,schema):
df1 = spark.createDataFrame(data,schema)
return df1
# main function
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [(1,"Shivansh","Male",20,80),
(2,"Arpita","Female",18,66),
(3,"Raj","Male",21,90),
(4,"Swati","Female",19,91),
(5,"Arpit","Male",20,50),
(6,"Swaroop","Male",23,65),
(7,"Reshabh","Male",19,70),
(8,"Dinesh","Male",20,75),
(9,"Rohit","Male",21,85),
(10,"Sanjana","Female",22,87)]
schm = ["Id","Name","Gender","Age","Percentage"]
# calling function to create dataframe
df = create_df(spark,input_data,schm)
df.show()
# extracting number of rows from the Dataframe
row = df.count()
# extracting number of columns from the Dataframe using dtypes function
col = len(df.dtypes)
# printing
print(f'Dimension of the Dataframe is: {(row,col)}')
print(f'Number of Rows are: {row}')
print(f'Number of Columns are: {col}')
输出:

示例 4:通过将 PySpark Dataframe 转换为 Pandas Dataframe 来获取 PySpark Dataframe 的维度。
在示例代码中,在创建 Dataframe 之后,我们使用 toPandas()函数通过编写df.toPandas()将 PySpark Dataframe 转换为 Pandas Dataframe 。转换数据框后,我们使用 Pandas函数形状来获取数据框的维度。此形状函数返回元组,因此用于单独打印行数和列数。
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Student_report.com") \
.getOrCreate()
return spk
# function to create Dataframe
def create_df(spark,data,schema):
df1 = spark.createDataFrame(data,schema)
return df1
# main function
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [(1,"Shivansh","Male",20,80),
(2,"Arpita","Female",18,66),
(3,"Raj","Male",21,90),
(4,"Swati","Female",19,91),
(5,"Arpit","Male",20,50),
(6,"Swaroop","Male",23,65),
(7,"Reshabh","Male",19,70),
(8,"Dinesh","Male",20,75),
(9,"Rohit","Male",21,85),
(10,"Sanjana","Female",22,87)]
schm = ["Id","Name","Gender","Age","Percentage"]
# calling function to create dataframe
df = create_df(spark,input_data,schm)
df.show()
# converting PySpark df to Pandas df using
# toPandas() function
new_df = df.toPandas()
# using Pandas shape function for getting the
# dimension of the df
dimension = new_df.shape
# printing
print("Dimension of the Dataframe is: ",dimension)
print(f'Number of Rows are: {dimension[0]}')
print(f'Number of Columns are: {dimension[1]}')
输出: