NLP中的自注意力
自注意力是由 Google Research 和 Google Brain 的研究人员提出的。由于编码器-解码器在处理长序列时面临挑战,因此提出了它。作者还提供了注意力和转换器架构的两种变体。这种转换器架构在 WMT 翻译任务上产生了最先进的结果。
编码器-解码器模型:
编码器-解码器模型在不同的论文中提出。这两篇论文的区别是基于输入和输出长度的关系
从高层来看,该模型包括两个子模型:编码器和解码器。
- 编码器:编码器负责逐步遍历输入的时间步长,并将整个序列编码为一个固定长度的向量,称为上下文向量。
- 解码器:解码器负责在从上下文向量中读取时逐步执行输出时间步骤。
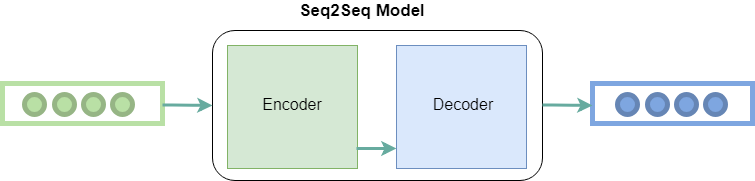
编码器-解码器架构
注意力机制:
注意是由编码器-解码器网络的作者提出的,作为它的扩展。建议克服编码器-解码器模型将输入序列编码为一个固定长度的向量的限制,从该向量解码每个输出时间步长。在解码长序列时,这个问题被认为是一个更大的问题。
自注意力机制:
自注意力
注意力机制允许输出在产生输出的同时将注意力集中在输入上,而自注意力模型允许输入相互交互(即计算所有其他输入对一个输入的注意力。
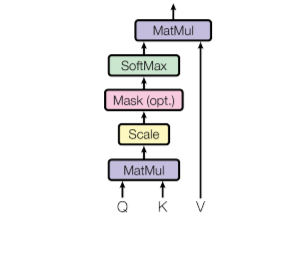
- 第一步是将每个编码器输入向量与我们在训练过程中训练的三个权重矩阵(W(Q)、W(K)、W(V))相乘。这个矩阵乘法将为每个输入向量提供三个向量:键向量、查询向量和值向量。
- 计算 self-attention 的第二步是将当前输入的 Query 向量与来自其他输入的关键向量相乘。
- 在第三步中,我们将得分除以关键向量 (d k ) 维度的平方根。论文中key vector的维数是64,所以是8。 背后的原因是如果点积变大,这会导致我们以后应用softmax函数后一些self-attention的分数非常小。
- 在第四步中,我们将对查询词(这里是第一个词)计算的所有自注意力分数应用 softmax函数。
- 在第五步中,我们将值向量乘以我们在上一步计算的向量。
- 在最后一步,我们将上一步得到的加权值向量相加,这将为我们提供给定单词的自注意力输出。
上述过程适用于所有输入序列。在数学上,输入矩阵 (Q, K, V) 的自注意力矩阵计算如下:

其中 Q、K、V 是查询、键和值向量的串联。
多头注意:
多头注意
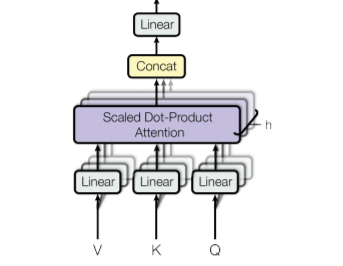
在注意力论文中,作者提出了另一种注意力机制,称为多头注意力。以下是计算多头自注意力的分步过程:
- 获取输入句子的每个单词并从中生成嵌入。
- 在这种机制中,我们创建了h (h = 8) 个不同的注意力头,每个头都有不同的权重矩阵(W(Q)、W(K)、W(V))。
- 在这一步中,我们将输入矩阵与每个权重矩阵(W Q 、W K 、W V )相乘,以生成每个注意力头的键、值和查询矩阵。
- 现在,我们将注意力机制应用于这些查询、键和值矩阵,这为我们提供了每个注意力头的输出矩阵。
- 在这一步中,我们将从每个注意力头和点积获得的输出矩阵与权重 W O 连接起来,以生成多头注意力层的输出。
数学上的多头注意力可以表示为:


Transformer架构中的注意事项:

– Transformer 架构使用注意力模型,在三个步骤中使用多头注意力:
- 第一个是编码器-解码器注意力层,在这种类型的层中,查询来自前一个解码器层,而键和值来自编码器输出。这允许解码器中的每个位置都关注输入序列的所有位置。
- 第二种类型是编码器中包含的自注意力层,该层从前一个编码器层的输出接收键、值和查询输入。编码器中的每个位置都可以从前一个编码器层中的每个位置获得注意力分数。
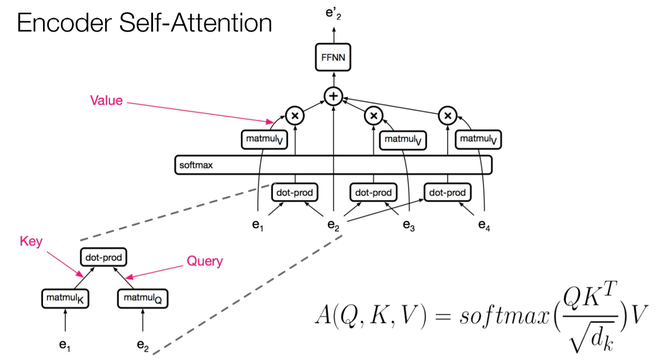
编码器中的自注意力
- 第三种是解码器中的自注意力,这类似于编码器中的自注意力,其中所有查询、键和值都来自前一层。自注意力解码器允许每个位置参与直到并包括该位置的每个位置。未来值用 (-Inf) 屏蔽。这被称为蒙面自我注意。

解码器中的自注意力
复杂性和结果:
在 NLP 任务中使用自注意力层的优点是执行起来的计算成本低于其他操作。下表表示不同操作的复杂性:

结果:
- 在 WMT 2014 英德翻译任务中,transformer 模型达到了 28.4 的 BLUE 分数,这是该任务中最新的最新技术。该模型在 8 个 NVIDIA P100 GPU 上训练了 3.5 天。这至少比以前最先进的模型快三倍。
- 在 WMT 2014 英语到法语翻译任务中,该模型获得了 41.8 的 BLUE 分数,这也是该任务中最新的最先进结果,但只需要一小部分训练成本。

参考:
- 斯坦福幻灯片关于变压器讲座
- Jay Alammar 博客
- 注意纸