使用 NLP 处理文本 |基本
先决条件:NLP 简介
在本文中,我们将讨论如何从在线文本文件中获取文本并从中提取所需的数据。出于本文的目的,我们将使用此处提供的文本文件。
当前工作环境中必须安装以下内容:
- NLTK 库
- urllib 库
- BeautifulSoup 库
步骤#1:导入所需的库
import nltk
from bs4 import BeautifulSoup
from urllib.request import urlopen
关于上述库的一些基本信息:
- NLTK 库: nltk 库是为处理以Python编程语言编写的英语语言而编写的库和程序的集合。
- urllib 库:这是一个用于Python的 URL 处理库。在这里了解更多
- BeautifulSoup 库:这是一个用于从 HTML 和 XML 文档中提取数据的库。
步骤#2:提取文本文件的所有内容。
raw = urlopen("https://www.w3.org/TR/PNG/iso_8859-1.txt").read()
因此,未处理的数据被加载到变量 raw 中。
第 3 步:接下来,我们处理数据以删除可能存在于“原始”变量中的任何 html/xml 标记,使用:
raw1 = BeautifulSoup(raw)
第 4 步:现在我们获取“原始”变量中的文本。
raw2 = raw1.get_text()
输出: 
步骤#5:接下来我们将文本标记为单词。
token = nltk.word_tokenize(raw2)
输出: 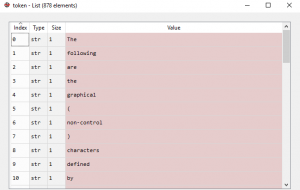
这是作为下一步的预处理完成的,我们将在其中获得最终文本。
步骤#6:最后,我们获得最终文本。
text2 = ' '.join(token)
输出:  下面是完整的代码:
下面是完整的代码:
# importing libraries
import nltk
from bs4 import BeautifulSoup
from urllib.request import urlopen
# extract all the contents of the text file.
raw = urlopen("https://www.w3.org/TR/PNG/iso_8859-1.txt").read()
# remove any html/xml tags
raw1 = BeautifulSoup(raw)
# obtain the text present in ‘raw’
raw2 = raw1.get_text()
# tokenize the text into words.
token = nltk.word_tokenize(raw2)
text2 = ' '.join(token)