NLP 中的词嵌入
什么是词嵌入?
它是一种表示单词和文档的方法。 Word Embedding 或 Word Vector 是一个数值向量输入,它代表低维空间中的一个词。它允许具有相似含义的单词具有相似的表示。它们也可以近似含义。一个有 50 个值的词向量可以表示 50 个独特的特征。
特征:任何将单词相互关联的东西。例如:Age、Sports、Fitness、Employed 等。每个词向量都有对应于这些特征的值。
词嵌入的目标
- 降低维度
- 用一个词来预测它周围的词
- 必须捕获词间语义
如何使用词嵌入?
- 它们被用作机器学习模型的输入。
取单词 —-> 给出它们的数字表示 —-> 用于训练或推理 - 表示或可视化用于训练它们的语料库中的任何潜在使用模式。
词嵌入的实现:
Word Embeddings 是一种从文本中提取特征的方法,以便我们可以将这些特征输入到机器学习模型中以处理文本数据。他们试图保留句法和语义信息。 Bag of Words(BOW)、CountVectorizer 和 TFIDF 等方法依赖于句子中的字数,但不保存任何句法或语义信息。在这些算法中,向量的大小是词汇表中元素的数量。如果大多数元素为零,我们可以获得一个稀疏矩阵。大输入向量将意味着大量的权重,这将导致训练所需的大量计算。 Word Embeddings 为这些问题提供了解决方案。
我们举个例子来理解词向量是如何生成的,将在特定条件下最常用的表情符号,将每个表情符号转化为向量,条件就是我们的特征。 Happy ???? ???? ???? Sad ???? ???? ???? Excited ???? ???? ???? Sick ???? ???? ????
The emoji vectors for the emojis will be:
[happy,sad,excited,sick]
???? =[1,0,1,0]
???? =[0,1,0,1]
???? =[0,0,1,1]
.....
以类似的方式,我们也可以根据给定的特征为不同的词创建词向量。具有相似向量的词最有可能具有相同的含义或用于传达相同的情感。
在本文中,我们将讨论获得 Word Embeddings 的两种不同方法:
1) Word2Vec:
在 Word2Vec 中,每个单词都被分配了一个向量。我们从随机向量或单热向量开始。
One-Hot 向量:向量中只有一位为 1 的表示。如果语料库中有 500 个词,那么向量长度将为 500。在为每个词分配向量后,我们取一个窗口大小并遍历整个语料库.当我们这样做时,有两种神经嵌入方法被使用:
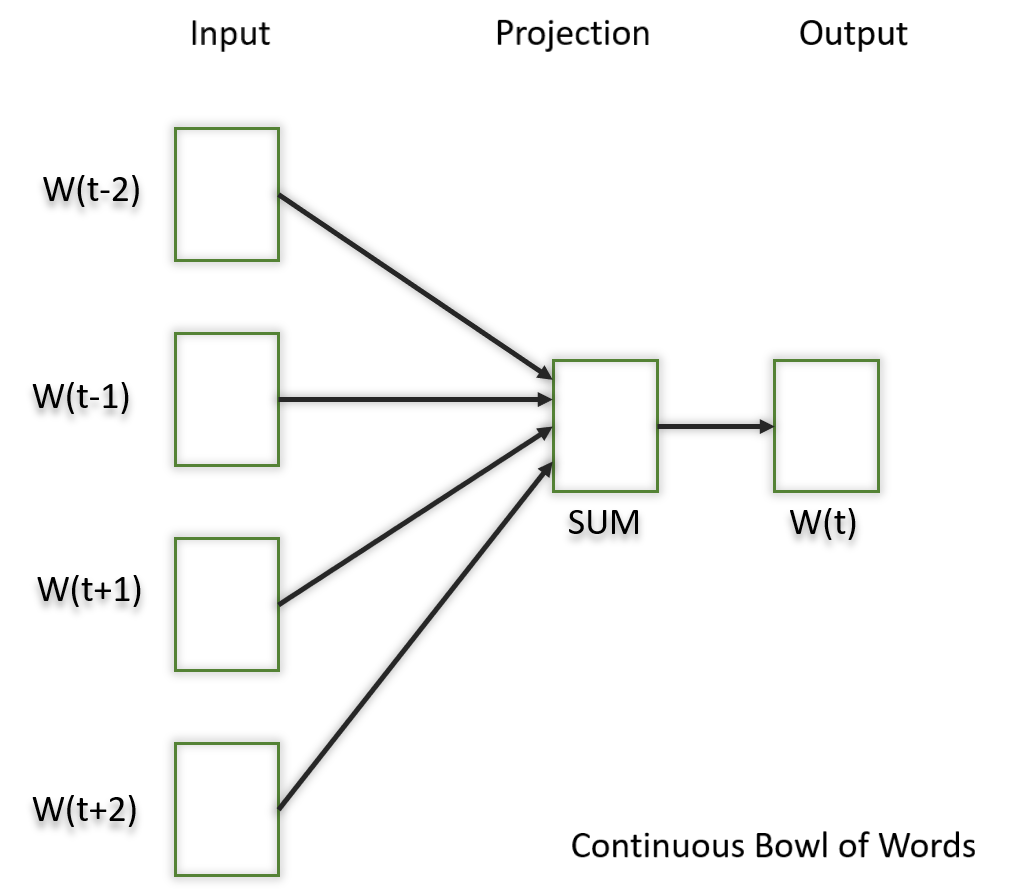
1.1) 连续碗词(CBOW)
在这个模型中,我们所做的是尝试将窗口中的相邻词与中心词相匹配。
1.2) 跳过 Gram
在这个模型中,我们尝试使中心词更接近相邻词。它与 CBOW 模型完全相反。结果表明,这种方法产生了更有意义的嵌入。

应用上述神经嵌入方法后,我们通过语料库多次迭代后得到每个词的训练向量。这些经过训练的向量保留句法或语义信息,并转换为较低的维度。具有相似含义或语义信息的向量在空间中彼此靠近放置。
2) 手套:
这是另一种创建词嵌入的方法。在这种方法中,我们获取语料库并对其进行迭代,并获得每个单词与语料库中其他单词的共现。我们通过这个得到一个共现矩阵。相邻出现的词的值为 1,如果它们相距一个词则为 1/2,如果相距两个词则为 1/3,依此类推。
让我们举个例子来理解矩阵是如何创建的。我们有一个小语料库:
Corpus:
It is a nice evening.
Good Evening!
Is it a nice evening?
| it | is | a | nice | evening | good | |
|---|---|---|---|---|---|---|
| it | 0 | |||||
| is | 1+1 | 0 | ||||
| a | 1/2+1 | 1+1/2 | 0 | |||
| nice | 1/3+1/2 | 1/2+1/3 | 1+1 | 0 | ||
| evening | 1/4+1/3 | 1/3+1/4 | 1/2+1/2 | 1+1 | 0 | |
| good | 0 | 0 | 0 | 0 | 1 | 0 |
矩阵的上半部分将是下半部分的反映。我们也可以考虑一个窗口框架,通过将框架移动到语料库的末尾来计算共现。这有助于收集有关使用该词的上下文的信息。
最初,每个词的向量是随机分配的。然后我们取两对向量,看看它们在空间中的距离有多近。如果它们更频繁地一起出现或在共现矩阵中具有更高的值并且在空间上相距很远,那么它们就会彼此靠近。如果它们彼此靠近但很少或不经常一起使用,则它们在空间中会移得更远。
经过上述过程的多次迭代,我们将得到一个向量空间表示,它近似于来自共现矩阵的信息。 GloVe 在语义和句法捕获方面的性能都优于 Word2Vec。
预训练的词嵌入模型:
人们通常使用预先训练的模型进行词嵌入。其中很少有:
- 空间
- 快速文本
- 风度等。
常见错误:
- 在部署模型期间,您需要使用与用于创建词嵌入训练数据完全相同的管道。如果您使用不同的标记器或处理空格、标点符号等的不同方法,您最终可能会遇到不兼容的输入。
- 输入中没有预训练向量的单词。这些词被称为词表外词(oov)。你可以做的是“UNK”取代那些话,这意味着未知,然后分别处理它们。
- 维度不匹配:向量可以有多种长度。如果您使用长度为 400 的向量训练模型,然后尝试在推理时应用长度为 1000 的向量,则会遇到错误。因此,请确保始终使用相同的尺寸。
使用 Word Embeddings 的好处:
- 训练比手动构建模型(如 WordNet(使用图嵌入))快得多
- 几乎所有现代 NLP 应用程序都从嵌入层开始
- 它存储了意义的近似值
词嵌入的缺点:
- 它可能是内存密集型的
- 它依赖于语料库。任何潜在的偏见都会对您的模型产生影响
- 它无法区分同音字。例如:刹车/休息、电池/卖出、天气/是否等。