- 信息检索中的问题
- 信息检索问题
- 信息检索问题(1)
- 信息检索中的问题(1)
- 什么是信息检索?
- 什么是信息检索?(1)
- nlp (1)
- nlp - 任何代码示例
- NLP的应用
- NLP的应用(1)
- nlp 中的转换器 - C++ (1)
- NLP 中的词嵌入(1)
- NLP 中的词嵌入
- 用于信息检索的嵌入匹配 (1)
- 网络信息检索|向量空间模型(1)
- 网络信息检索|向量空间模型
- nlp 中的转换器 - C++ 代码示例
- 信息检索与信息提取的区别(1)
- 信息检索与信息提取的区别
- 用于信息检索的嵌入匹配 - 无论代码示例
- nlp 的文本拆分器 - Python (1)
- NLP-语言资源
- NLP-语言资源(1)
- nlp 完整形式 (1)
- nlp 在 python 中生成解析树(1)
- 注意 nlp - C++ (1)
- Vent – 域信息检索工具(1)
- Vent – 域信息检索工具
- nlp 的文本拆分器 - Python 代码示例
📅 最后修改于: 2020-11-23 04:44:13 🧑 作者: Mango
信息检索(IR)可以定义为一种软件程序,用于处理,存储,检索和评估来自文档存储库(尤其是文本信息)中的信息。该系统可帮助用户找到他们所需的信息,但不会明确返回问题的答案。它告知可能包含所需信息的文档的存在和位置。满足用户要求的文件称为相关文件。完善的IR系统将仅检索相关文档。
借助下图,我们可以了解信息检索(IR)的过程-
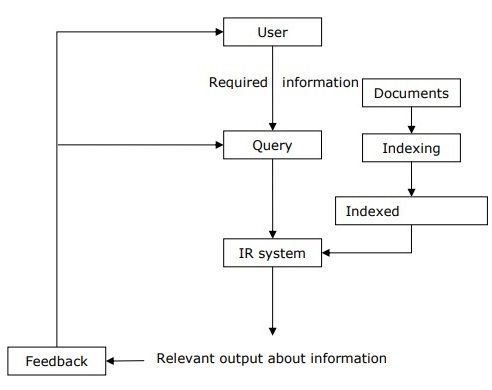
从上图可以清楚地看出,需要信息的用户将不得不以自然语言的查询形式提出请求。然后,IR系统将通过以文档形式检索有关所需信息的相关输出进行响应。
信息检索(IR)系统中的经典问题
IR研究的主要目标是开发一种用于从文档库中检索信息的模型。在这里,我们将讨论与IR系统相关的经典问题,即即席检索问题。
在临时检索中,用户必须以自然语言输入描述所需信息的查询。然后,IR系统将返回与所需信息有关的所需文件。例如,假设我们正在Internet上搜索某些内容,并且它给出了一些与我们的需求相关的确切页面,但是也可能存在一些不相关的页面。这是由于临时检索问题。
临时检索的各个方面
以下是IR研究中解决的即席检索的某些方面-
-
用户如何在相关性反馈的帮助下改善查询的原始格式?
-
如何实现数据库合并,即如何将来自不同文本数据库的结果合并到一个结果集中?
-
如何处理部分损坏的数据?哪些型号适合相同?
信息检索(IR)模型
在数学上,模型被用于许多科学领域,目的是理解现实世界中的某些现象。信息检索模型可以预测和解释用户会发现与给定查询相关的内容。 IR模型基本上是一种定义检索过程的上述方面的模式,并且由以下部分组成-
-
文件模型。
-
查询模型。
-
将查询与文档进行比较的匹配函数。
从数学上讲,检索模型包括-
D-文件代表。
R-查询的表示形式。
F -D,Q以及它们之间的关系的建模框架。
R(q,di) -一种相似性函数,根据查询对文档进行排序。也称为排名。
信息检索(IR)模型的类型
信息模型(IR)模型可以分为以下三个模型-
经典红外模型
这是最简单,易于实现的IR模型。该模型基于易于理解和理解的数学知识。布尔,向量和概率是三个经典的IR模型。
非经典IR模型
它与经典的IR模型完全相反。这种IR模型基于相似性,概率,布尔运算以外的原理。信息逻辑模型,情境理论模型和交互模型是非经典IR模型的示例。
替代红外模型
它是利用来自其他领域的某些特定技术对经典IR模型的增强。聚类模型,模糊模型和潜在语义索引(LSI)模型是替代IR模型的示例。
信息检索(IR)系统的设计功能
现在让我们了解红外系统的设计功能-
倒排索引
大多数IR系统的主要数据结构为倒排索引形式。我们可以将倒排索引定义为一种数据结构,该结构针对每个单词列出包含该索引的所有文档以及文档中出现的频率。它使搜索查询词的“匹配”变得容易。
停止单词消除
停用词是那些被认为不太可能对搜索有用的高频词。它们的语义权重较小。所有这类单词都在一个称为“停止列表”的列表中。例如,冠词“一”,“一个”,“该”和诸如“在”,“的”,“用于”,“在”等介词是停用词的示例。停止索引可以显着减小倒排索引的大小。根据Zipf定律,覆盖几十个单词的停止列表可使倒排索引的大小减少近一半。另一方面,有时取消停用词可能会导致消除对搜索有用的术语。例如,如果我们从“维生素A”中删除字母“ A”,那么它就没有意义。
抽干
词干分析是词法分析的简化形式,它是通过切掉单词的结尾来提取单词基本形式的启发式过程。例如,“笑”,“笑”,“笑”一词将被源于“笑”的根源。
在接下来的部分中,我们将讨论一些重要且有用的IR模型。
布尔模型
它是最古老的信息检索(IR)模型。该模型基于集合论和布尔代数,其中文档是术语集,而查询是术语的布尔表达式。布尔模型可以定义为-
-
D-一组单词,即文档中存在的索引术语。在此,每个项要么存在(1),要么不存在(0)。
-
Q-一个布尔表达式,其中各项是索引项,而运算符是逻辑乘积-AND,逻辑和-或和逻辑差-NOT
-
F-术语集以及文档集上的布尔代数
如果我们谈论相关性反馈,那么在布尔IR模型中,相关性预测可以定义如下-
-
R-当且仅当满足以下条件的文档被预测为与查询表达式相关:
(((𝑡𝑒𝑥𝑡˅𝑖𝑛𝑓𝑜𝑟𝑚𝑎𝑡𝑖𝑜𝑛)˄ ˄〜𝑡ℎ𝑒𝑜𝑟𝑦)
我们可以通过查询词来解释该模型,作为一组文档的明确定义。
例如,查询术语“经济”定义了用术语“经济”索引的文档集。
现在,将术语与布尔AND运算符组合后会得到什么结果?它将定义一个小于或等于任何单个术语的文档集的文档集。例如,使用术语“社交”和“经济”的查询将生成同时用这两个术语索引的文档集。换句话说,文档集与两个集的交集。
现在,将术语与布尔OR运算符组合后将得到什么结果?它将定义一个大于或等于任何单个术语的文档集的文档集。例如,术语查询“社会”或“经济”将产生的索引与任何术语集的文档文件“社会”或“经济”。换句话说,文档集与两个集的并集。
布尔模式的优点
布尔模型的优点如下-
-
最简单的模型,它基于集合。
-
易于理解和实施。
-
它只检索完全匹配
-
它给用户带来了对系统的控制感。
布尔模型的缺点
布尔模型的缺点如下-
-
模型的相似性函数是布尔值。因此,将不会有部分匹配。这可能会使用户感到烦恼。
-
在此模型中,布尔运算符的用法比关键单词的影响要大得多。
-
查询语言是表达性的,但也很复杂。
-
检索到的文档没有排名。
向量空间模型
由于布尔模型的上述缺点,Gerard Salton和他的同事提出了一个基于Luhn相似性准则的模型。卢恩(Luhn)制定的相似性标准指出:“在给定元素及其分布中达成一致的两种表达方式越多,它们代表相似信息的可能性就越高。”
考虑以下要点,以进一步了解向量空间模型-
-
索引表示形式(文档)和查询被视为嵌入在高维欧式空间中的向量。
-
文档向量与查询向量的相似性度量通常是它们之间角度的余弦值。
余弦相似性测度公式
余弦是归一化的点积,可以通过以下公式进行计算-
$$分数\ lgroup \ vec {d} \ vec {q} \ rgroup = \ frac {\ sum_ {k = 1} ^ m d_ {k} \ :. q_ {k}} {\ sqrt {\ sum_ {k = 1} ^ m \ lgroup d_ {k} \ rgroup ^ 2} \:。\ sqrt {\ sum_ {k = 1} ^ m} m \ lgroup q_ {k} \ rgroup ^ 2} $$
分数\ lgroup \ vec {d} \ vec {q} \ rgroup = 1 \:when \:d = q $$
$$ Score \ lgroup \ vec {d} \ vec {q} \ rgroup = 0 \:when \:d \:and \:q \:share \:no \:items $$
具有查询和文档的向量空间表示
查询和文档由二维向量空间表示。这些术语是汽车和保险。向量空间中只有一个查询和三个文档。
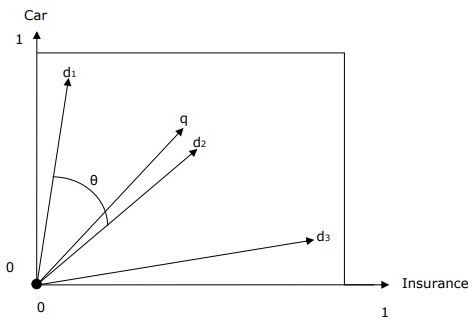
由于q和d 2之间的夹角最小,因此对术语car和insurance排名最高的文档将是文档d 2 。其背后的原因是汽车和保险这两个概念在d 2中都是显着的,因此权重很高。另一方面, d 1和d 3也提到了这两个术语,但是在每种情况下,它们中的一个都不是文档中的中心重要术语。
术语权重
术语权重是指向量空间中术语的权重。术语的权重越高,该术语对余弦的影响就越大。应将更多权重分配给模型中更重要的项。现在,这里出现的问题是如何建模。
一种实现方法是将文档中的单词作为其术语权重。但是,您认为这将是有效的方法吗?
另一种更有效的方法是使用术语频率(tf ij ),文档频率(df i )和收集频率(cf i ) 。
词频(tf ij )
可以将其定义为d j中w i的出现次数。术语频率捕获的信息是单词在给定文档中的显着性,换句话说,我们可以说术语频率越高,单词越能很好地说明该文档的内容。
文件频率(df i )
它可以定义为出现w i的集合中文档的总数。它是信息量的指标。与语义上没有重点的单词不同,语义集中的单词将在文档中出现几次。
收集频率(cf i )
它可以定义为集合中w i的出现总数。
数学上,$ df_ {i} \ leq cf_ {i} \:and \:\ sum_ {j} tf_ {ij} = cf_ {i} $
文件频率加权的形式
现在让我们了解文档频率加权的不同形式。表格描述如下-
词频因子
这也归为术语频率因子,这意味着如果术语t经常出现在文档中,则包含t的查询应检索该文档。我们可以将单词的词频(tf ij )和文档频率(df i )合并为一个权重,如下所示-
$$ weight \ left(i,j \ right)= \开始{cases}(1 + log(tf_ {ij}))log \ frac {N} {df_ {i}} \:if \:tf_ {i, j} \:\ geq1 \\ 0 \:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\ :\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:if \:tf_ {i,j} \:= 0 \ end {cases } $$
N是文档总数。
反文档频率(idf)
这是文档频率加权的另一种形式,通常称为idf加权或逆文档频率加权。 idf加权的重点在于,该术语在整个馆藏中的稀缺性是对其重要性的衡量标准,重要性与发生频率成反比。
数学上
$$ idf_ {t} = log \ left(1+ \ frac {N} {n_ {t}} \ right)$$
$$ idf_ {t} = log \ left(\ frac {N-n_ {t}} {n_ {t}} \ right)$$
这里,
N =馆藏中的文件
n t =包含术语t的文档
用户查询改进
任何信息检索系统的主要目标都必须是准确性-根据用户要求生成相关文档。但是,这里出现的问题是如何通过改善用户的查询形成样式来改善输出。当然,任何IR系统的输出都取决于用户的查询,格式正确的查询将产生更准确的结果。用户可以借助相关性反馈(任何IR模型的重要方面)来改善他/她的查询。
相关反馈
相关性反馈采用最初从给定查询返回的输出。此初始输出可用于收集用户信息,并知道该输出是否与执行新查询有关。反馈可以分类如下-
明确的反馈
它可以定义为从相关性评估者获得的反馈。这些评估者还将指出从查询中检索到的文档的相关性。为了提高查询检索性能,需要将相关反馈信息与原始查询进行插值。
系统的评估者或其他用户可以使用以下相关系统来明确指示相关性-
-
二进制相关性系统-该相关性反馈系统指示文档对于给定查询而言是相关(1)还是不相关(0)。
-
分级相关性系统-分级相关性反馈系统基于给定的查询,使用数字,字母或描述对分级进行指示,以指示文档的相关性。描述可以像“不相关”,“有点相关”,“非常相关”或“相关”。
隐式反馈
这是从用户行为推断出的反馈。该行为包括用户花费在查看文档上的时间,选择要查看的文档而不是查看文档,页面浏览和滚动操作等。隐式反馈的最佳示例之一是停留时间,它是如何衡量的方式用户花费大量时间查看搜索结果中链接到的页面。
伪反馈
也称为盲反馈。它提供了一种自动局部分析的方法。相关性反馈的手动部分在Pseudo相关性反馈的帮助下是自动化的,因此用户无需扩展交互即可获得改进的检索性能。此反馈系统的主要优点是,它不需要像显式相关性反馈系统那样的评估者。
考虑以下步骤以实现此反馈-
-
步骤1-首先,必须将初始查询返回的结果作为相关结果。相关结果的范围必须在前10-50个结果中。
-
步骤2-现在,使用术语频率(tf)-反向文档频率(idf)权重从文档中选择前20-30个术语。
-
步骤3-将这些术语添加到查询中并匹配返回的文档。然后返回最相关的文档。