- 机器学习中的层次聚类(1)
- 机器学习中的层次聚类
- 机器学习中的 DBSCAN 聚类 |基于密度的聚类
- 机器学习中的 DBSCAN 聚类 |基于密度的聚类(1)
- 机器学习 (1)
- 机器学习中的 P 值(1)
- C++中的机器学习
- C++中的机器学习(1)
- 机器学习中的 P 值
- 机器学习之K-means聚类算法
- 机器学习之K-means聚类算法(1)
- 机器学习 python (1)
- 机器学习 python 代码示例
- 机器学习 - 任何代码示例
- 机器学习-什么是P值(1)
- 机器学习-什么是P值
- 什么是机器学习?
- 在机器学习中什么是“i” (1)
- 什么是机器学习?(1)
- 学习 python 机器学习 - 任何代码示例
- 机器学习-什么是机器学习? -指导点
- 机器学习-什么是机器学习? -指导点(1)
- 机器学习算法
- 机器学习算法(1)
- Scikit学习-聚类方法(1)
- Scikit学习-聚类方法
- 使用Python机器学习-方法(1)
- 使用Python机器学习-方法
- 如何开始学习机器学习?
📅 最后修改于: 2020-09-29 01:25:51 🧑 作者: Mango
机器学习中的聚类
聚类或聚类分析是一种机器学习技术,用于对未标记的数据集进行分组。可以将其定义为“一种将数据点分为不同集群的方式,该集群由相似数据点组成。具有可能相似性的对象保留在与另一个组具有很少或没有相似性的组中。”
它通过在未标记的数据集中找到一些相似的模式(例如形状,大小,颜色,行为等)来进行操作,并根据这些相似模式的存在与否对其进行划分。
这是一种无监督的学习方法,因此没有为算法提供监督,并且处理未标记的数据集。
应用此群集技术后,将为每个群集或组提供一个群集ID。 ML系统可以使用此id简化大型和复杂数据集的处理。
聚类技术通常用于统计数据分析。
注意:聚类类似于分类算法,但是区别在于我们使用的数据集类型。在分类中,我们使用标记的数据集,而在聚类中,我们使用未标记的数据集。
示例:让我们通过Mall的真实示例来了解聚类技术:当我们访问任何购物中心时,我们可以观察到具有相似用法的事物被分组在一起。例如,T恤在一个区域中分组,而裤子在其他区域中分组,同样在蔬菜区域中,苹果,香蕉,芒果等在不同区域中分组,以便我们可以轻松地找到东西。聚类技术也以相同的方式工作。聚类的其他示例是根据主题对文档进行分组。
聚类技术可以广泛用于各种任务。此技术的一些最常见用法是:
- 市场细分
- 统计数据分析
- 社交网络分析
- 图像分割
- 异常检测等
除了这些常规用法外,Amazon在其推荐系统中使用它来根据过去的产品搜索提供推荐。 Netflix还根据观看历史记录使用此技术向用户推荐电影和网络连续剧。
下图说明了聚类算法的工作。我们可以看到不同的水果被分成几组具有相似特性的水果。
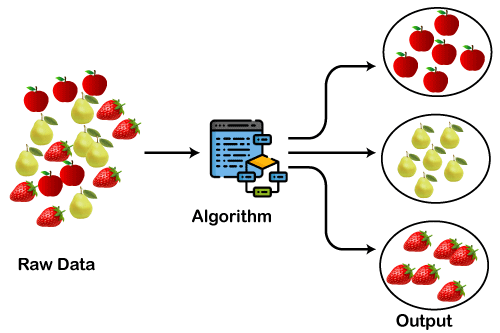
聚类方法的类型
聚类方法大致分为硬聚类(数据点仅属于一组)和软聚类(数据点也可以属于另一组)。但是也存在其他各种聚类方法。以下是机器学习中使用的主要聚类方法:
- 分区聚类
- 基于密度的聚类
- 基于分布模型的聚类
- 层次聚类
- 模糊聚类
分区聚类
这是一种将数据分为非分层组的群集。也称为基于质心的方法。分区聚类的最常见示例是K-Means聚类算法。
在这种类型中,数据集分为一组k组,其中K用于定义预定义组的数量。以这样的方式创建聚类中心:与另一个聚类质心相比,一个聚类的数据点之间的距离最小。

基于密度的聚类
基于密度的聚类方法将高密度区域连接成簇,并且只要可以连接密集区域,就可以形成任意形状的分布。该算法通过识别数据集中的不同聚类来实现,并将高密度区域连接到聚类中。数据空间中的密集区域由稀疏区域彼此分开。
如果数据集具有变化的密度和高维,则这些算法可能难以聚类数据点。

基于分布模型的聚类
在基于分布模型的聚类方法中,根据数据集如何属于特定分布的概率对数据进行划分。通过假设一些分布通常是高斯分布来完成分组。
这种类型的示例是使用高斯混合模型(GMM)的Expectation-Maximization Clustering算法。
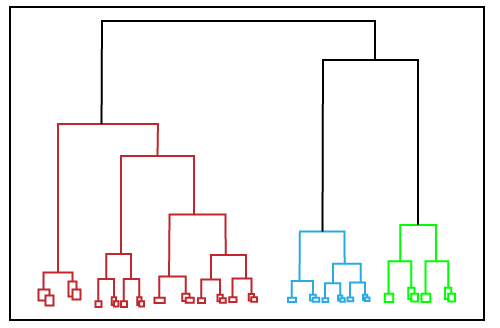
层次聚类
层次集群可以用作分区集群的替代方案,因为不需要预先指定要创建的集群数量。在这种技术中,数据集被分为簇以创建树状结构,也称为树状图。可以通过以正确级别切割树来选择观察值或任意数量的聚类。这种方法最常见的示例是聚集层次算法。
模糊聚类
模糊聚类是一种软方法,其中数据对象可能属于多个组或集群。每个数据集都有一组隶属系数,这取决于要在集群中的隶属程度。模糊C均值算法就是这种聚类的例子。有时也称为模糊k均值算法。
聚类算法
可以基于上述算法对聚类算法进行划分。已经发布了不同类型的聚类算法,但是只有少数几种是常用的。聚类算法基于我们正在使用的数据类型。例如,某些算法需要猜测给定数据集中的聚类数量,而某些算法需要找到数据集观测值之间的最小距离。
在这里,我们主要讨论在机器学习中广泛使用的流行的聚类算法:
- K均值算法: k均值算法是最流行的聚类算法之一。它通过将样本分为方差相等的不同聚类对数据集进行分类。必须在此算法中指定簇数。它的速度很快,所需的计算更少,线性复杂度为O(n)。
- 均值漂移算法:均值漂移算法试图在数据点的平滑密度中找到密集区域。这是基于质心的模型的一个示例,该模型用于将质心的候选更新为给定区域内点的中心。
- DBSCAN算法:代表具有噪声的应用程序的基于密度的空间聚类 。它是类似于均值漂移的基于密度的模型的示例,但具有一些显着的优势。在该算法中,高密度区域被低密度区域隔开。因此,可以发现任意形状的簇。
- 使用GMM的期望最大化聚类:此算法可用作k-means算法或K-means可能失败的情况的替代方法。在GMM中,假定数据点是高斯分布的。
- 聚集层次算法:聚集层次算法执行自下而上的层次聚类。在这种情况下,每个数据点从一开始就被视为单个群集,然后相继合并。群集层次结构可以表示为树结构。
- 相似性传播:它与其他聚类算法不同,因为它不需要指定聚类数。这样,每个数据点都会在一对数据点之间发送一条消息,直到收敛为止。它具有O(N 2 T)时间复杂度,这是该算法的主要缺点。
聚类的应用
以下是群集技术在机器学习中的一些常见应用:
- 在癌细胞的识别中:聚类算法被广泛用于癌细胞的识别。它将癌性和非癌性数据集分为不同的组。
- 在搜索引擎中:搜索引擎也可以使用聚类技术。搜索结果基于最接近搜索查询的对象出现。它通过将相似的数据对象分组到远离其他异类对象的一组中来实现。查询的准确结果取决于所使用的聚类算法的质量。
- 客户细分:市场研究中使用它来根据客户的选择和偏好对客户进行细分。
- 在生物学中:它在生物学流中使用图像识别技术对不同种类的动植物进行分类。
- 在“土地利用”中:聚类技术用于在GIS数据库中标识相似土地利用的区域。这对于发现应该将特定土地用于什么目的(这意味着更适合该目的)非常有用。