- scikit 学习树 - Python (1)
- python中的scikit学习库(1)
- python代码示例中的scikit学习库
- scikit 学习树 - Python 代码示例
- Scikit学习教程(1)
- Scikit学习教程
- Scikit学习-简介(1)
- Scikit学习-简介
- 机器学习中的聚类
- 机器学习中的聚类
- Scikit学习-增强方法(1)
- Scikit学习-增强方法
- 讨论Scikit学习
- 讨论Scikit学习(1)
- 机器学习-Scikit学习算法(1)
- 机器学习-Scikit学习算法
- scikit 学习岭回归 - Python (1)
- Scikit学习-KNN学习(1)
- Scikit学习-KNN学习
- scikit 学习岭回归 - Python 代码示例
- scikit 学习拆分数据集 - Python (1)
- Scikit学习-决策树
- Scikit学习-决策树(1)
- Scikit学习-有用的资源
- Scikit学习-有用的资源(1)
- Scikit学习-约定(1)
- Scikit学习-约定
- Scikit学习-异常检测
- Scikit学习-异常检测(1)
📅 最后修改于: 2020-12-10 05:57:27 🧑 作者: Mango
在这里,我们将研究Sklearn中的聚类方法,这将有助于识别数据样本中的任何相似性。
聚类方法是最有用的无监督ML方法之一,用于查找数据样本之间的相似性和关系模式。之后,他们将这些样本基于特征聚类为具有相似性的组。聚类决定了当前未标记数据之间的固有分组,这就是为什么它很重要。
Scikit-learn库具有sklearn.cluster以执行未标记数据的聚类。在这个模块下scikit-leran具有以下聚类方法-
均值
该算法计算质心并进行迭代,直到找到最佳质心为止。它要求指定簇的数量,这就是为什么它假定它们已经已知的原因。该算法的主要逻辑是,通过最小化称为惯性的标准,将分离样本的数据聚类为n个等方差组。用算法标识的簇数用’K表示。
Scikit-learn具有sklearn.cluster.KMeans模块来执行K-Means聚类。在计算聚类中心和惯性值时,名为sample_weight的参数允许sklearn.cluster.KMeans模块为某些样本分配更多的权重。
亲和力传播
该算法基于不同对样本之间的“消息传递”直到收敛的概念。在运行算法之前,不需要指定群集数。该算法的时间复杂度约为𝑂(𝑁2𝑇),这是其最大的缺点。
Scikit-learn具有sklearn.cluster.AffinityPropagation模块,以执行Affinity Propagation聚类。
均值漂移
该算法主要发现样本平滑密度中的斑点。它通过将数据点移向最高密度的数据点来将数据点迭代地分配给群集。它会自动设置簇数,而不是依靠一个称为带宽的参数来指示要搜索的区域的大小。
Scikit-learn具有sklearn.cluster.MeanShift模块来执行均值漂移聚类。
光谱聚类
在聚类之前,该算法基本上使用特征值,即数据相似矩阵的频谱,以较少的维数进行维数减少。当群集数量很多时,建议不要使用此算法。
Scikit-learn具有sklearn.cluster.SpectralClustering模块来执行光谱聚类。
层次聚类
该算法通过依次合并或拆分群集来构建嵌套群集。该群集层次结构表示为树状图,即树。它分为以下两类-
聚集层次算法-在这种层次算法中,每个数据点都被视为单个群集。然后,它连续聚集成对的集群。这使用了自下而上的方法。
划分层次算法-在此层次算法中,所有数据点都被视为一个大群集。在此过程中,群集过程涉及通过使用自上而下的方法将一个大群集分为多个小群集。
Scikit-learn具有sklearn.cluster.AgglomerativeClustering模块来执行聚集层次聚类。
数据库扫描
它代表“基于噪声的应用程序的基于密度的空间聚类” 。该算法基于“集群”和“噪声”的直观概念,即群集是数据空间中密度较低的密集区域,被数据点的密度较低的区域分隔开。
Scikit-learn具有sklearn.cluster.DBSCAN模块来执行DBSCAN集群。该算法使用两个重要参数,即min_samples和eps来定义稠密度。
参数min_samples的较高值或参数eps的较低值将指示有关形成群集所必需的较高数据点密度。
光学
它代表“订购点以识别聚类结构” 。该算法还可以在空间数据中找到基于密度的聚类。它的基本工作逻辑就像DBSCAN。
它解决了DBSCAN算法的一个主要弱点-通过以使空间上最近的点成为该次序中的邻居的方式对数据库的点进行排序来检测变化密度的数据中有意义的簇的问题。
Scikit-learn具有sklearn.cluster.OPTICS模块来执行OPTICS集群。
桦木
它代表使用层次结构的平衡迭代减少和聚类。它用于对大型数据集执行分层聚类。它为给定的数据构建一个名为CFT的树,即特征特征树。
CFT的优势在于,称为CF(特征功能)节点的数据节点拥有用于群集的必要信息,这进一步避免了将整个输入数据保存在内存中的需求。
Scikit-learn具有sklearn.cluster.Birch模块来执行BIRCH聚类。
比较聚类算法
下表将对scikit-learn中的聚类算法进行比较(基于参数,可伸缩性和度量)。
| Sr.No | Algorithm Name | Parameters | Scalability | Metric Used |
|---|---|---|---|---|
| 1 | K-Means | No. of clusters | Very large n_samples | The distance between points. |
| 2 | Affinity Propagation | Damping | It’s not scalable with n_samples | Graph Distance |
| 3 | Mean-Shift | Bandwidth | It’s not scalable with n_samples. | The distance between points. |
| 4 | Spectral Clustering | No.of clusters | Medium level of scalability with n_samples. Small level of scalability with n_clusters. |
Graph Distance |
| 5 | Hierarchical Clustering | Distance threshold or No.of clusters | Large n_samples Large n_clusters |
The distance between points. |
| 6 | DBSCAN | Size of neighborhood | Very large n_samples and medium n_clusters. | Nearest point distance |
| 7 | OPTICS | Minimum cluster membership | Very large n_samples and large n_clusters. | The distance between points. |
| 8 | BIRCH | Threshold, Branching factor | Large n_samples Large n_clusters |
The Euclidean distance between points. |
Scikit学习数字数据集的K均值聚类
在此示例中,我们将对数字数据集应用K-means聚类。该算法将在不使用原始标签信息的情况下识别相似的数字。在Jupyter笔记本上完成实现。
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import load_digits
digits = load_digits()
digits.data.shape
输出
1797, 64)
此输出显示数字数据集具有1797个具有64个特征的样本。
例
现在,按以下步骤执行K-Means聚类:
kmeans = KMeans(n_clusters = 10, random_state = 0)
clusters = kmeans.fit_predict(digits.data)
kmeans.cluster_centers_.shape
输出
(10, 64)
此输出显示K-means聚类创建了具有64个特征的10个聚类。
例
fig, ax = plt.subplots(2, 5, figsize = (8, 3))
centers = kmeans.cluster_centers_.reshape(10, 8, 8)
for axi, center in zip(ax.flat, centers):
axi.set(xticks = [], yticks = [])
axi.imshow(center, interpolation = 'nearest', cmap = plt.cm.binary)
输出
以下输出的图像显示了通过K-Means聚类学习的聚类中心。
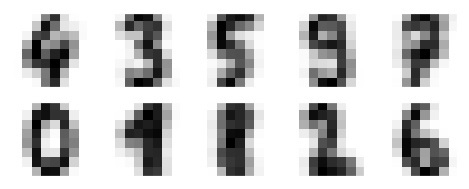
接下来,下面的Python脚本将匹配学习到的集群标签(通过K-Means)和在其中找到的真实标签-
from scipy.stats import mode
labels = np.zeros_like(clusters)
for i in range(10):
mask = (clusters == i)
labels[mask] = mode(digits.target[mask])[0]
我们还可以借助下面提到的命令检查准确性。
from sklearn.metrics import accuracy_score
accuracy_score(digits.target, labels)
输出
0.7935447968836951
完整的实施实例
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import load_digits
digits = load_digits()
digits.data.shape
kmeans = KMeans(n_clusters = 10, random_state = 0)
clusters = kmeans.fit_predict(digits.data)
kmeans.cluster_centers_.shape
fig, ax = plt.subplots(2, 5, figsize = (8, 3))
centers = kmeans.cluster_centers_.reshape(10, 8, 8)
for axi, center in zip(ax.flat, centers):
axi.set(xticks=[], yticks = [])
axi.imshow(center, interpolation = 'nearest', cmap = plt.cm.binary)
from scipy.stats import mode
labels = np.zeros_like(clusters)
for i in range(10):
mask = (clusters == i)
labels[mask] = mode(digits.target[mask])[0]
from sklearn.metrics import accuracy_score
accuracy_score(digits.target, labels)