- 机器学习中的聚类
- 机器学习中的聚类
- R 编程中的 K-Means 聚类
- R 编程中的 K-Means 聚类(1)
- Python 中的 K-Means 聚类 - 3 个聚类 - Python (1)
- Python 中的 K-Means 聚类 - 3 个聚类 - Python 代码示例
- k-means 聚类和禁用聚类 - Python 代码示例
- K means聚类Python–简介
- K means聚类Python–简介(1)
- 大数据分析-K-Means聚类(1)
- 大数据分析-K-Means聚类
- 机器学习算法(1)
- 机器学习算法
- 机器学习中的层次聚类(1)
- 机器学习中的层次聚类
- K-Means 和 DBScan 聚类之间的区别
- K-Means 和 DBScan 聚类之间的区别
- K-Means 和 DBScan 聚类之间的区别(1)
- 毫升 | Mini Batch K-means 聚类算法
- 毫升 | Mini Batch K-means 聚类算法(1)
- 机器学习中的 DBSCAN 聚类 |基于密度的聚类
- 机器学习中的 DBSCAN 聚类 |基于密度的聚类(1)
- 使用 K-means 聚类进行图像压缩
- 使用 K-means 聚类进行图像压缩(1)
- 机器学习中的 P 值
- 机器学习 (1)
- C++中的机器学习(1)
- C++中的机器学习
- 机器学习中的 P 值(1)
📅 最后修改于: 2020-09-29 01:29:39 🧑 作者: Mango
K均值聚类算法
K-Means聚类是一种无监督的学习算法,用于解决机器学习或数据科学中的聚类问题。在本主题中,我们将学习什么是K-means聚类算法,该算法如何工作以及k-means聚类的Python实现。
什么是K均值算法?
K均值聚类是一种无监督学习算法,可将未标记的数据集分为不同的聚类。这里K定义了在流程中需要创建的预定义集群的数量,就好像K = 2,将有两个集群,而对于K = 3,将有三个集群,依此类推。
它是一种迭代算法,将未标记的数据集划分为k个不同的簇,以使每个数据集仅属于一组具有相似属性的组。
它使我们可以将数据分为不同的组,并且可以方便地自行发现未标记数据集中的组类别,而无需进行任何培训。
这是一种基于质心的算法,其中每个聚类与质心相关联。该算法的主要目的是最大程度地减少数据点与其对应群集之间的距离之和。
该算法将未标记的数据集作为输入,将数据集划分为k个聚类,然后重复该过程,直到找不到最佳聚类为止。 k的值应在此算法中预先确定。
k均值聚类算法主要执行两个任务:
- 通过迭代过程确定K个中心点或质心的最佳值。
- 将每个数据点分配给最接近的k中心。那些靠近特定k中心的数据点将创建一个群集。
因此,每个群集具有具有某些共性的数据点,并且远离其他群集。
下图说明了K均值聚类算法的工作原理:
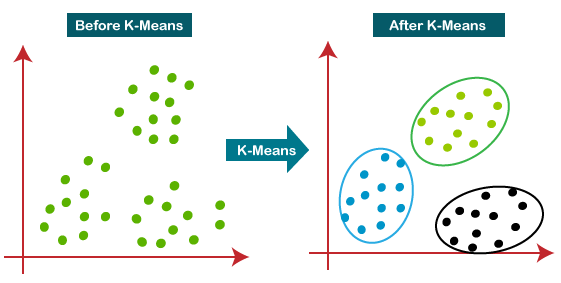
K均值算法如何工作?
以下步骤说明了K-Means算法的工作原理:
步骤1:选择数字K决定集群数。
步骤2:选择随机的K点或质心。 (可以是输入数据集中的其他)。
步骤3:将每个数据点分配给它们最接近的质心,这将形成预定义的K簇。
步骤4:计算方差并为每个群集放置一个新的质心。
步骤5:重复第三步,这意味着将每个数据点重新分配给每个群集的新的最接近的质心。
步骤6:如果发生任何重新分配,则转到步骤4,否则转到“完成”。
步骤7:模型准备就绪。
让我们通过考虑可视化图来了解上述步骤:
假设我们有两个变量M1和M2。这两个变量的xy轴散布图如下所示:
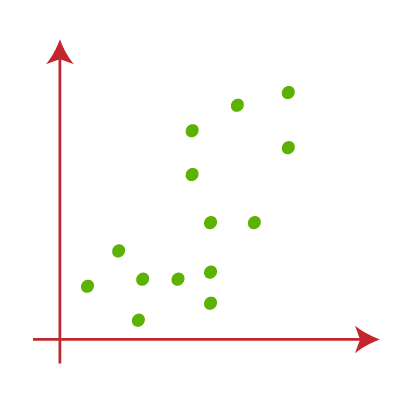
- 让我们以聚类的数量k(即K = 2)来识别数据集并将其放入不同的聚类中。这意味着在这里我们将尝试将这些数据集分为两个不同的集群。
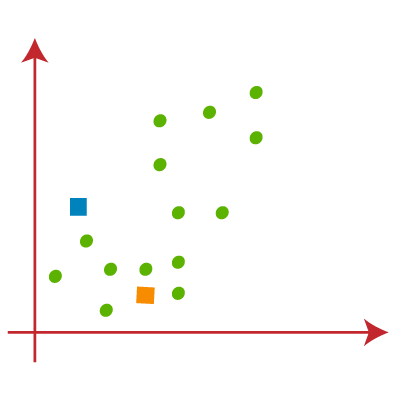
- 我们需要选择一些随机的k点或质心来形成聚类。这些点可以是数据集中的点,也可以是任何其他点。因此,这里我们选择以下两个点作为k点,这不是我们数据集的一部分。考虑下图:
- 现在,我们将散点图的每个数据点分配给最接近的K点或质心。我们将通过应用一些我们已经研究过的数学来计算两点之间的距离来进行计算。因此,我们将在两个质心之间绘制一个中间值。考虑下图:
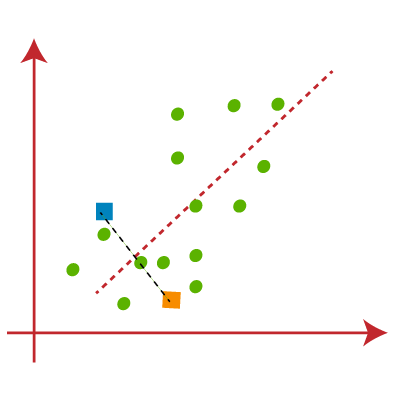
从上图可以清楚地看到,线的左侧点靠近K1或蓝色质心,而线的右侧点靠近黄色质心。让我们将它们涂成蓝色和黄色,以实现清晰的可视化。
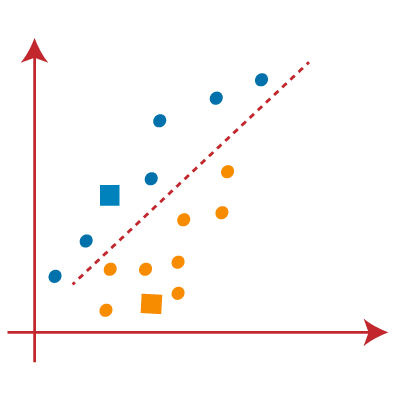
- 由于我们需要找到最接近的聚类,因此我们将通过选择一个新的质心来重复该过程。为了选择新的质心,我们将计算这些质心的重心,并找到如下的新质心:
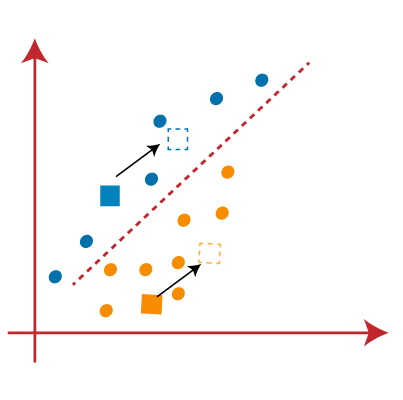
- 接下来,我们将每个数据点重新分配给新的质心。为此,我们将重复查找中线的相同过程。中位数将如下图所示:
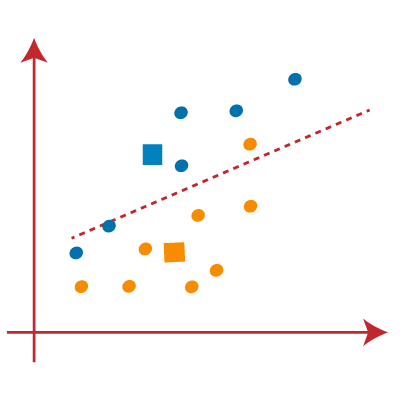
从上图中可以看到,线的左侧有一个黄色的点,线的右侧有两个蓝色的点。因此,这三个点将分配给新的质心。
重新分配已经完成,因此我们将再次进入第4步,即寻找新的质心或K点。
- 我们将通过找到质心的重心来重复此过程,因此新质心将如下图所示:
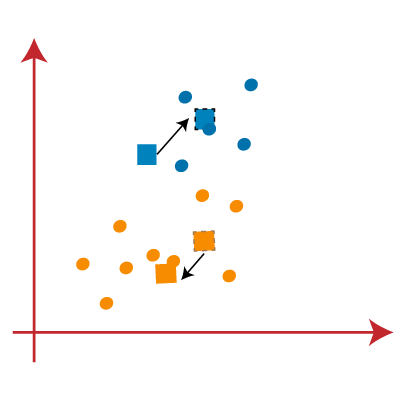
- 当我们得到新的质心时,将再次绘制中线并重新分配数据点。因此,图像将是:
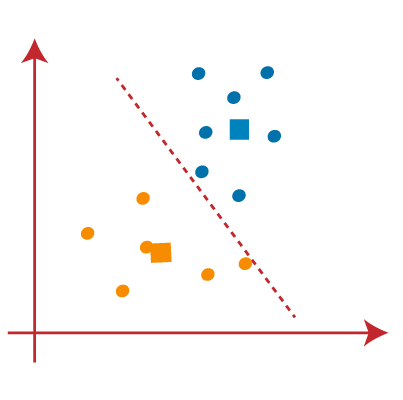
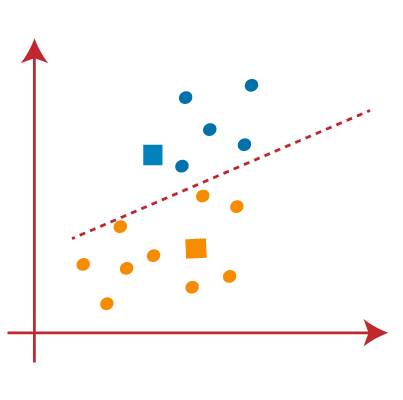
- 我们可以在上图中看到;线的两边没有不同的数据点,这意味着我们的模型已经形成。考虑下图:
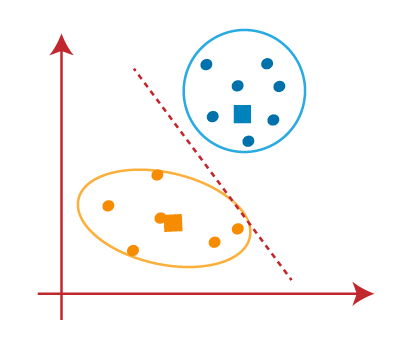
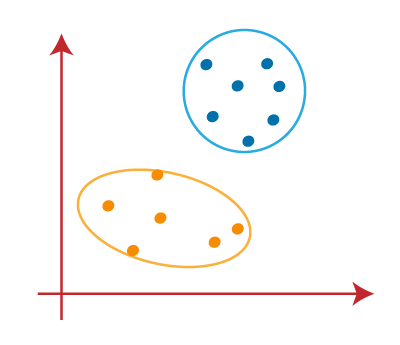
当我们的模型准备就绪时,现在我们可以删除假定的质心,两个最终聚类如下图所示:
如何在K均值聚类中选择“ K个簇数”的值?
K均值聚类算法的性能取决于它形成的高效聚类。但是,选择最佳数量的群集是一项艰巨的任务。有几种不同的方法可以找到最佳的聚类数,但是在这里我们讨论的是找到聚类数或K值的最合适方法。该方法如下:
肘法
Elbow方法是找到最佳簇数的最流行方法之一。此方法使用WCSS值的概念。 WCSS代表“群集内平方和”,它定义了群集内的总变化。下面给出了计算WCSS(针对3个群集)的值的公式:
在以上WCSS公式中,
Cluster1 distance(Pi C1)2中的∑Pi:它是Cluster1中每个数据点与其质心之间的距离的平方和,其他两项相同。
要测量数据点和质心之间的距离,我们可以使用任何方法,例如欧氏距离或曼哈顿距离。
为了找到群集的最佳值,弯头方法遵循以下步骤:
- 它针对不同的K值(范围为1-10)在给定的数据集上执行K-means聚类。
- 对于每个K值,计算WCSS值。
- 在计算的WCSS值和簇数K之间绘制曲线。
- 弯曲的锐利点或绘图中的点看起来像手臂,则该点被视为K的最佳值。
由于该图显示了急剧的弯曲,看起来像肘部,因此被称为肘部方法。弯头方法的图形如下图所示:
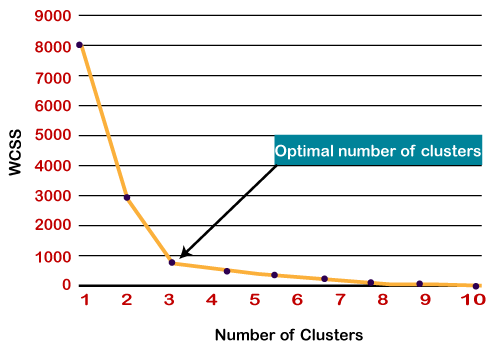
注意:我们可以选择等于给定数据点的簇数。如果我们选择等于数据点的聚类数,那么WCSS的值将变为零,这将是图形的终点。
K-means聚类算法的Python实现
在上一节中,我们讨论了K-means算法,现在让我们看看如何使用Python来实现它。
在实施之前,让我们了解一下我们将在这里解决什么类型的问题。因此,我们有一个Mall_Customers数据集,该数据集是访问购物中心并在此购物的顾客的数据。
在给定的数据集中,我们具有Customer_Id,性别,年龄,年收入($)和支出得分(这是客户在购物中心消费的金额的计算值,该值越大,他消费的金额就越多) 。从此数据集中,我们需要计算一些模式,因为它是一种无监督的方法,因此我们不知道确切计算什么。
实施步骤如下:
- 数据预处理
- 用弯头法找到最佳的簇数
- 在训练数据集上训练K-means算法
- 可视化集群
步骤1:数据预处理步骤
第一步将是数据预处理,就像我们在较早的回归和分类主题中所做的那样。但是对于聚类问题,它将与其他模型不同。让我们讨论一下:
- 导入库
正如我们在前面的主题中所做的一样,首先,我们将导入模型的库,这是数据预处理的一部分。代码如下:
# importing libraries
import numpy as nm
import matplotlib.pyplot as mtp
import pandas as pd
在上面的代码中,我们为执行数学计算而导入的numpy,matplotlib用于绘制图形,pandas用于管理数据集。
- 导入数据集:
接下来,我们将导入我们需要使用的数据集。因此,在这里,我们使用Mall_Customer_data.csv数据集。可以使用以下代码导入:
# Importing the dataset
dataset = pd.read_csv('Mall_Customers_data.csv')
通过执行上述代码,我们将在Spyder IDE中获得数据集。数据集如下图所示:

从上面的数据集中,我们需要在其中找到一些模式。
- 提取自变量
在这里,我们不需要任何因变量来进行数据预处理,因为这是一个聚类问题,我们也不知道要确定什么。因此,我们只需要为要素矩阵添加一行代码即可。
x = dataset.iloc[:, [3, 4]].values
如我们所见,我们仅提取第三和第四特征。这是因为我们需要一个二维图来可视化模型,并且不需要某些功能,例如customer_id。
步骤2:使用弯头法找到最佳的簇数
在第二步中,我们将尝试为我们的聚类问题找到最佳的聚类数量。因此,如上所述,这里我们将使用弯头方法。
众所周知,弯头方法使用WCSS概念通过在Y轴上绘制WCSS值和在X轴上绘制簇数来绘制图。因此,我们将计算从1到10的k个值的WCSS值。下面是代码:
#finding optimal number of clusters using the elbow method
from sklearn.cluster import KMeans
wcss_list= [] #Initializing the list for the values of WCSS
#Using for loop for iterations from 1 to 10.
for i in range(1, 11):
kmeans = KMeans(n_clusters=i, init='k-means++', random_state= 42)
kmeans.fit(x)
wcss_list.append(kmeans.inertia_)
mtp.plot(range(1, 11), wcss_list)
mtp.title('The Elobw Method Graph')
mtp.xlabel('Number of clusters(k)')
mtp.ylabel('wcss_list')
mtp.show()
从上面的代码中可以看到,我们使用了sklearn的KMeans类。集群库形成集群。
接下来,我们创建了wcss_list变量以初始化一个空列表,该空列表用于包含针对k的不同值(从1到10)计算的wcss值。
之后,我们在1到10的k值上初始化了for循环以进行迭代。由于Python的 for循环排除了出站限制,因此将第十个值视为11。
代码的其余部分与我们在前面的主题中所做的相似,因为我们已将模型拟合到特征矩阵上,然后在簇数和WCSS之间绘制了图表。
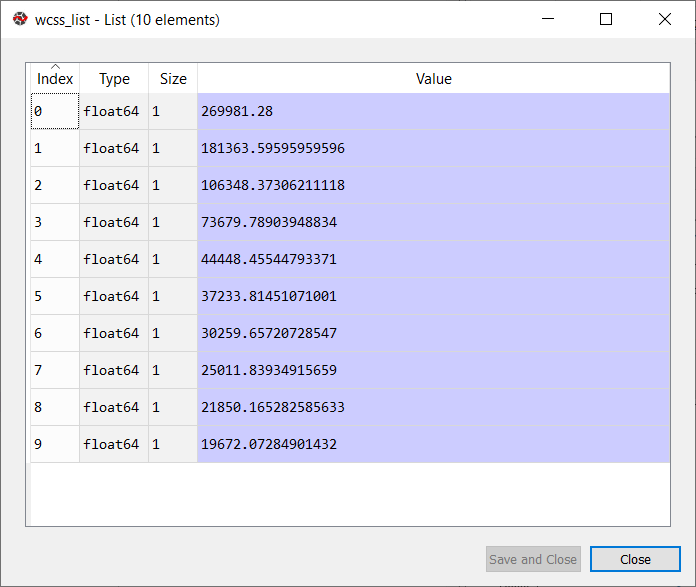
输出:执行上述代码后,我们将获得以下输出:
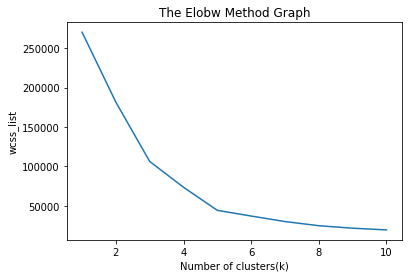
从上面的图中,我们可以看到弯头在5。所以这里的簇数将是5。
步骤3:在训练数据集上训练K-means算法
由于有了聚类的数量,因此我们现在可以在数据集上训练模型。
为了训练模型,我们将使用与上一节相同的两行代码,但是在这里,我们将使用5,而不是使用i,因为我们知道需要形成5个簇。代码如下:
#training the K-means model on a dataset
kmeans = KMeans(n_clusters=5, init='k-means++', random_state= 42)
y_predict= kmeans.fit_predict(x)
第一行与上面创建KMeans类的对象相同。
在第二行代码中,我们创建了因变量y_predict来训练模型。
通过执行以上代码行,我们将获得y_predict变量。我们可以在Spyder IDE中的变量资源管理器选项下对其进行检查。现在,我们可以将y_predict的值与原始数据集进行比较。考虑下图:
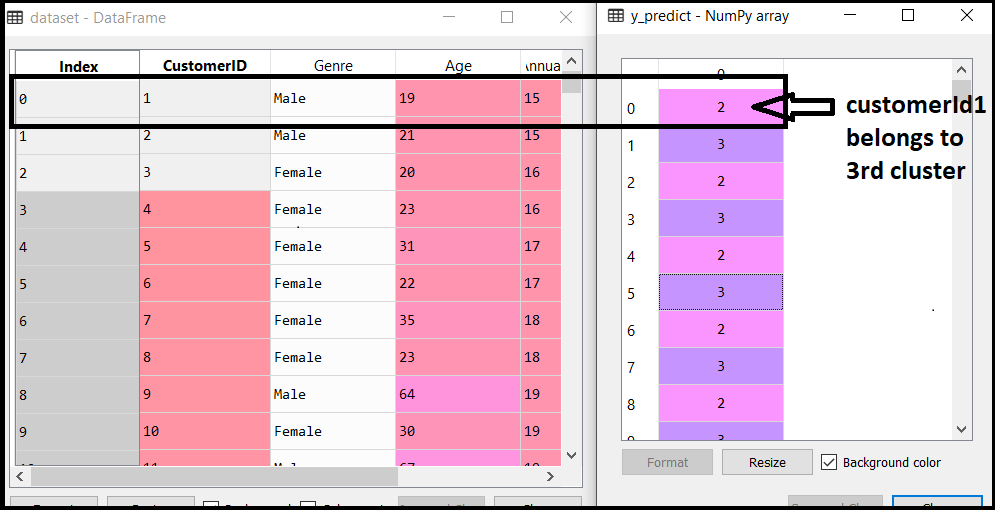
从上图可以看出,CustomerID 1属于一个集群
3(因为索引从0开始,因此2将被视为3),并且2属于群集4,依此类推。
步骤4:可视化群集
最后一步是可视化群集。由于我们的模型有5个聚类,因此我们将逐个可视化每个聚类。
为了可视化群集,将使用散点图,使用matplotlib的mtp.scatter() 函数 。
#visulaizing the clusters
mtp.scatter(x[y_predict == 0, 0], x[y_predict == 0, 1], s = 100, c = 'blue', label = 'Cluster 1') #for first cluster
mtp.scatter(x[y_predict == 1, 0], x[y_predict == 1, 1], s = 100, c = 'green', label = 'Cluster 2') #for second cluster
mtp.scatter(x[y_predict== 2, 0], x[y_predict == 2, 1], s = 100, c = 'red', label = 'Cluster 3') #for third cluster
mtp.scatter(x[y_predict == 3, 0], x[y_predict == 3, 1], s = 100, c = 'cyan', label = 'Cluster 4') #for fourth cluster
mtp.scatter(x[y_predict == 4, 0], x[y_predict == 4, 1], s = 100, c = 'magenta', label = 'Cluster 5') #for fifth cluster
mtp.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s = 300, c = 'yellow', label = 'Centroid')
mtp.title('Clusters of customers')
mtp.xlabel('Annual Income (k$)')
mtp.ylabel('Spending Score (1-100)')
mtp.legend()
mtp.show()
在上面的代码行中,我们为每个群集编写了代码,范围从1到5。mtp.scatter的第一个坐标,即x [y_predict == 0,0],包含用于显示矩阵的x值特征值,并且y_predict的范围是0到1。
输出:
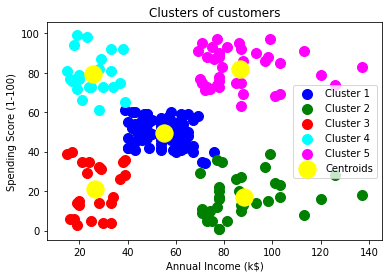
输出图像清楚地显示了五个具有不同颜色的不同群集。聚类在数据集的两个参数之间形成。客户的年收入和支出。我们可以根据要求或选择更改颜色和标签。我们还可以从上述模式中观察到以下几点:
- Cluster1向客户显示平均薪水和平均支出,因此我们可以将这些客户分类为
- Cluster2显示客户的收入很高,但支出却很低,因此我们可以将其归类为“ 谨慎” 。
- Cluster3显示了低收入和低支出,因此可以将其归类为明智的。
- Cluster4显示了低收入,高支出的客户,因此可以将其归类为粗心 。
- Cluster5向客户显示了高收入和高支出的客户,因此可以将其归类为目标客户,并且这些客户可能是购物中心所有者最赚钱的客户。