LSTM(长期短期记忆)是RNN(递归神经网络)的一种,这是一种著名的深度学习算法,非常适合于随时间变化进行预测和分类。在本文中,我们将通过时间推导算法的反向传播,并找到特定时间戳下所有权重的梯度值。
顾名思义,经过时间的反向传播类似于DNN(深度神经网络)中的反向传播,但是由于RNN和LSTM中时间的依赖性,我们将不得不应用具有时间依赖性的链规则。
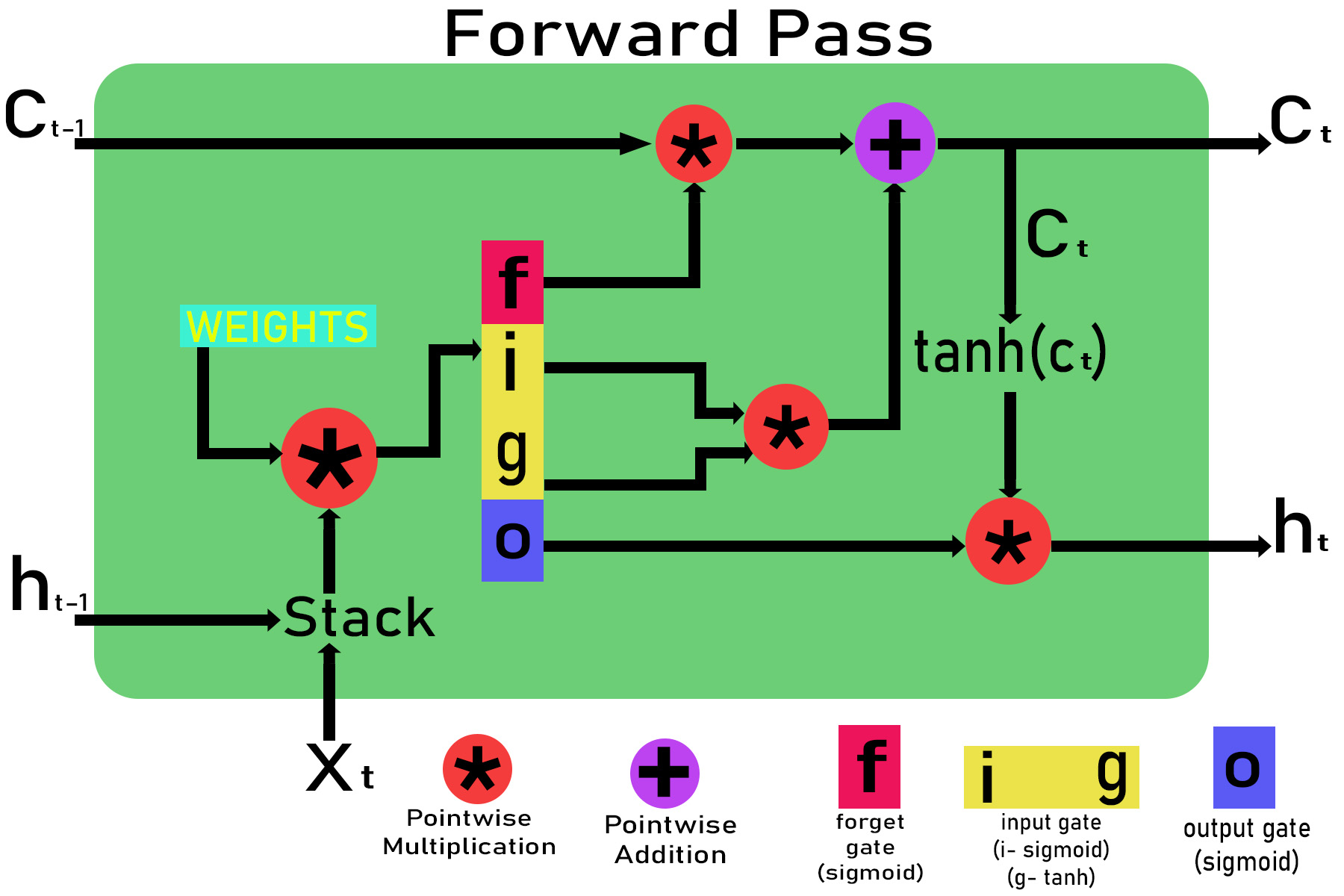
假设LSTM单元中时间t的输入为x t ,时间t-1和t的单元状态为c t-1和c t ,时间t-1和t的输出为h t-1和h t 。在t = 0时,c t和h t的初始值为零。
步骤1:权重的初始化。
Weights for different gates are :
Input gate : wxi, wxg, bi, whj, wg , bg
Forget gate : wxf, bf, whf
Output gate : wxo, bo, who
第2步:穿过不同的大门。
Inputs: xt and ht-i , ct-1 are given to the LSTM cell
Passing through input gate:
Zg = wxg *x + whg * ht-1 + bg
g = tanh(Zg)
Zj = wxi * x + whi * ht-1 + bi
i = sigmoid(Zi)
Input_gate_out = g*i
Passing through forget gate:
Zf = wxf * x + whf *ht-1 + bf
f = sigmoid(Zf)
Forget_gate_out = f
Passing through the output gate:
Zo = wxo*x + who * ht-1 + bo
o = sigmoid(zO)
Out_gate_out = o
步骤3:计算输出h t和当前电池状态c t。
Calculating the current cell state ct :
ct = (ct-1 * forget_gate_out) + input_gate_out
Calculating the output gate ht:
ht=out_gate_out * tanh(ct)
步骤4:使用链法则计算时间戳t处时间的反向传播梯度。
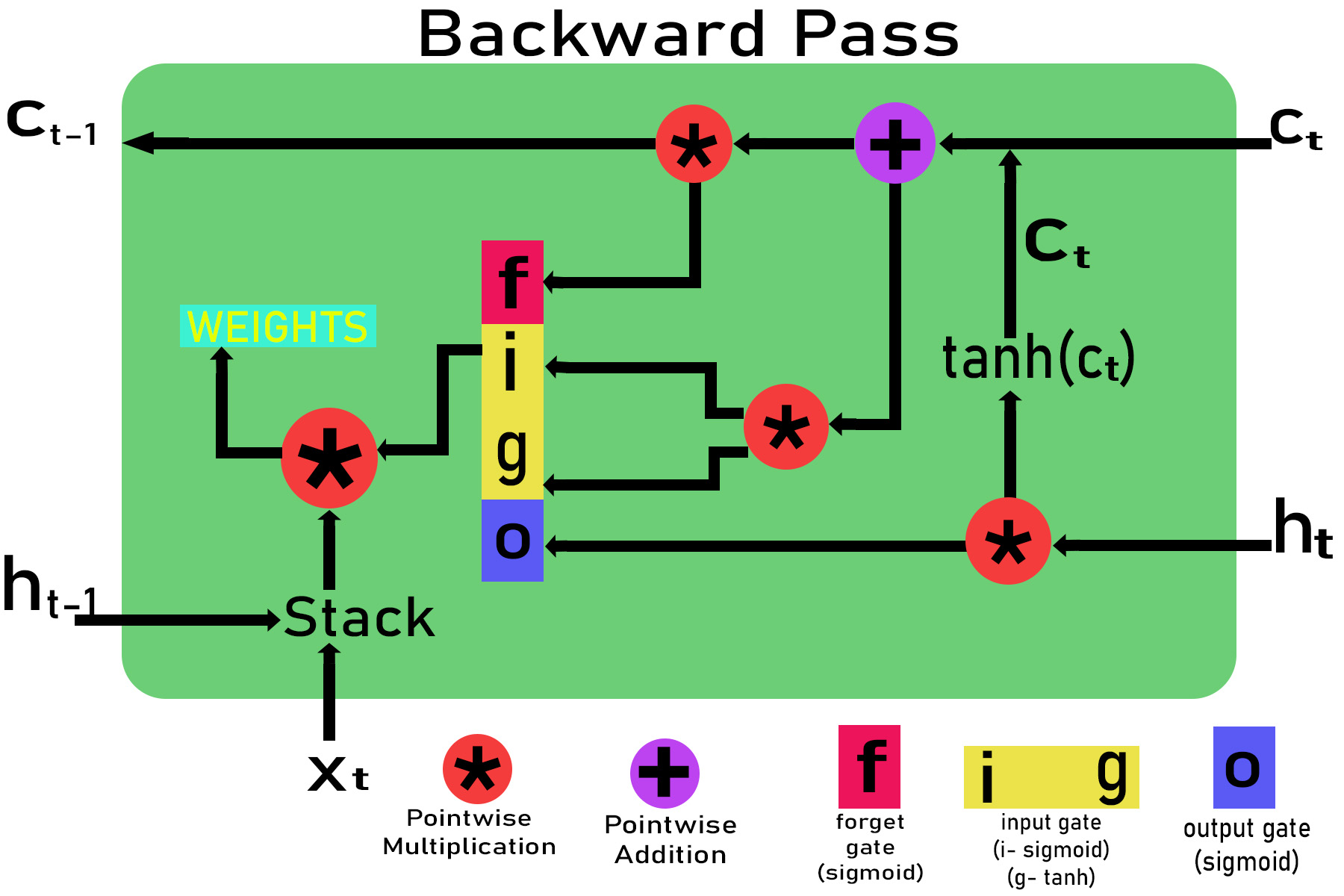
Let the gradient pass down by the above cell be:
E_delta = dE/dht
If we are using MSE (mean square error)for error then,
E_delta=(y-h(x))
Here y is the orignal value and h(x) is the predicted value.
Gradient with respect to output gate
dE/do = (dE/dht ) * (dht /do) = E_delta * ( dht / do)
dE/do = E_delta * tanh(ct)
Gradient with respect to ct
dE/dct = (dE / dht )*(dht /dct)= E_delta *(dht /dct)
dE/dct = E_delta * o * (1-tanh2 (ct))
Gradient with respect to input gate dE/di, dE/dg
dE/di = (dE/di ) * (dct / di)
dE/di = E_delta * o * (1-tanh2 (ct)) * g
Similarly,
dE/dg = E_delta * o * (1-tanh2 (ct)) * i
Gradient with respect to forget gate
dE/df = E_delta * (dE/dct ) * (dct / dt) t
dE/df = E_delta * o * (1-tanh2 (ct)) * ct-1
Gradient with respect to ct-1
dE/dct = E_delta * (dE/dct ) * (dct / dct-1)
dE/dct = E_delta * o * (1-tanh2 (ct)) * f
Gradient with respect to output gate weights:
dE/dwxo = dE/do *(do/dwxo) = E_delta * tanh(ct) * sigmoid(zo) * (1-sigmoid(zo) * xt
dE/dwho = dE/do *(do/dwho) = E_delta * tanh(ct) * sigmoid(zo) * (1-sigmoid(zo) * ht-1
dE/dbo = dE/do *(do/dbo) = E_delta * tanh(ct) * sigmoid(zo) * (1-sigmoid(zo)
Gradient with respect to forget gate weights:
dE/dwxf = dE/df *(df/dwxf) = E_delta * o * (1-tanh2 (ct)) * ct-1 * sigmoid(zf) * (1-sigmoid(zf) * xt
dE/dwhf = dE/df *(df/dwhf) = E_delta * o * (1-tanh2 (ct)) * ct-1 * sigmoid(zf) * (1-sigmoid(zf) * ht-1
dE/dbo = dE/df *(df/dbo) = E_delta * o * (1-tanh2 (ct)) * ct-1 * sigmoid(zf) * (1-sigmoid(zf)
Gradient with respect to input gate weights:
dE/dwxi = dE/di *(di/dwxi) = E_delta * o * (1-tanh2 (ct)) * g * sigmoid(zi) * (1-sigmoid(zi) * xt
dE/dwhi = dE/di *(di/dwhi) = E_delta * o * (1-tanh2 (ct)) * g * sigmoid(zi) * (1-sigmoid(zi) * ht-1
dE/dbi = dE/di *(di/dbi) = E_delta * o * (1-tanh2 (ct)) * g * sigmoid(zi) * (1-sigmoid(zi)
dE/dwxg = dE/dg *(dg/dwxg) = E_delta * o * (1-tanh2 (ct)) * i * (1?tanh2(zg))*xt
dE/dwhg = dE/dg *(dg/dwhg) = E_delta * o * (1-tanh2 (ct)) * i * (1?tanh2(zg))*ht-1
dE/dbg = dE/dg *(dg/dbg) = E_delta * o * (1-tanh2 (ct)) * i * (1?tanh2(zg))
最后,与权重相关的梯度是

使用所有梯度,我们可以轻松更新与输入门,输出门和忘记门相关的权重