- Keras-使用LSTM RNN进行时间序列预测(1)
- Keras-使用LSTM RNN进行时间序列预测
- 时间序列-LSTM模型(1)
- 时间序列-LSTM模型
- pytorch 预测 - Python (1)
- lstm pytorch 文档 (1)
- pytorch 预测 - Python 代码示例
- lstm pytorch 文档 - 任何代码示例
- 如何在 r 中进行预测 (1)
- 输入 lstm - Python 代码示例
- pytorch 预测 conda (1)
- pytorch 预测 conda - 任何代码示例
- automl 时间序列预测 - Python (1)
- 时间序列Python库(1)
- 时间序列Python库
- Python时间序列
- Python时间序列(1)
- automl 时间序列预测 - Python 代码示例
- 如何在 r 中进行预测 - 无论代码示例
- Python|时间序列预测的 ARIMA 模型
- Python|时间序列预测的 ARIMA 模型(1)
- PyTorch预测和线性分类
- PyTorch预测和线性分类(1)
- pytorch 逆 - Python (1)
- pytorch 1.7 - Python (1)
- 使用双向 LSTM 进行情绪检测
- 使用双向 LSTM 进行情绪检测(1)
- 理解 LSTM 网络
- 理解 LSTM 网络(1)
📅 最后修改于: 2020-09-06 07:56:47 🧑 作者: Mango
顾名思义,时间序列数据是随时间变化的一种数据类型。例如,24小时内的温度,一个月内各种产品的价格,一年中特定公司的股票价格。诸如长期短期记忆网络(LSTM)之类的高级深度学习模型能够捕获时间序列数据中的模式,因此可用于对数据的未来趋势进行预测。在本文中,您将看到如何使用LSTM算法使用时间序列数据进行将来的预测。
在我以前的一篇文章中,我解释了如何使用Keras库中的LSTM执行时间序列分析以预测未来的股票价格。在本文中,我们将使用PyTorch库,它是深度学习最常用的Python库之一。
在继续之前,假定您已精通Python编程语言,并且已安装PyTorch库。此外,基本机器学习概念和深度学习概念的知识也会有所帮助。如果尚未安装PyTorch,则可以使用以下pip命令进行安装:
$ pip install pytorch数据集和问题定义
我们将使用的数据集是Python Seaborn Library内置的。让我们先导入所需的库,然后再导入数据集:
import torch
import torch.nn as nn
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline让我们打印Seaborn库内置的所有数据集的列表:
sns.get_dataset_names()输出:
['anscombe',
'attention',
'brain_networks',
'car_crashes',
'diamonds',
'dots',
'exercise',
'flights',
'fmri',
'gammas',
'iris',
'mpg',
'planets',
'tips',
'titanic'] 我们将使用的flights数据集是数据集。让我们将数据集加载到我们的应用程序中,看看它的外观:
flight_data = sns.load_dataset("flights")
flight_data.head()输出:
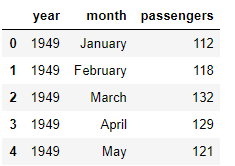
该数据集有三列:year,month,和passengers。该passengers列包含指定月份的旅行乘客总数。让我们绘制数据集的形状:
flight_data.shape输出:
(144, 3)您可以看到数据集中有144行和3列,这意味着数据集包含12年的乘客旅行记录。
任务是根据前132个月来预测最近12个月内旅行的乘客数量。请记住,我们有144个月的记录,这意味着前132个月的数据将用于训练我们的LSTM模型,而模型性能将使用最近12个月的值进行评估。
让我们绘制每月乘客的出行频率。以下脚本增加了默认图大小:
fig_size = plt.rcParams["figure.figsize"]
fig_size[0] = 15
fig_size[1] = 5
plt.rcParams["figure.figsize"] = fig_size接下来的脚本绘制了每月乘客人数的频率:
plt.title('Month vs Passenger')
plt.ylabel('Total Passengers')
plt.xlabel('Months')
plt.grid(True)
plt.autoscale(axis='x',tight=True)
plt.plot(flight_data['passengers'])输出:

输出显示,多年来,乘飞机旅行的平均乘客人数有所增加。一年内旅行的乘客数量波动,这是有道理的,因为在暑假或寒假期间,旅行的乘客数量与一年中的其他部分相比有所增加。
数据预处理
数据集中的列类型为object,如以下代码所示:
flight_data.columns输出:
Index(['year', 'month', 'passengers'], dtype='object')第一步是将passengers列的类型更改为float。
all_data = flight_data['passengers'].values.astype(float)现在,如果您打印all_datanumpy数组,则应该看到以下浮动类型值:
print(all_data)输出:
[112. 118. 132. 129. 121. 135. 148. 148. 136. 119. 104. 118. 115. 126.
141. 135. 125. 149. 170. 170. 158. 133. 114. 140. 145. 150. 178. 163.
172. 178. 199. 199. 184. 162. 146. 166. 171. 180. 193. 181. 183. 218.
230. 242. 209. 191. 172. 194. 196. 196. 236. 235. 229. 243. 264. 272.
237. 211. 180. 201. 204. 188. 235. 227. 234. 264. 302. 293. 259. 229.
203. 229. 242. 233. 267. 269. 270. 315. 364. 347. 312. 274. 237. 278.
284. 277. 317. 313. 318. 374. 413. 405. 355. 306. 271. 306. 315. 301.
356. 348. 355. 422. 465. 467. 404. 347. 305. 336. 340. 318. 362. 348.
363. 435. 491. 505. 404. 359. 310. 337. 360. 342. 406. 396. 420. 472.
548. 559. 463. 407. 362. 405. 417. 391. 419. 461. 472. 535. 622. 606.
508. 461. 390. 432.]接下来,我们将数据集分为训练集和测试集。LSTM算法将在训练集上进行训练。然后将使用该模型对测试集进行预测。将预测结果与测试集中的实际值进行比较,以评估训练模型的性能。
前132条记录将用于训练模型,后12条记录将用作测试集。以下脚本将数据分为训练集和测试集。
test_data_size = 12
train_data = all_data[:-test_data_size]
test_data = all_data[-test_data_size:]现在让我们打印测试和训练集的长度:
print(len(train_data))
print(len(test_data))输出:
132
12如果现在打印测试数据,您将看到它包含all_datanumpy数组中的最后12条记录:
print(test_data)输出:
[417. 391. 419. 461. 472. 535. 622. 606. 508. 461. 390. 432.]我们的数据集目前尚未规范化。最初几年的乘客总数远少于后来几年的乘客总数。标准化数据以进行时间序列预测非常重要。我们将对数据集执行最小/最大缩放,以在一定范围的最小值和最大值之间对数据进行规范化。我们将使用模块中的MinMaxScaler类sklearn.preprocessing来扩展数据。有关最小/最大缩放器实现的更多详细信息,请访问此链接。
以下代码使用最小/最大缩放器分别将最小值和最大值分别为-1和1归一化。
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(-1, 1))
train_data_normalized = scaler.fit_transform(train_data .reshape(-1, 1))现在,让我们打印归一化火车数据的前5条记录和最后5条记录。
print(train_data_normalized[:5])
print(train_data_normalized[-5:])输出:
[[-0.96483516]
[-0.93846154]
[-0.87692308]
[-0.89010989]
[-0.92527473]]
[[1. ]
[0.57802198]
[0.33186813]
[0.13406593]
[0.32307692]]您可以看到数据集值现在在-1和1之间。
在此重要的是要提到数据标准化仅应用于训练数据,而不应用于测试数据。如果对测试数据进行归一化,则某些信息可能会从训练集中泄漏到测试集中。
下一步是将我们的数据集转换为张量,因为PyTorch模型是使用张量训练的。要将数据集转换为张量,我们可以简单地将数据集传递给FloatTensor对象的构造函数,如下所示:
train_data_normalized = torch.FloatTensor(train_data_normalized).view(-1)最后的预处理步骤是将我们的训练数据转换为序列和相应的标签。
您可以使用任何序列长度,这取决于领域知识。但是,在我们的数据集中,使用12的序列长度很方便,因为我们有月度数据,一年中有12个月。如果我们有每日数据,则更好的序列长度应该是365,即一年中的天数。因此,我们将训练的输入序列长度设置为12。
train_window = 12接下来,我们将定义一个名为的函数create_inout_sequences。该函数将接受原始输入数据,并将返回一个元组列表。在每个元组中,第一个元素将包含与12个月内旅行的乘客数量相对应的12个项目的列表,第二个元组元素将包含一个项目,即在12 + 1个月内的乘客数量。
def create_inout_sequences(input_data, tw):
inout_seq = []
L = len(input_data)
for i in range(L-tw):
train_seq = input_data[i:i+tw]
train_label = input_data[i+tw:i+tw+1]
inout_seq.append((train_seq ,train_label))
return inout_seq执行以下脚本以创建序列和相应的标签进行训练:
train_inout_seq = create_inout_sequences(train_data_normalized, train_window)
如果打印train_inout_seq列表的长度,您将看到它包含120个项目。这是因为尽管训练集包含132个元素,但是序列长度为12,这意味着第一个序列由前12个项目组成,第13个项目是第一个序列的标签。同样,第二个序列从第二个项目开始,到第13个项目结束,而第14个项目是第二个序列的标签,依此类推。
现在让我们打印train_inout_seq列表的前5个项目:
train_inout_seq[:5]输出:
[(tensor([-0.9648, -0.9385, -0.8769, -0.8901, -0.9253, -0.8637, -0.8066, -0.8066,
-0.8593, -0.9341, -1.0000, -0.9385]), tensor([-0.9516])),
(tensor([-0.9385, -0.8769, -0.8901, -0.9253, -0.8637, -0.8066, -0.8066, -0.8593,
-0.9341, -1.0000, -0.9385, -0.9516]),
tensor([-0.9033])),
(tensor([-0.8769, -0.8901, -0.9253, -0.8637, -0.8066, -0.8066, -0.8593, -0.9341,
-1.0000, -0.9385, -0.9516, -0.9033]), tensor([-0.8374])),
(tensor([-0.8901, -0.9253, -0.8637, -0.8066, -0.8066, -0.8593, -0.9341, -1.0000,
-0.9385, -0.9516, -0.9033, -0.8374]), tensor([-0.8637])),
(tensor([-0.9253, -0.8637, -0.8066, -0.8066, -0.8593, -0.9341, -1.0000, -0.9385,
-0.9516, -0.9033, -0.8374, -0.8637]), tensor([-0.9077]))]您可以看到每个项目都是一个元组,其中第一个元素包含序列的12个项目,第二个元组元素包含相应的标签。
创建LSTM模型
我们已经对数据进行了预处理,现在是时候训练我们的模型了。我们将定义一个类LSTM,该类继承自nn.ModulePyTorch库的类;
class LSTM(nn.Module):
def __init__(self, input_size=1, hidden_layer_size=100, output_size=1):
super().__init__()
self.hidden_layer_size = hidden_layer_size
self.lstm = nn.LSTM(input_size, hidden_layer_size)
self.linear = nn.Linear(hidden_layer_size, output_size)
self.hidden_cell = (torch.zeros(1,1,self.hidden_layer_size),
torch.zeros(1,1,self.hidden_layer_size))
def forward(self, input_seq):
lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq) ,1, -1), self.hidden_cell)
predictions = self.linear(lstm_out.view(len(input_seq), -1))
return predictions[-1]让我总结一下以上代码中发生的事情。LSTM该类的构造函数接受三个参数:
input_size:与输入中的要素数量相对应。尽管我们的序列长度为12,但每个月我们只有1个值,即乘客总数,因此输入大小为1。hidden_layer_size:指定隐藏层的数量以及每层中神经元的数量。我们将有一层100个神经元。output_size:输出中的项目数,由于我们要预测未来1个月的乘客人数,因此输出大小为1。
接下来,在构造函数中,我们创建变量hidden_layer_size,lstm,linear,和hidden_cell。LSTM算法接受三个输入:先前的隐藏状态,先前的单元状态和当前输入。该hidden_cell变量包含先前的隐藏状态和单元状态。的lstm和linear层变量用于创建LSTM和线性层。
在forward方法内部,将input_seq作为参数传递,该参数首先传递给lstm图层。该lstm层的输出是当前时间步的隐藏状态和单元状态以及输出。lstm图层的输出将传递到该linear图层。预计的乘客人数存储在predictions列表的最后一项中,并返回到调用函数。
下一步是创建LSTM()类的对象,定义损失函数和优化器。由于我们正在解决分类问题,因此我们将使用交叉熵损失。对于优化器功能,我们将使用adam优化器。
model = LSTM()
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)让我们打印模型:
print(model)输出:
LSTM(
(lstm): LSTM(1, 100)
(linear): Linear(in_features=100, out_features=1, bias=True)
)训练模型
我们将训练模型150个纪元。如果需要,可以尝试更多的时期。丢失将每25个周期打印一次。
epochs = 150
for i in range(epochs):
for seq, labels in train_inout_seq:
optimizer.zero_grad()
model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
y_pred = model(seq)
single_loss = loss_function(y_pred, labels)
single_loss.backward()
optimizer.step()
if i%25 == 1:
print(f'epoch: {i:3} loss: {single_loss.item():10.8f}')
print(f'epoch: {i:3} loss: {single_loss.item():10.10f}')
输出:
epoch: 1 loss: 0.00517058
epoch: 26 loss: 0.00390285
epoch: 51 loss: 0.00473305
epoch: 76 loss: 0.00187001
epoch: 101 loss: 0.00000075
epoch: 126 loss: 0.00608046
epoch: 149 loss: 0.0004329932由于默认情况下权重是在PyTorch神经网络中随机初始化的,因此您可能会获得不同的值。
做出预测
现在我们的模型已经训练完毕,我们可以开始进行预测了。由于我们的测试集包含最近12个月的乘客数据,并且训练了我们的模型以使用12的序列长度进行预测。我们将首先从训练集中过滤出最后12个值:
fut_pred = 12
test_inputs = train_data_normalized[-train_window:].tolist()
print(test_inputs)输出:
[0.12527473270893097, 0.04615384712815285, 0.3274725377559662, 0.2835164964199066, 0.3890109956264496, 0.6175824403762817, 0.9516483545303345, 1.0, 0.5780220031738281, 0.33186814188957214, 0.13406594097614288, 0.32307693362236023]您可以将上述值与train_data_normalized数据列表的最后12个值进行比较。
最初,该test_inputs项目将包含12个项目。在for循环内,这12个项目将用于对测试集中的第一个项目(即项目编号133)进行预测。然后将预测值附加到test_inputs列表中。在第二次迭代期间,最后12个项目将再次用作输入,并将进行新的预测,然后将其test_inputs再次添加到列表中。for由于测试集中有12个元素,因此该循环将执行12次。在循环末尾,test_inputs列表将包含24个项目。最后12个项目将是测试集的预测值。
以下脚本用于进行预测:
model.eval()
for i in range(fut_pred):
seq = torch.FloatTensor(test_inputs[-train_window:])
with torch.no_grad():
model.hidden = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
test_inputs.append(model(seq).item())如果打印test_inputs列表的长度,您将看到它包含24个项目。可以按以下方式打印最后12个预测项目:
test_inputs[fut_pred:]输出:
[0.4574652910232544,
0.9810629487037659,
1.279405951499939,
1.0621851682662964,
1.5830546617507935,
1.8899496793746948,
1.323508620262146,
1.8764172792434692,
2.1249167919158936,
1.7745600938796997,
1.7952896356582642,
1.977765679359436]需要再次提及的是,根据用于训练LSTM的权重,您可能会获得不同的值。
由于我们对训练数据集进行了标准化,因此预测值也进行了标准化。我们需要将归一化的预测值转换为实际的预测值。我们可以通过将标准化值传递到inverse_transform用于标准化数据集的最小/最大缩放器对象的方法来实现。
actual_predictions = scaler.inverse_transform(np.array(test_inputs[train_window:] ).reshape(-1, 1))
print(actual_predictions)输出:
[[435.57335371]
[554.69182083]
[622.56485397]
[573.14712578]
[691.64493555]
[761.46355206]
[632.59821111]
[758.38493103]
[814.91857016]
[735.21242136]
[739.92839211]
[781.44169205]]现在让我们针对实际值绘制预测值。看下面的代码:
x = np.arange(132, 144, 1)
print(x)输出:
[132 133 134 135 136 137 138 139 140 141 142 143]在上面的脚本中,我们创建一个列表,其中包含最近12个月的数值。第一个月的索引值为0,因此最后一个月的索引值为143。
在下面的脚本中,我们将绘制144个月的乘客总数以及最近12个月的预计乘客人数。
plt.title('Month vs Passenger')
plt.ylabel('Total Passengers')
plt.grid(True)
plt.autoscale(axis='x', tight=True)
plt.plot(flight_data['passengers'])
plt.plot(x,actual_predictions)
plt.show()输出:
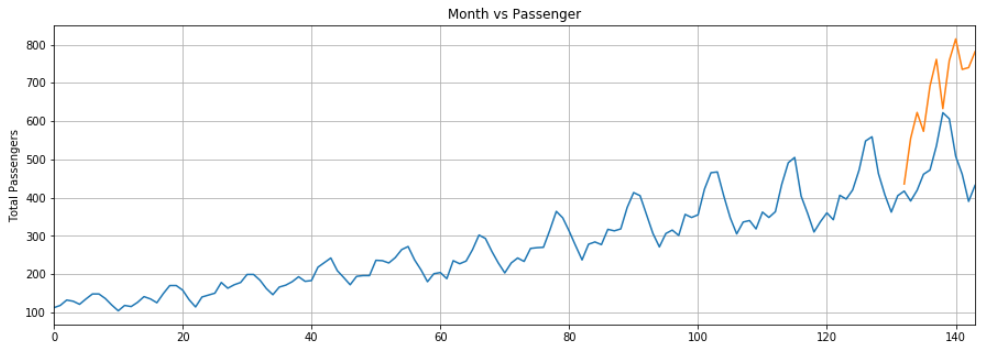
我们的LSTM所做的预测用橙色线表示。您可以看到我们的算法不太准确,但是它仍然能够捕获最近12个月内旅行的乘客总数的上升趋势以及偶尔的波动。您可以在LSTM层中尝试更多的时期和更多的神经元,以查看是否可以获得更好的性能。
为了更好地查看输出,我们可以绘制过去12个月的实际和预测乘客数量,如下所示:
plt.title('Month vs Passenger')
plt.ylabel('Total Passengers')
plt.grid(True)
plt.autoscale(axis='x', tight=True)
plt.plot(flight_data['passengers'][-train_window:])
plt.plot(x,actual_predictions)
plt.show()输出:
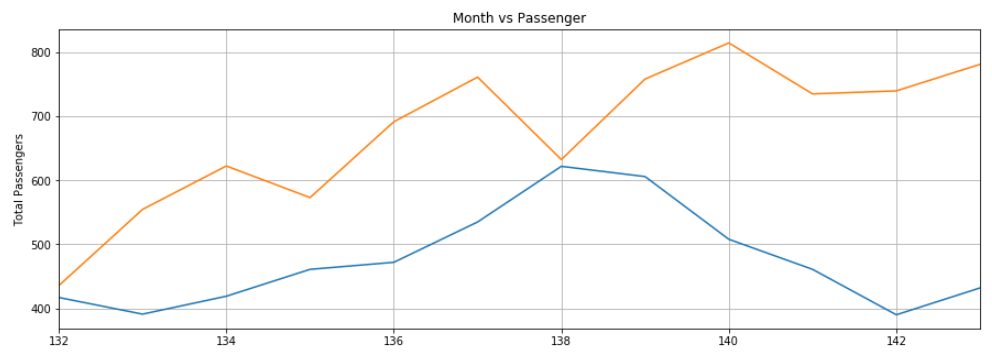
再次,预测不是很准确,但是该算法能够捕获趋势,即未来几个月的乘客数量应高于前几个月,且偶尔会有波动。
结论
LSTM是解决序列问题最广泛使用的算法之一。在本文中,我们看到了如何使用LSTM的时间序列数据进行未来的预测。您还看到了如何使用PyTorch库实现LSTM,然后如何将预测结果与实际值作图,以了解训练后的算法的性能如何。