时间反向传播——RNN
介绍:
循环神经网络是那些处理顺序数据的网络。他们不仅使用当前输入预测输出,而且还考虑了之前发生的输入。换句话说,当前输出取决于当前输出以及存储元件(它考虑了过去的输入)。
为了训练这样的网络,我们使用了很好的旧反向传播,但略有不同。我们不会在特定时间“t”独立训练系统。我们在特定时间“t”以及在时间“t”之前发生的所有事情(如 t-1、t-2、t-3)对其进行训练。
考虑以下 RNN 表示:

RNN架构
S1、S2、S3分别是t1、t2、t3时刻的隐藏状态或记忆单元, Ws是与之相关的权重矩阵。
X1、X2、X3分别是时间t1、t2、t3的输入, Wx是与之相关的权重矩阵。
Y1、Y2、Y 3 分别是时间t1、t2、t3的输出, Wy是与之相关的权重矩阵。
对于任何时间 t,我们有以下两个方程:

其中 g1 和 g2 是激活函数。
现在让我们在时间 t = 3 执行反向传播。
设误差函数为:

,所以在 t = 3 时,

*我们在这里使用平方误差,其中d3是时间t = 3时的期望输出。
为了执行反向传播,我们必须调整与输入、内存单元和输出相关的权重。
调整 Wy
为了更好地理解,让我们考虑以下表示:
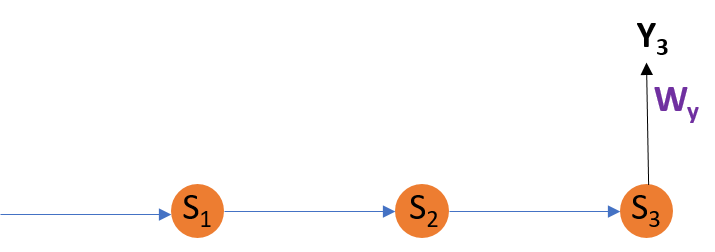
调整 Wy
公式:

解释:
E3是Y3的函数。因此,我们区分E3 和Y3 。
Y3是WY的函数。因此,我们区分Y3 和WY 。
调整 Ws
为了更好地理解,让我们考虑以下表示:
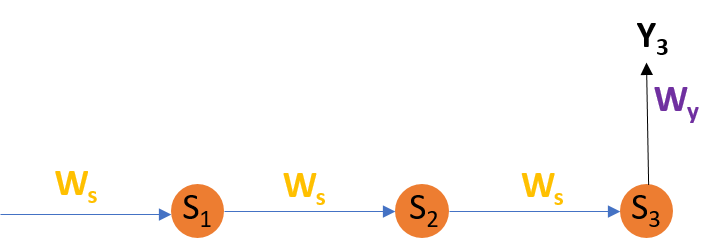
调整 Ws
公式:



解释:
E3是Y3的函数。因此,我们区分E3 和Y3 。
Y3是S3的函数。因此,我们区分Y3 与S3 。
S3是WS的函数。因此,我们将S3 与WS 区分开来。
但我们不能就此止步;我们还必须考虑到以前的时间步骤。因此,我们在考虑权重矩阵WS 的情况下,针对存储单元S2和S1区分(部分)误差函数。
我们必须记住,一个记忆单元,比如说 S t是它之前的记忆单元 S t-1的函数。
因此,我们将S3与S2和S2与S1 相区分。
通常,我们可以将这个公式表示为:

调整 WX:
为了更好地理解,让我们考虑以下表示:

调整 Wx
公式:



解释:
E3是Y3的函数。因此,我们区分E3 和Y3 。
Y3是S3的函数。因此,我们区分Y3 与S3 。
S3是WX的函数。因此,我们将S3 与WX 区分开来。
我们不能就此止步;我们还必须考虑到以前的时间步骤。因此,我们在考虑权重矩阵 WX 的情况下,针对存储单元S2和S1区分(部分)误差函数。
通常,我们可以将这个公式表示为:

限制:
这种通过时间反向传播 (BPTT) 的方法最多可用于有限数量的时间步长,例如 8 或 10。如果我们进一步反向传播,梯度 变得太小。这个问题被称为“消失梯度”问题。问题是信息的贡献随着时间的推移呈几何衰减。因此,如果时间步数大于 10(假设),该信息将被有效地丢弃。
变得太小。这个问题被称为“消失梯度”问题。问题是信息的贡献随着时间的推移呈几何衰减。因此,如果时间步数大于 10(假设),该信息将被有效地丢弃。
超越 RNN:
这个问题的著名解决方案之一是使用所谓的长短期记忆(简称 LSTM)单元而不是传统的 RNN 单元。但是这里可能会出现另一个问题,称为梯度爆炸问题,其中梯度无法控制地增长。
解决方案:可以使用一种称为梯度裁剪的流行方法,其中在每个时间步中,我们可以检查梯度是否 > 阈值。如果是,则对其进行标准化。
> 阈值。如果是,则对其进行标准化。