深度参数连续卷积神经网络
深度参数连续内核卷积是由 Uber Advanced Technologies Group 的研究人员提出的。本文背后的动机是简单的 CNN 架构采用类似网格的架构,并使用离散卷积作为其基本块。这抑制了他们对许多实际应用程序执行精确卷积的能力。因此,他们提出了一种称为参数连续卷积的卷积方法。
参数连续卷积:
参数连续卷积是一种可学习的运算符,可在非网格上运行 结构化数据和探索 跨越完整连续向量空间的参数化内核。只要支持结构是可计算的,它就可以处理任意数据结构。连续卷积运算符近似为通过蒙特卡罗抽样的离散:
下一个挑战是定义 g,它以支持域中的每个点都被分配一个值的方式进行参数化。这是不可能的,因为它需要在连续域的无限点上定义 g。

网格与连续转换
相反,作者使用多层感知器作为近似参数连续卷积函数,因为它们具有表现力并且能够近似连续函数。

内核 g(z,∅ ): R D → R跨越完整的连续支持域,同时通过有限数量的计算保持参数化
参数连续卷积层:
Parametric 连续卷积层有 3 个部分:
- 输入特征向量

- 支持域中的关联位置

- 输出域位置

对于每一层,我们首先评估核函数:
 ;给定参数
;给定参数 .输出向量的每个元素可以计算为:
.输出向量的每个元素可以计算为:
其中,N 是输入点的数量,M 是输出点的数量,D 是支持域的维度,F 和 O 分别是预定义的输入和输出特征维度。在这里,我们可以观察到与离散卷积的以下区别:
- 核函数是在支持域中给定相对位置的连续函数。
- (输入,输出)点也可以是连续域中的任何点,并且可以不同。
建筑学:
网络将输入特征及其在支持域中的相关位置作为输入。遵循标准的 CNN 架构,我们可以添加批量归一化、非线性和层之间的残差连接,这对于帮助收敛至关重要。可以在支持域上使用池化来聚合信息。
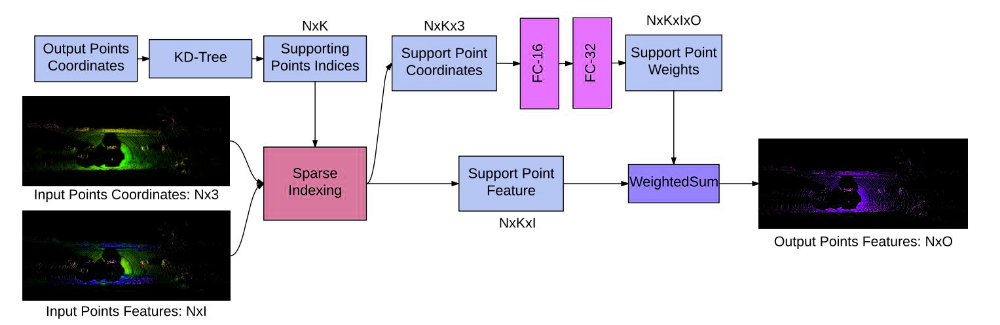
Deep Para CKConv 架构
局部强制卷积
在有限的内核大小 M 上计算标准卷积以在离散场景中强制执行局部性。然而,连续函数可以通过计算发现点更接近x的函数执行局部性。

其中,w() 是一个用于强制执行局部性的调制窗口函数。它在其算法中使用 k-最近邻。
训练
由于模型的所有构建块在其域内都可以微分,因此我们可以将反向传播函数写为:
参考:
- 深度参数连续CNN