- 深度神经网络
- 深度神经网络(1)
- 具有 L 层的深度神经网络(1)
- 具有 L 层的深度神经网络
- 深度神经网络的测试
- 深度神经网络的体系结构
- TensorFlow中神经网络的实现(1)
- TensorFlow中神经网络的实现
- 使用 TensorFlow 实现神经网络(1)
- 使用 TensorFlow 实现神经网络
- Python深度学习-实现(1)
- Python深度学习-实现
- 神经网络和深度学习系统之间的区别(1)
- 神经网络和深度学习系统之间的区别
- 深度神经网络的权重初始化技术
- 深度神经网络的权重初始化技术(1)
- 深度可分离卷积神经网络
- 深度可分离卷积神经网络(1)
- 深度参数连续卷积神经网络(1)
- 深度参数连续卷积神经网络
- PyTorch-实现第一个神经网络
- PyTorch-实现第一个神经网络(1)
- 深度神经网络中的非线性边界
- 深度神经网络中的非线性边界(1)
- 深度神经网络中的前馈过程
- 深度神经网络中的前馈过程(1)
- 神经网络在图像识别中的实现
- 深度学习中的变压器神经网络——概述(1)
- 深度学习中的变压器神经网络——概述
📅 最后修改于: 2020-11-11 00:54:12 🧑 作者: Mango
深度神经网络的实现
在了解了反向传播的过程之后,让我们开始看看如何使用PyTorch实现深度神经网络。实施深度神经网络的过程类似于感知器模型的实施。在实施过程中,我们必须执行以下步骤。
步骤1:
第一步,我们将导入所有必需的库,例如火炬,numpy,数据集和matplotlib.pyplot。
import torch
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
第2步:
在第二步中,我们没有定义数据点,然后使用make_blobs()函数创建一个数据集,该函数将创建数据点的集群。
no_of_points=500
datasets.make_blobs()
第三步:
现在,我们将创建数据集,并将数据点存储到变量x中,而将值存储到变量y中,我们将使用一下标签。
x,y=datasets.make_blobs()
第四步:
现在,我们将make_blobs()更改为make_cicrcle(),因为我们希望数据集采用循环形式。我们在make_circle()函数传递适当的参数。第一个参数代表样本点的数量,第二个参数是随机状态,第三个参数是噪声,它是指高斯噪声的标准偏差,第四个参数是因子,它是指样本的相对大小。与较大的内部圆形区域相比较小。
x,y=datasets.make_circles(n_samples=no_of_points,random_state=123,noise=0.1,factor=0.2)=
第四步:
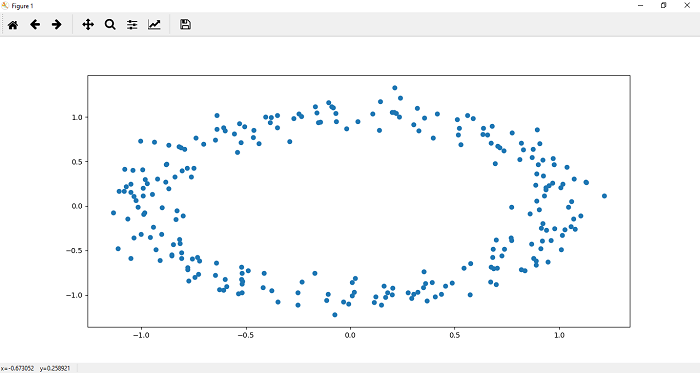
现在,根据需要自定义数据集后,我们可以使用plt.scatter()函数将其绘制并可视化。我们定义每个标签数据集的x和y坐标。让我们从标签为0的数据集开始。它绘制了数据的顶部区域。 0个标记数据集的散布函数定义为
plt.scatter(x[y==0,0],x[y==0,1])
步骤5:
现在,我们在数据的下部区域中绘制点。一个标记数据集的散点函数()定义为
plt.scatter(x[y==1,0],x[y==1,1])
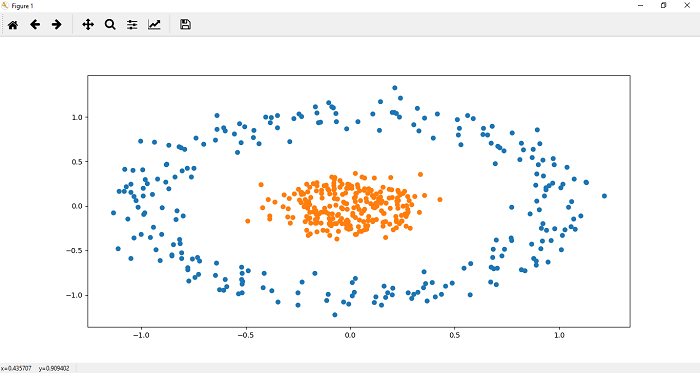
单行无法对以上数据集进行分类。为了对该数据集进行分类,将需要更深入的神经网络。
我们把plt.scatter(x [y == 0,0],x [y == 0,1])和plt.scatter(x [y == 1,0],x [y == 1,1] )成为进一步使用的函数
def Scatter():
plt.scatter(x[y==0,0],x[y==0,1])
plt.scatter(x[y==1,0],x[y==1,1])
步骤6:
在这一步中,我们将创建我们在线性回归和感知器模型中实现的模型类。不同之处在于,这里我们在输入和输出层之间也使用隐藏层。在init()方法中,我们将传递一个加法参数h1作为隐藏层,我们的输入层与隐藏层连接,然后隐藏层与输出层连接。所以
class Deep_neural_network(nn.Module):
def __init__(self,input_size, h1, output_size):
super().__init__()
self.linear=nn.Linear(input_size, h1) # input layer connect with hidden layer
self.linear1=nn.Linear(h1, output_size) # hidden layer connect with output layer
现在,我们必须在正向函数添加此额外的隐藏层,以便任何输入都必须通过神经网络的整个深度才能进行预测。所以
def forward(self,x):
x=torch.sigmoid(self.linear(x)) # Return the prediction x
x=torch.sigmoid(self.linear1(x)) # Prediction will go through the next layer.
return x # Returning final outputs
我们的初始化已经完成,现在,我们可以使用它了。请记住训练模型x,并且y坐标都应为numpy数组。所以我们要做的是将x和y值更改为张量
xdata=torch.Tensor(x)
ydata=torch.Tensor(y)
步骤7
我们将使用Deep_neural_network()构造函数初始化一个新的线性模型,并将input_size,output_size和hidden_size作为参数传递。现在,我们print分配给它的随机权重和偏差值,如下所示:
print(list(model.parameters()))
在此之前,为了确保随机结果的一致性,我们可以使用手电筒手动种子为随机数生成器播种,并可以按如下方式放置两个种子
torch.manual_seed(2)
步骤8:
交叉熵是我们用来计算模型误差的标准。我们的损失函数将基于二进制交叉熵损失(BCELoss)进行度量,因为我们仅处理两个类别。它是从nn模块导入的。
criterion=nn.BCELoss()
现在,我们的下一步是使用优化器更新参数。因此,我们定义了使用梯度下降算法的优化程序。在这里,我们将使用Adam优化器。亚当优化器是众多优化算法之一。 Adam优化算法是随机梯度下降的两个其他扩展的组合,例如Adagrad和RMSprop。学习率在优化中起着重要作用。
optimizer=torch.optim.Adam(model.parameters(),lr=0.01)
如果我们选择最低的学习率,则会导致朝向最低值的收敛速度非常慢,而如果您选择非常大的学习率,则会阻碍收敛。 Adam优化器算法最终为每个参数计算自适应学习率。
步骤9:
现在,我们将像在线性模型和感知器模型中所做的那样,针对指定的纪元训练模型。因此,代码将类似于感知器模型,因为
epochs=1000
losses=[]
For i in range (epochs):
ypred=model.forward(x) #Prediction of y
loss=criterion(ypred,y) #Find loss
losses.append() # Add loss in list
optimizer.zero_grad() # Set the gradient to zero
loss.backward() #To compute derivatives
optimizer.step() # Update the parameters
