Pandas 中的集群采样
抽样是一种我们从大量人口中收集或选择一小组数据的方法,而无需找出集合中每个个体的含义。我们正在对总体数据进行抽样,因为我们无法从整个总体中收集数据。如果我们完成了抽样,那么我们将总体纳入可管理的形式,并帮助最大程度地减少由于总体数量众多而导致的错误。
我们可以用几种方法进行抽样,这里只讨论集群抽样:
整群抽样:
整群抽样是一种概率抽样,其中总体中的每个元素都是平等选择的,我们使用总体的子集作为抽样部分而不是单个元素进行抽样。
人口被划分为被认为是集群的子集或子组,并且从集群的数量中,我们选择单个集群以进行下一步。
现在查看对总体执行集群抽样所采取的步骤:
步骤 1:定义和确定目标人群。
这是我们必须执行抽样的第一步,我们必须从总体中清楚地选择目标区域。
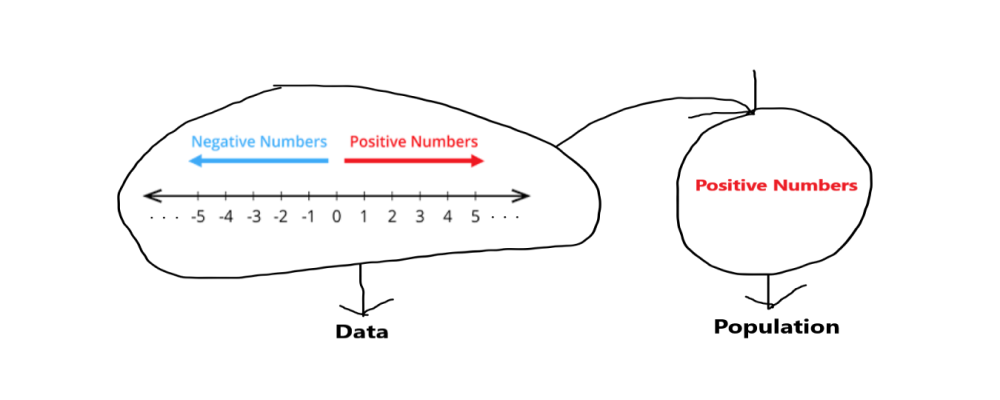
为了用简单的语言理解,让我们举一个整数的例子,整数是可以像所有负数和正数( -1,-4,-8,3,5,2,0……etc )一样没有小数形式的数字所以我们把所有的整数作为我们的数据,我们必须从这些数据中选择我们的目标区域来执行采样。从这些整数数据中,我们可以针对所有正数或所有负数。
这里我们假设我们的目标区域都是正数,这意味着我们从整数数据中取所有正数作为我们的样本。
步骤2:抽样方法。
这里我们使用概率聚类抽样,因为总体中的每个元素都有相同的选择机会。
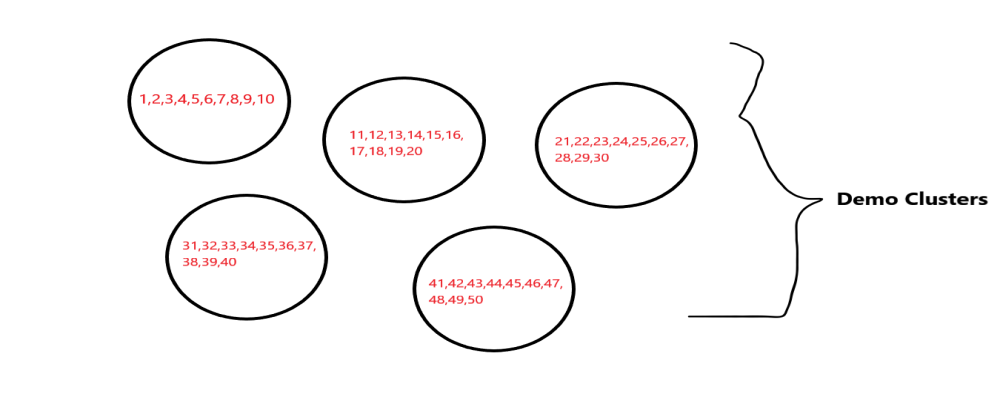
第 3 步:将样本分成簇。
在我们选择采样方法后,我们将样本划分为集群,这是执行集群采样的一个重要部分,我们必须创建一个质量集群,因为它们在采样后会产生更好的准确性。我们提醒,我们正在生产的集群具有更好的影响,这意味着它们对我们的人口有很好的代表。集群必须均匀且相似地分布,因为它们之间没有重复。理想情况下,每个集群应该是整个人口的微型代表。
第 4 步:收集数据。
在执行上述步骤后的最后一步,我们从样本中收集我们想要的数据。
我们举一个集群抽样的例子,其中我们取 1 到 n 个自然数来组成集群,然后从该集群中选择随机的单个集群进行采样。
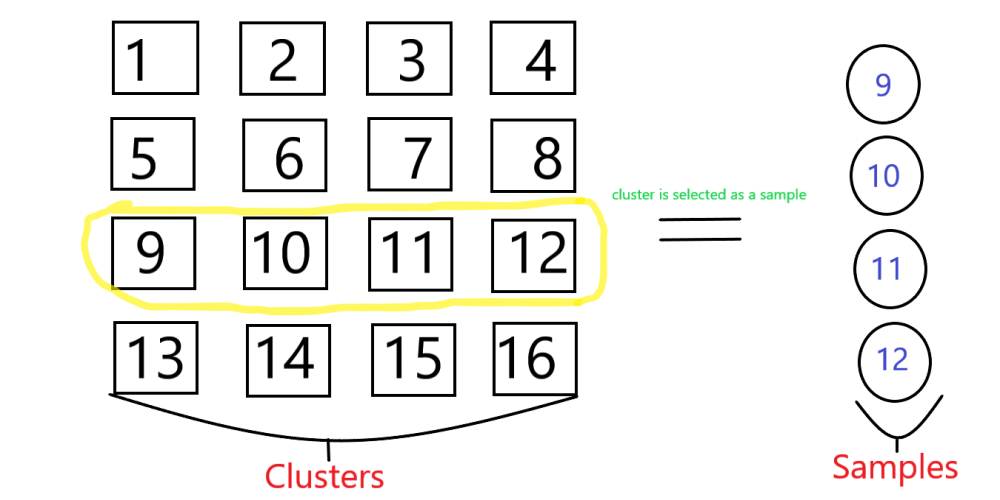
N = 16,因此我们从 1 到 16 中抽取样本,然后从集群中随机选择一个集群作为样本,然后有一个由 4 个数字组成的单独集群。
示例 1:
Python3
# import pandas
import pandas as pd
# import numpy
import numpy as np
# creating dictionary of data
data = {'N_numbers':np.arange(1,16)}
# creating dataframe
df = pd.DataFrame(data)
# sample of data
samples = df.sample(4)
print(samples)Python3
# code
# importing modules
import pandas as pd
import numpy as np
#creating dictionary of data
dic_data = {'employee_id':np.arange(1,21),
'value':np.random.randn(20)}
# creating DataFrame from dictonary
df = pd.DataFrame(dic_data)
print(df)Python3
# code
# import pandas
import pandas as pd
# import numpy
import numpy as np
# creating samples
samples = df.sample(4).sort_values(by='employee_id')
# show samples
print(samples)输出:

4 个数字的随机样本形成 1-16 个数字的集群。
在此输出中,我们从具有随机数的 N-numbers 列中看到,顺便说一下,这是包含 4 个样本的随机集群。在 Sample()的帮助下,设置单个集群呈现的样本数。
示例 2:
蟒蛇3
# code
# importing modules
import pandas as pd
import numpy as np
#creating dictionary of data
dic_data = {'employee_id':np.arange(1,21),
'value':np.random.randn(20)}
# creating DataFrame from dictonary
df = pd.DataFrame(dic_data)
print(df)
输出:

在这里,我们创建了 DataFrame df,其中包含 20 个员工 ID,每个 ID 都有随机值。从数据集df , 我们采用包含特定 4 个随机样本的随机集群。
代码:
蟒蛇3
# code
# import pandas
import pandas as pd
# import numpy
import numpy as np
# creating samples
samples = df.sample(4).sort_values(by='employee_id')
# show samples
print(samples)
输出:

这些是随机选择的员工
正如您在我们的输出中看到的,我们收集了 4 个随机员工的数据,其中包含他们的 employee_id 和值。首先,我们创建一个样本变量,然后为其分配一个由 4 名随机员工组成的样本,作为我们的数据。