重采样方法介绍
在阅读机器学习和数据科学时,我们经常遇到一个术语,称为不平衡类分布,通常发生在其中一个类中的观察值远高于或低于任何其他类时。
由于机器学习算法倾向于通过减少错误来提高准确性,因此它们不考虑类分布。这个问题在欺诈检测、异常检测、面部识别等示例中很普遍。
两种常见的重采样方法是 -
- 交叉验证
- 引导
交叉验证——
交叉验证用于估计与模型相关的测试误差以评估其性能。
验证集方法:
这是最基本的方法。它只是将数据集随机分为两部分:首先是训练集,其次是验证集或保留集。该模型拟合训练集,拟合模型用于对验证集进行预测。 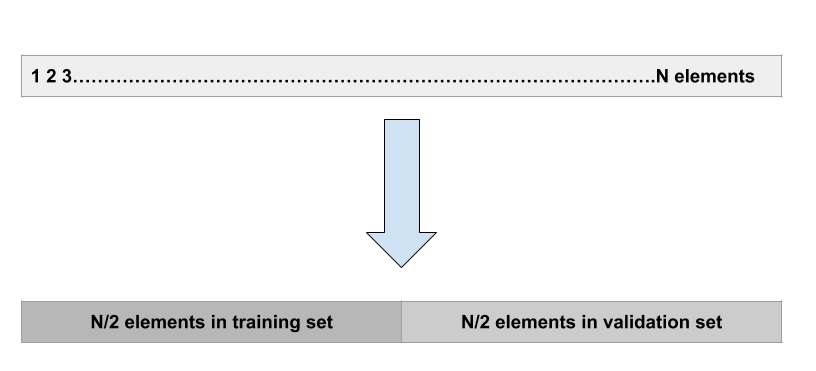
留一法交叉验证:
LOOCV 是比验证集方法更好的选择。不是将整个数据集分成两半,只使用一个观察值进行验证,其余的用于拟合模型。 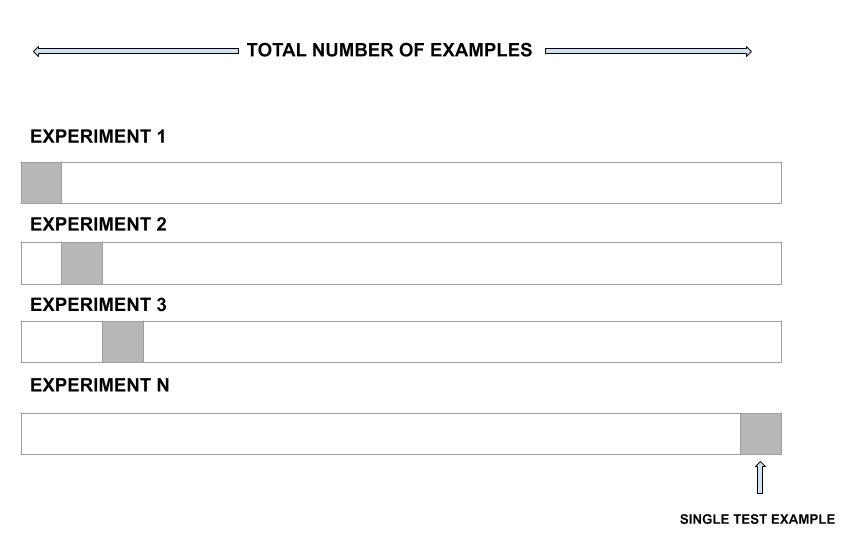
k折交叉验证——
这种方法涉及将观察集随机分成大小几乎相等的 k 折。第一个折叠被视为验证集,模型适合剩余的折叠。然后将该过程重复 k 次,其中每次将不同的组视为验证集。 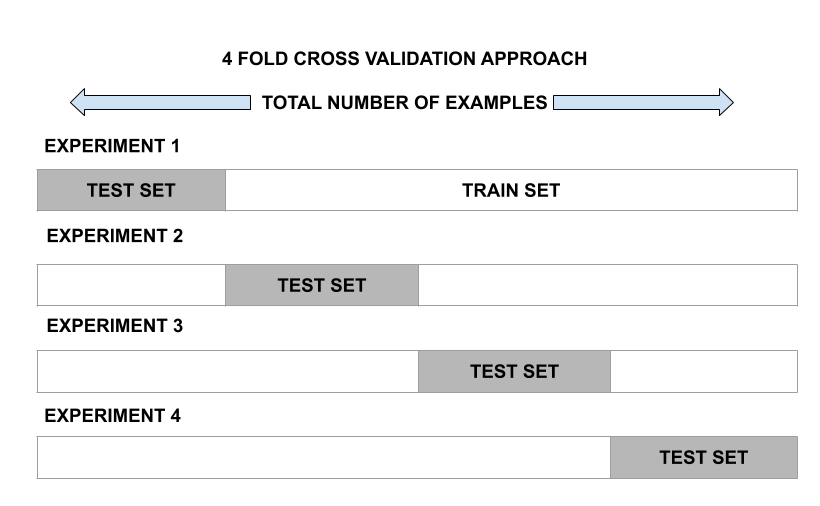
引导——
Bootstrap 是一种强大的统计工具,用于量化给定模型的不确定性。然而,bootstrap 的真正力量在于它可以应用于各种模型,在这些模型中,难以获得或不能自动输出可变性。
挑战:
当处理不平衡的数据集时,机器学习中的算法往往会产生不令人满意的分类器。
例如,电影评论数据集
Total Observations : 100
Positive Dataset : 90
Negative Dataset : 10
Event rate : 2%这里的主要问题是如何获得平衡的数据集。
标准机器学习算法的挑战:
决策树和逻辑回归等标准 ML 技术偏向于多数类,并且倾向于忽略少数类。他们倾向于只预测多数类,因此,与多数类相比,少数类存在重大错误分类。
分类算法的评价是通过混淆矩阵来衡量的。 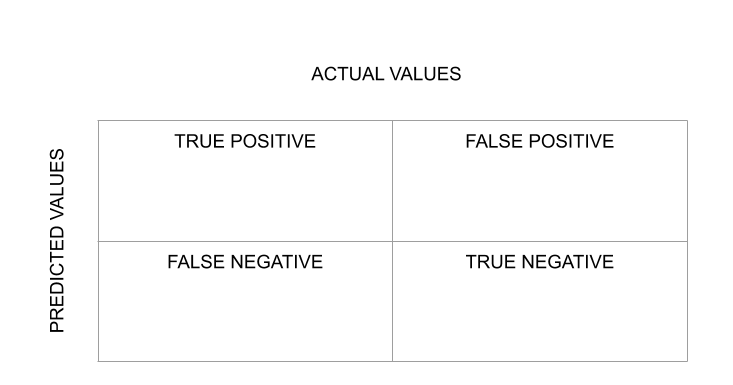
评估结果的一种方法是通过混淆矩阵,它显示每个类的正确和错误预测。在第一行中,第一列表示有多少类“真”被正确预测,第二列表示有多少类“真”被预测为“假”。在第二行,我们注意到所有“False”类条目都被预测为“True”类。
因此,混淆矩阵的对角线值越高,正确预测就越好。
处理方法:
- 随机过采样:
它旨在通过复制它们随机增加少数类示例来平衡类分布。例如 -
Total Observations : 100 Positive Dataset : 90 Negative Dataset : 10 Event Rate : 2%我们复制负数据集 15 次
Positive Datset: 90 Negative Datset after Replicating: 150 Total Observations: 190 Event Rate : 150/240= 63%SMOTE(Synthetic Minority Oversampling Technique)在现有少数实例之间合成新的少数实例。它随机选取少数类并计算该特定点的 K 最近邻。最后,将合成点添加到相邻点和所选点之间。
- 随机欠采样:
它旨在通过随机消除多数类示例来平衡类分布。例如 -
Total Observations : 100 Positive Dataset : 90 Negative Dataset : 10 Event rate : 2% We take 10% samples of Positive Dataset and combine it with Negative Dataset. Positive Dataset after Random Under-Sampling : 10% of 90 = 9 Total observation after combining it with Negative Dataset: 10+9=19 Event Rate after Under-Sampling : 10/19 = 53%当两个不同类的实例彼此非常接近时,我们删除多数类的实例以增加两个类之间的空间。这有助于分类过程。
- 基于集群的过采样:
K 表示聚类算法独立应用于两个类实例,例如识别数据集中的聚类。所有集群都被过采样,使得同一类的集群具有相同的大小。例如 -
Total Observations : 100 Positive Dataset : 90 Negative Dataset : 10 Event Rate : 2%多数类集群:
集群 1:20 次观察
集群 2:30 次观察
集群 3:12 次观察
集群 4:18 次观察
第 5 组:10 次观察少数族群:
集群 1:8 次观察
集群 2:12 次观察过采样后,同一类的所有集群都有相同数量的观察。
多数类集群:
集群 1:20 次观察
集群 2:20 次观察
第 3 组:20 次观察
集群 4:20 次观察
第 5 组:20 次观察少数族群:
集群 1:15 次观察
集群 2:15 次观察下面是一些重采样技术的实现:
您可以从下面给定的链接下载数据集:数据集下载
# importing libraries import pandas as pd import numpy as np import seaborn as sns from sklearn.preprocessing import StandardScaler from imblearn.under_sampling import RandomUnderSampler, TomekLinks from imblearn.over_sampling import RandomOverSampler, SMOTEdataset = pd.read_csv(r'C:\Users\Abhishek\Desktop\creditcard.csv') print("The Number of Samples in the dataset: ", len(dataset)) print('Class 0 :', round(dataset['Class'].value_counts()[0] /len(dataset) * 100, 2), '% of the dataset') print('Class 1(Fraud) :', round(dataset['Class'].value_counts()[1] /len(dataset) * 100, 2), '% of the dataset')
X_data = dataset.iloc[:, :-1] Y_data = dataset.iloc[:, -1:] rus = RandomUnderSampler(random_state = 42) X_res, y_res = rus.fit_resample(X_data, Y_data) X_res = pd.DataFrame(X_res) Y_res = pd.DataFrame(y_res) print("After Under Sampling Of Major Class Total Samples are :", len(Y_res)) print('Class 0 :', round(Y_res[0].value_counts()[0] /len(Y_res) * 100, 2), '% of the dataset') print('Class 1(Fraud) :', round(Y_res[0].value_counts()[1] /len(Y_res) * 100, 2), '% of the dataset')
tl = TomekLinks() X_res, y_res = tl.fit_resample(X_data, Y_data) X_res = pd.DataFrame(X_res) Y_res = pd.DataFrame(y_res) print("After TomekLinks Under Sampling Of Major Class Total Samples are :", len(Y_res)) print('Class 0 :', round(Y_res[0].value_counts()[0] /len(Y_res) * 100, 2), '% of the dataset') print('Class 1(Fraud) :', round(Y_res[0].value_counts()[1] /len(Y_res) * 100, 2), '% of the dataset')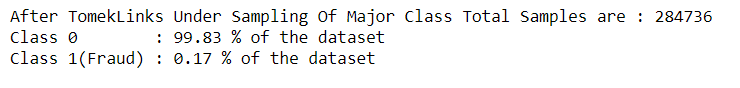
ros = RandomOverSampler(random_state = 42) X_res, y_res = ros.fit_resample(X_data, Y_data) X_res = pd.DataFrame(X_res) Y_res = pd.DataFrame(y_res) print("After Over Sampling Of Minor Class Total Samples are :", len(Y_res)) print('Class 0 :', round(Y_res[0].value_counts()[0] /len(Y_res) * 100, 2), '% of the dataset') print('Class 1(Fraud) :', round(Y_res[0].value_counts()[1] /len(Y_res) * 100, 2), '% of the dataset')
sm = SMOTE(random_state = 42) X_res, y_res = sm.fit_resample(X_data, Y_data) X_res = pd.DataFrame(X_res) Y_res = pd.DataFrame(y_res) print("After SMOTE Over Sampling Of Minor Class Total Samples are :", len(Y_res)) print('Class 0 :', round(Y_res[0].value_counts()[0] /len(Y_res) * 100, 2), '% of the dataset') print('Class 1(Fraud) :', round(Y_res[0].value_counts()[1] /len(Y_res) * 100, 2), '% of the dataset')