毫升 |偏差与方差
在本文中,我们将学习“机器学习模型的偏差和方差是什么,它们的最佳状态应该是什么”。
有多种方法可以评估机器学习模型。我们可以使用 MSE(均方误差)进行回归;分类问题的精度、召回率和 ROC(特征接收器)以及绝对误差。以类似的方式,Bias 和 Variance 帮助我们调整参数并在多个构建的模型中确定更合适的模型。
偏差是由于对数据的错误假设而发生的一种错误,例如假设数据是线性的,而实际上,数据遵循复杂的函数。另一方面,引入方差时对训练数据的变化高度敏感。这也是一种错误,因为我们想让我们的模型对噪声具有鲁棒性。
在进行数学定义之前,我们需要了解随机变量和函数。假设 f(x) 是我们给定数据遵循的函数。我们将构建几个模型,可以表示为 .该函数上的每个点都是一个随机变量,其值的数量等于模型的数量。为了正确逼近真实函数f(x),我们取期望值
.该函数上的每个点都是一个随机变量,其值的数量等于模型的数量。为了正确逼近真实函数f(x),我们取期望值
![f\hat(x) : E[f\hat(x)]](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/ML_%7C_Bias_Vs_Variance_1.jpg "由 QuickLaTeX.com 渲染")
偏见 : ![f-E[f\hat]](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/ML_%7C_Bias_Vs_Variance_2.jpg "由 QuickLaTeX.com 渲染") 差异:
差异: ![E[f^2\hat] - E[f\hat]] = E[(f\hat - E[f\hat])^2]](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/ML_%7C_Bias_Vs_Variance_3.jpg "由 QuickLaTeX.com 渲染")
让我们看看这两个术语的重要性。 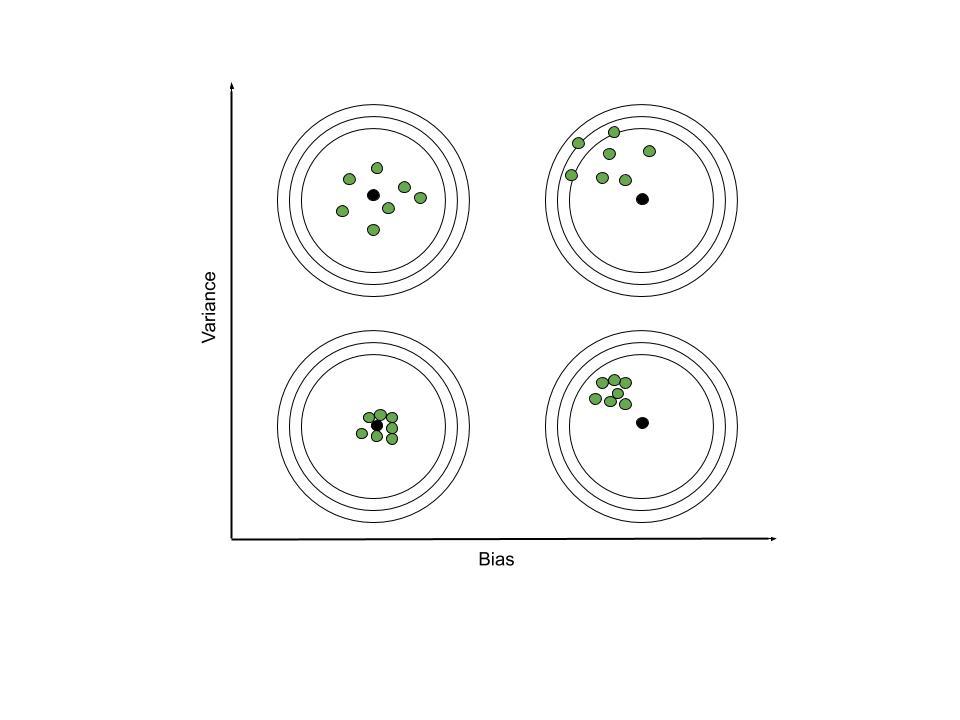
这些图像是不言自明的。不过,我们将讨论需要注意的事项。当偏差较大时,预测函数组的焦点远离真实函数。然而,当方差很大时,预测函数组中的函数彼此之间会有很大差异。
让我们在机器学习的背景下举一个例子。这里获取的数据遵循特征(x)的二次函数来预测目标列(y_noisy)。在现实生活中,数据包含嘈杂的信息而不是正确的值。因此,我们在二次函数值中添加了 0 均值、1 方差高斯噪声。

| x | y | y_noisy |
|---|---|---|
| -5 | 25 | 2.67595670e+01 |
| -4.5 | 20.25 | 2.11632561e+01 |
| -4 | 16 | 1.46802434e+01 |
| -3.5 | 12.25 | 1.31647290e+01 |
| -3 | 9 | 1.05460668e+01 |
| -2.5 | 6.25 | 5.95794282e+00 |
| -2 | 4 | 3.25487498e+00 |
| -1.5 | 2.25 | 1.97478968e+00 |
| -1 | 1 | 1.73960283e+00 |
| -0.5 | 0.25 | -1.13112086e-02 |
| 0 | 0 | 1.64552536e+00 |
| 0.5 | 0.25 | -9.60938656e-01 |
| 1 | 1 | 4.46816845e-01 |
| 1.5 | 2.25 | 4.01016081e+00 |
| 2 | 4 | 1.54342469e+00 |
| 2.5 | 6.25 | 7.27654456e+00 |
| 3 | 9 | 9.37684917e+00 |
| 3.5 | 12.25 | 1.32076198e+01 |
| 4 | 16 | 1.79133242e+01 |
| 4.5 | 20.25 | 2.08601281e+01 |
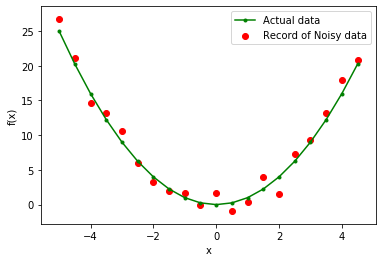
数据可视化
现在我们有一个回归问题,让我们尝试拟合几个不同阶的多项式模型。此处显示的结果等级为:1、2、10。
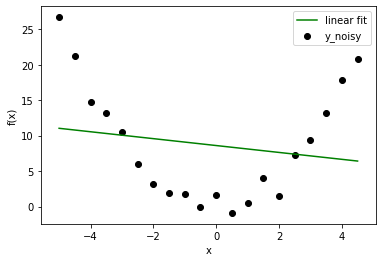
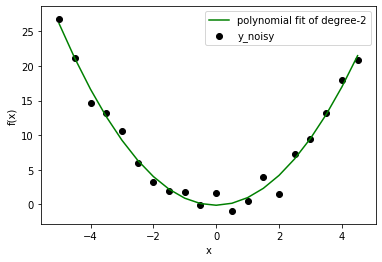
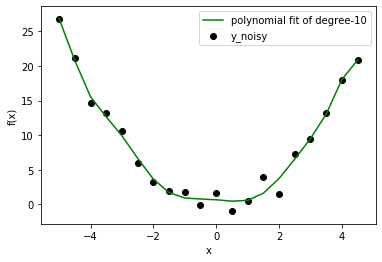
在这种情况下,我们已经知道正确的模型是 degree=2。但是一旦你从一个玩具问题中拓宽了视野,你就会面临事先不知道数据分布的情况。因此,如果选择度数较低的模型,可能无法正确拟合数据行为(让数据远离线性拟合)。如果你选择更高的度数,也许你拟合的是噪声而不是数据。低阶模型无论如何都会给你高错误,但高阶模型仍然不正确,错误低。那么,我们应该怎么做呢?我们可以使用可视化方法,也可以使用 Bias 和 Variance 寻找更好的设置。 (数据科学家只使用一部分数据来训练模型,然后使用剩余的数据来检查泛化行为。)
现在,如果我们绘制模型集合来计算每个多项式模型的偏差和方差:

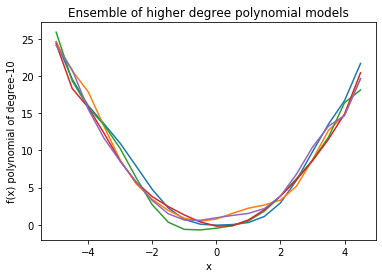 正如我们所看到的,在线性模型中,每条线都非常接近,但与实际数据相距甚远。另一方面,高次多项式曲线仔细地遵循数据,但它们之间的差异很大。因此,偏差在线性中很高,而在更高次多项式中方差很高。这一事实也反映在计算的数量上。
正如我们所看到的,在线性模型中,每条线都非常接近,但与实际数据相距甚远。另一方面,高次多项式曲线仔细地遵循数据,但它们之间的差异很大。因此,偏差在线性中很高,而在更高次多项式中方差很高。这一事实也反映在计算的数量上。
Linear Model:-
Bias : 6.3981120643436356
Variance : 0.09606406047494431
Higher Degree Polynomial Model:-
Bias : 0.31310660249287225
Variance : 0.565414017195101
在这个任务之后,我们可以得出结论,简单模型往往具有高偏差,而复杂模型具有高方差。我们可以根据这些特征确定欠拟合或过拟合。
再次来到数学部分:偏差和方差如何与目标值和预测值之间的经验误差(MSE,由于数据中添加的噪声而不是真实误差)相关。
![\begin{align*} MSE =& E[(f-f\hat)^2]\\ =& E[f^2 - 2ff\hat + f\hat^2]\\ =& f^2E[1] - 2fE[f\hat] + E[f\hat^2]\\ =& f^2 - 2fE[f\hat] + E[f\hat^2]\\ \end{align*}](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/ML_%7C_Bias_Vs_Variance_12.jpg "由 QuickLaTeX.com 渲染")
现在,让我们计算另一个数量:
![\begin{align*} bias^2 + variance =& (f-E[f\hat])^2 + E[f\hat^2] - {(E[f\hat])}^2\\ =& f^2 - 2fE[f\hat] + (E[f\hat])^2 + E[f\hat^2] - (E[f\hat])^2\\ =& f^2 - 2fE[f\hat] +E[f\hat^]\\ =& MSE \end{align*}](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/ML_%7C_Bias_Vs_Variance_13.jpg "由 QuickLaTeX.com 渲染")
现在,我们进入了结论阶段。要记住的重要一点是偏差和方差有权衡,为了最大限度地减少误差,我们需要减少两者。这意味着我们希望我们的模型预测接近数据(低偏差)并确保预测点不会因噪声变化而变化太大(低方差)。