快速 R-CNN |机器学习
在讨论 Fast R-CNN 之前,我们先来看看 R-CNN 面临的挑战
- R-CNN 的训练非常慢,因为模型的每个部分(CNN、SVM 分类器、边界框)都需要单独训练,不能并行。
- 此外,在 R-CNN 中,我们需要通过深度卷积架构前向传递每个区域提议(每张图像最多2000个区域提议)。这就解释了训练这个模型所花费的时间
- 推理的测试时间也很高。在 R-CNN 中测试图像需要49秒(以及选择性搜索区域建议生成)。
Fast R-CNN 致力于解决这些问题。再来看看 Fast R-CNN 的架构
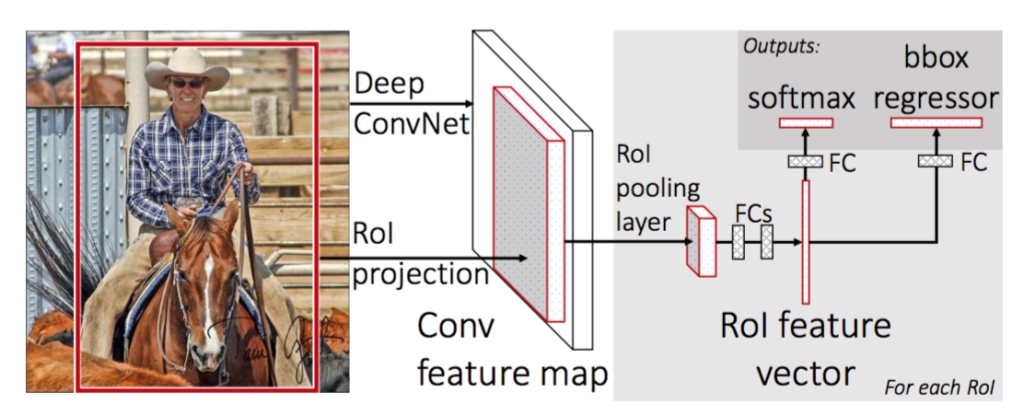
快速 R-CNN 架构
首先,我们从选择性搜索算法生成区域提议。这种选择性搜索算法最多可生成大约2000 个区域建议。这些区域提议(RoI 投影)与传递到 CNN 网络的输入图像相结合。该 CNN 网络生成卷积特征图作为输出。然后对于每个目标提议,感兴趣区域 (RoI) 池化层为每个特征图提取固定长度的特征向量。然后将每个特征向量传递到softmax分类器和Bbox回归的双层中,用于区域提议的分类并改善该对象的边界框的位置。
Fast R-CNN的CNN网络
Fast R-CNN 使用三个预训练的 ImageNet 网络进行实验,每个网络具有5 个最大池化层和5-13个卷积层(例如 VGG-16)。在这些预训练网络中提出了一些更改,这些更改是:
- 网络经过修改,使其两个输入图像和在该图像上生成的区域建议列表。
- 其次,全连接层之前的最后一个池化层(此处为(7*7*512) )需要被感兴趣区域(RoI)池化层替换。
- 第三,最后一个全连接层和 softmax 层被替换为 softmax 分类器和具有全连接层的K+1特定类别边界框回归器的双层。

VGG-16 架构
该 CNN 架构获取图像(VGG-16 的大小 = 224 x 224 x 3 )及其区域提议并输出卷积特征图(VGG-16 的大小 = 14 x 14 x 512 )。感兴趣区域 (RoI) 池化:

RoI pooling 是 Fast R-CNN 论文中引入的新事物。其目的是从非均匀输入 (RoI) 生成均匀、固定大小的特征图。
它需要两个值作为输入:
- 从前一个 CNN 层获得的特征图(VGG-16 中为14 x 14 x 512 )。
- 一个表示感兴趣区域的 N x 4 矩阵,其中 N 是 RoI 的数量,前两个表示 RoI 左上角的坐标,另外两个表示 RoI 的高度和宽度,表示为(r, c, h, w) .
假设我们有8*8的特征图,我们需要提取大小为2*2的输出。我们将按照以下步骤进行。
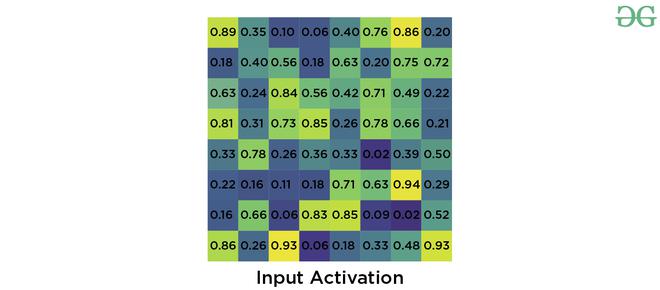
- 假设我们给定 RoI 的左角坐标为(0, 3) ,高度、宽度为(5, 7) 。
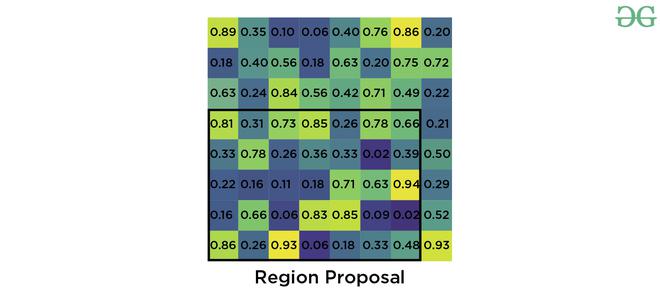
- 现在,如果我们需要将此区域提议转换为2 x 2输出块,并且我们知道池化部分的尺寸不能完全被输出尺寸整除。我们采用池化方法,将其固定为2 x 2维度。
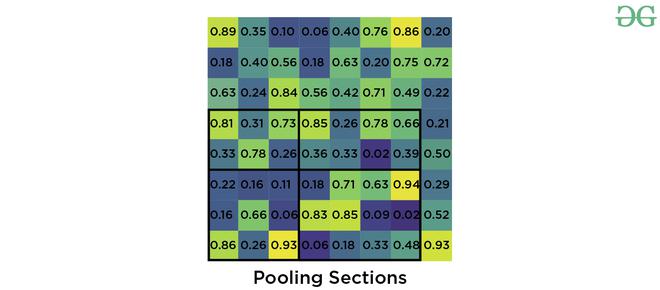
- 现在我们应用最大池化运算符从我们划分的每个区域中选择最大值。
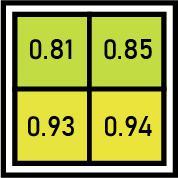
最大池输出
训练和损失:首先,我们采用标注有地面真实类 u 和地面真实边界框 v 的每个感兴趣的训练区域。然后我们获取由 softmax 分类器和边界框回归器生成的输出,并对它们应用损失函数。我们定义了我们的损失函数,使其同时考虑分类和边界框定位。这种损失函数称为多任务损失。这定义如下:
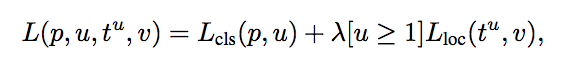
其中L cls 是分类损失, L loc是定位损失。 lambda 是平衡参数,u 是一个函数(对于背景,u=0,否则 u=1)以确保仅在需要定义边界框时才计算损失。这里, L cls是对数损失, L loc定义为
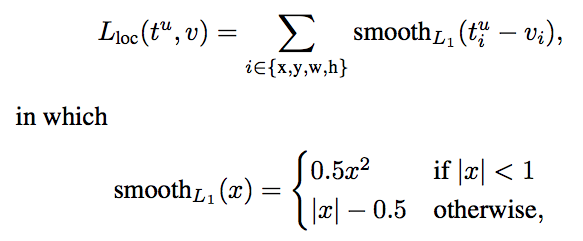
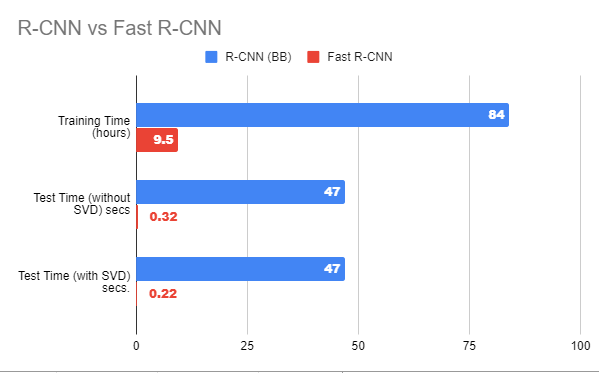
结果和结论:
- Fast R-CNN 在 VOC 2007、2010 和 2012 数据集上提供了最先进的 mAP。
- 它还大大提高了检测时间(84 对 9.5 小时)和训练时间(47 对 0.32 秒) 。
Fast R-CNN 相对于 R-CNN 的优势
- Fast R-CNN 比 R-CNN 更快的最重要原因是因为我们不需要为 CNN 模型中的每张图像传递 2000 个区域提议。相反,convNet 操作对每个图像只执行一次,并从中生成特征图。
- 因为,整个模型是一次性组合和训练的。因此,不需要功能缓存。这也减少了训练时的磁盘内存需求。
- 与 R-CNN 相比,Fast R-CNN 在 VOC 2007、10 和12数据集的大多数类别上也提高了mAP 。
参考:
- 快速 R-CNN 论文
- Fast R-CNN 纸质幻灯片