BERT模型解释——NLP
BERT (Bidirectional Encoder Representations from Transformers) 是谷歌研究院研究人员于 2018 年提出的自然语言处理模型。 当它被提出时,它在许多 NLP 和 NLU 任务上实现了最先进的准确性,例如:
- 一般语言理解评估
- 斯坦福问答数据集 SQuAD v1.1 和 v2.0
- 对抗世代的情况
在发布几天后不久,发布的开源代码包含两个版本的预训练模型 BERT BASE和 BERT LARGE ,它们在大量数据集上进行了训练。 BERT 还使用了许多以前的 NLP 算法和架构,例如半监督训练、OpenAI 转换器、ELMo 嵌入、ULMFit、转换器。
BERT 模型架构:
BERT 以 BERT BASE和 BERT LARGE两种尺寸发布。 BASE 模型用于衡量与另一种架构相当的架构的性能,而 LARGE 模型产生了研究论文中报告的最先进的结果。
半监督学习:
BERT 在不同 NLP 任务上表现良好的主要原因之一是使用了半监督学习。这意味着模型针对特定任务进行训练,使其能够理解语言的模式。训练后的模型 (BERT) 具有语言处理能力,可用于授权我们使用监督学习构建和训练的其他模型。

BERT 基本上是一个 Transformer 架构的编码器堆栈。 Transformer 架构是一个编码器-解码器网络,它在编码器端使用自注意力,在解码器端使用注意力。 BERT BASE在编码器堆栈中有 1 2 层,而 BERT LARGE在编码器堆栈中有 24 层。这些不仅仅是原始论文中描述的 Transformer 架构( 6 个编码器层)。 BERT 架构(BASE 和 LARGE)还具有比原始论文中建议的 Transformer 架构更大的前馈网络(分别为 768 和 1024 个隐藏单元)和更多的注意力头(分别为 12 和 16)。它包含512 个隐藏单元和 8 个注意力头。 BERT BASE包含 110M 参数,而 BERT LARGE包含 340M 参数。

该模型首先将CLS标记作为输入,然后是一系列单词作为输入。这里的 CLS 是一个分类标记。然后它将输入传递给上述层。每一层都应用自注意力,将结果通过前馈网络传递给下一个编码器。
该模型输出一个隐藏大小的向量(BERT BASE 为768)。如果我们想从这个模型中输出一个分类器,我们可以取对应于 CLS 令牌的输出。

现在,这个经过训练的向量可用于执行许多任务,例如分类、翻译等。
例如,该论文在分类任务中仅通过在 BERT 模型上使用单层神经网络就取得了很好的结果。
ELMo 词嵌入:
这篇文章非常适合重述 Word Embedding。它还讨论了 Word2Vec 及其实现。基本上,单词的词嵌入是根据单词的含义将单词投影到数值向量。有很多流行的词嵌入,例如 Word2vec、GloVe 等。 ELMo 与这些嵌入不同,因为它根据上下文对词进行嵌入,即上下文化词嵌入。为了生成词的嵌入,ELMo 会查看整个句子而不是一个词的固定嵌入。
Elmo 使用针对特定任务训练的双向 LSTM 来创建这些嵌入。该模型在我们数据集语言的海量数据集上进行训练,然后我们可以将其用作执行特定语言任务所需的其他架构中的组件。

ELMo 通过接受训练来预测单词序列中的下一个单词——一项称为语言建模的任务,从而获得了语言理解能力。这很方便,因为我们有大量的文本数据,这样的模型可以在没有标签的情况下学习。
ULM-Fit:NLP 中的迁移学习:
ULM-Fit 引入了一种新的语言模型和过程,以针对特定任务有效地微调该语言模型。这使 NLP 架构能够在预训练模型上执行迁移学习,类似于许多计算机视觉任务中执行的模型。
Open AI Transformer:预训练:
上述 Transformer 架构仅预训练了编码器架构。这种类型的预训练适用于机器翻译等特定任务,但对于句子分类、下一个词预测等任务,这种方法不起作用。在这个架构中,我们只训练了解码器。这种训练解码器的方法最适合下一个词预测任务,因为它掩盖了与此任务相似的未来标记(词)。
该模型有 12 个解码器层堆栈。由于没有编码器,这些解码器层只有自注意力层。
我们可以通过为它提供大量未标记的数据集(例如书籍集等)来训练该模型进行语言建模(下一个词预测)任务。

OpenAI 变压器下一个词预测
现在 Open AI Transformer 对语言有了一些了解,它可以用于执行下游任务,例如句子分类。以下是将句子分类为“垃圾邮件”或“非垃圾邮件”的架构。

OpenAI Transformers 句子分类任务
结果: BERT 为 11 个 NLP 任务提供了微调结果。在这里,我们讨论基准 NLP 任务的一些结果。
- 胶水:
通用语言理解评估任务是不同自然语言理解任务的集合。这些包括 MNLI(Multi-Genre Natural Language Inference)、QQP(Quora Question Pairs)、QNLI(Question Natural Language Inference)、SST-2(The Stanford Sentiment Treebank)、CoLA(Corpus of Linguistic Acceptability)等。 两者,BERT BASE和 BERT LARGE 明显优于之前的模型(分别为 4.5% 和 7%)。以下是 BERT BASE和 BERT LARGE与其他模型相比的结果: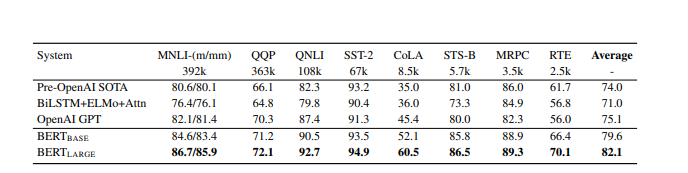
BERT 在 GLUE NLP 任务上的结果
- SQuAD v1.1 数据集
斯坦福问答数据集是一个 10 万众源问答对的集合。一个数据点包含一个问题和一个来自维基百科的包含答案的段落。任务是从文章中预测答案文本的跨度。
表现最好的 BERT(带有集成和 TriviaQA)在集成方面比顶级排行榜系统高 1.5 F1 分数,作为单个系统比顶级排行榜系统高 1.3 F1 分数。事实上,就 F1 分数而言,单个 BERT BASE 的表现优于顶级集成系统。 - SWAG(对抗性世代的情况)
SWAG 数据集包含 113k 句子完成任务,这些任务使用扎根常识推理评估最佳拟合答案。给定一个句子,任务是在四个选项中选择最合理的延续。
BERT LARGE比 OpenAI GPT 高 8.3%。它的表现甚至比专家级的人还要好。
SWAG数据集的结果如下:
SWAG 数据集的结果
结论 :
BERT 能够提高许多自然语言处理和语言建模任务的准确性(或 F1 分数)。本文提供的主要突破是允许将半监督学习用于许多 NLP 任务,从而允许在 NLP 中进行迁移学习。它也用于 Google 搜索,截至 2019 年 12 月,它已用于 70 种语言。
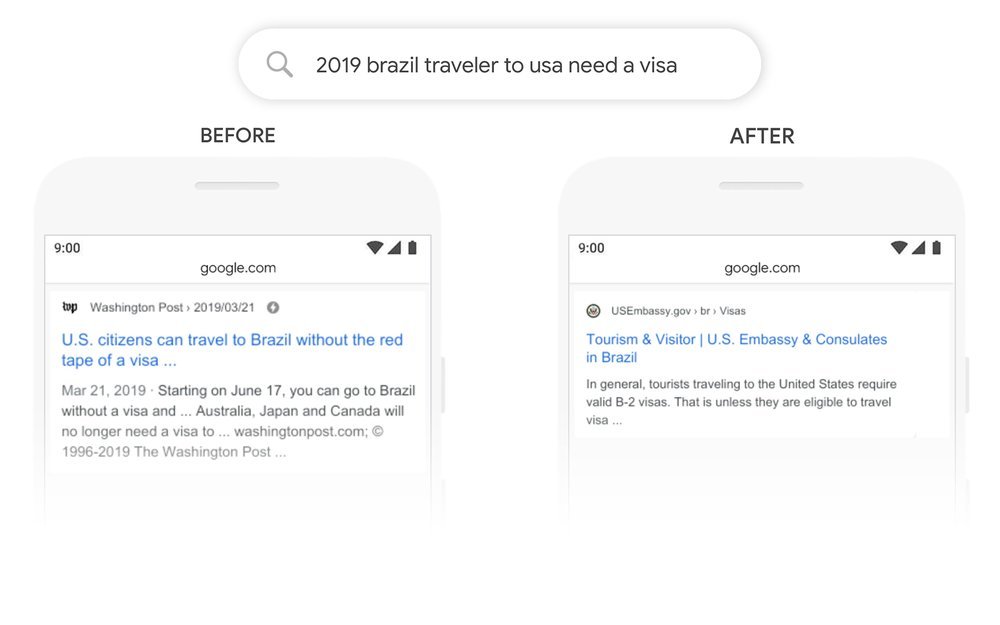
以下是使用 BERT 之前和之后在 Google 中搜索查询的一些示例。

参考:
- BERT 纸器
- 谷歌博客 : BERT
- BERT 上的 Jay Alammar 博客