理解 BERT – NLP
BERT 代表Bidirectional Representation for Transformers 。它是由 Google Research 的研究人员于 2018 年提出的。 尽管其主要目的是提高对与 Google 搜索相关的查询含义的理解。一项研究表明,谷歌每天都会遇到 15% 的新查询。因此,它需要谷歌搜索引擎对语言有更好的理解才能理解搜索查询。
提高对模型的语言理解。 BERT 是针对不同架构上的不同任务进行训练和测试的。其中一些任务与下面讨论的架构有关。
掩码语言模型:
在这个 NLP 任务中,我们用 [MASK] 标记替换了文本中 15% 的单词。然后模型预测被 [MASK] 标记替换的原始单词。除了掩码之外,掩码还混合了一些东西,以改进模型稍后进行微调的方式,因为 [MASK] 令牌在训练和微调之间造成了不匹配。在这个模型中,我们在编码器输入的顶部添加了一个分类层。我们还使用全连接层和 softmax 层计算输出的概率。 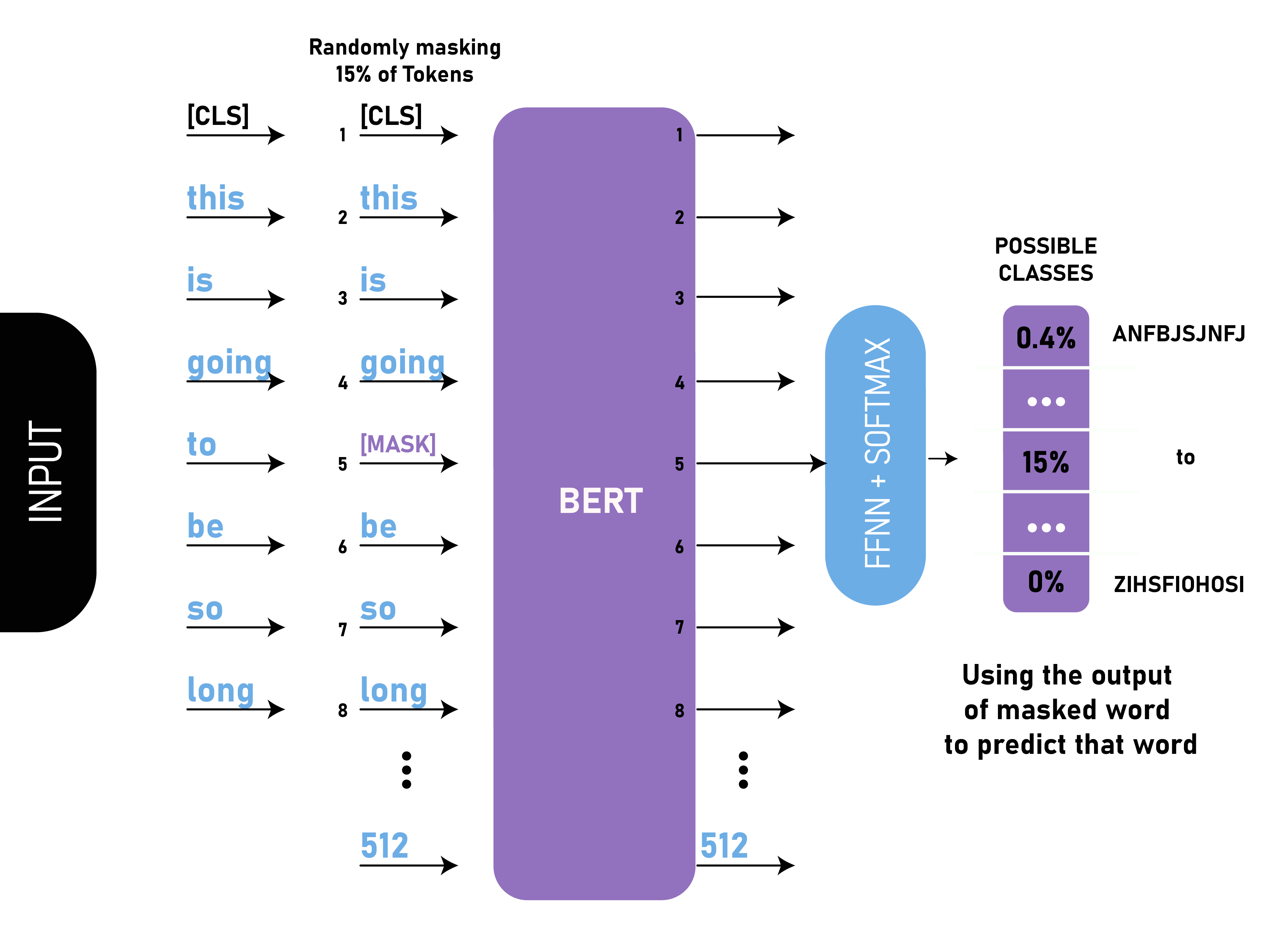
掩码语言模型:
BERT 损失函数在计算时只考虑掩码值的预测,而忽略非掩码值的预测。这有助于仅计算那些 15% 被屏蔽的单词的损失。
下一句预测:
在这个 NLP 任务中,我们提供了两个句子,我们的目标是预测第二个句子是否是原始文本中第一个句子的下一个后续句子。在训练 BERT 期间,我们从原始句子中取出 50% 的数据是下一个后续句子(标记为 isNext),50% 的时间我们取不是原始文本中的下一个句子的随机句子(标记为作为 NotNext)。由于这是一个分类任务,所以我们的第一个标记是 [CLS] 标记。该模型还使用 [SEP] 标记来分隔我们传递给模型的两个句子。 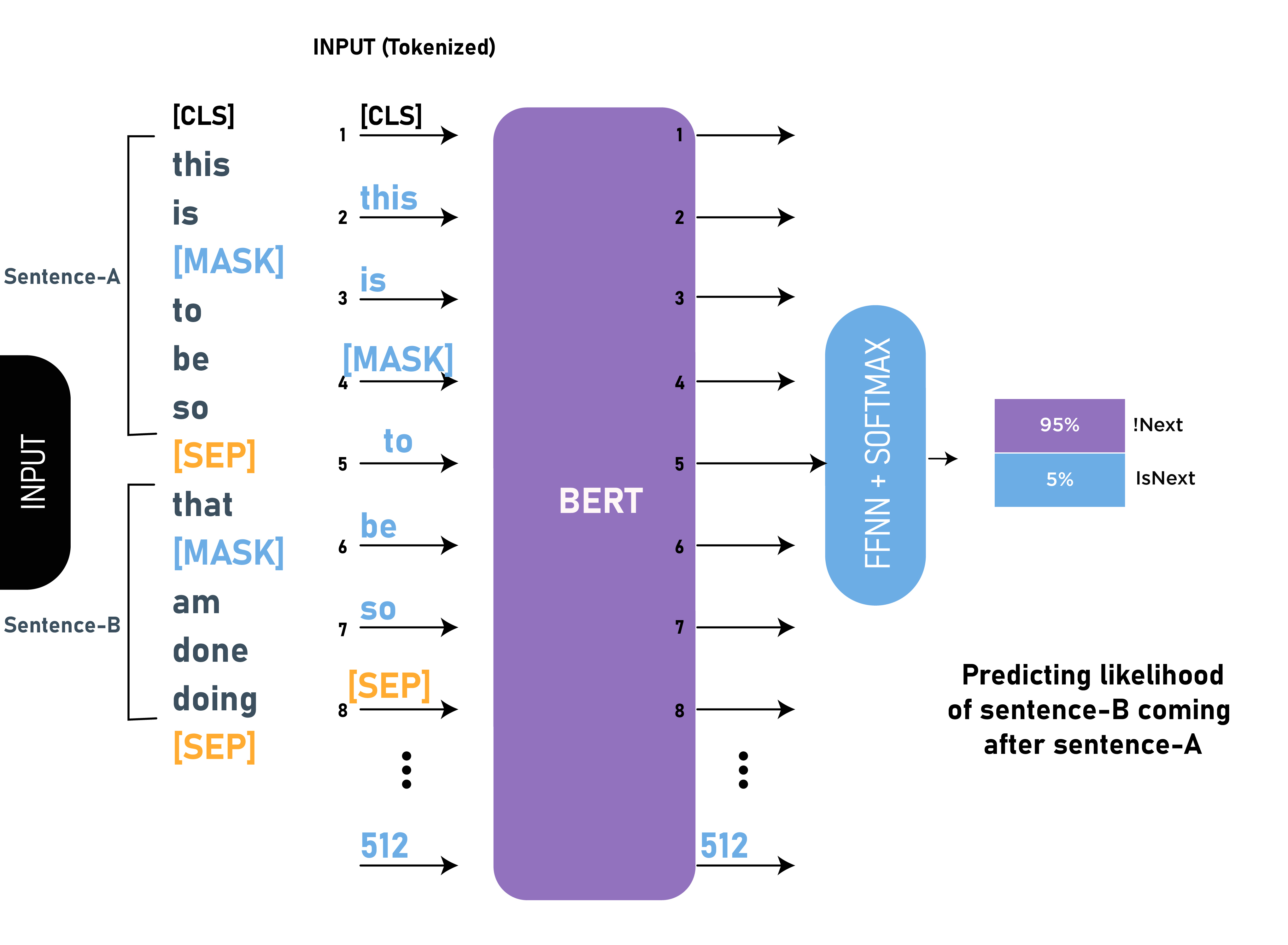
BERT 模型在此任务上获得了 97%-98% 的准确率。用任务训练模型的好处是它有助于模型理解句子之间的关系。
为不同的任务微调 BERT –
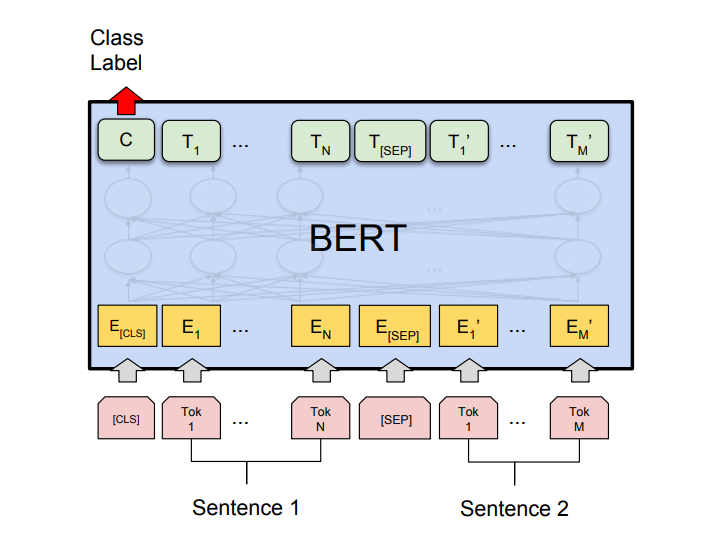
- 用于句子对分类任务的 BERT:
- MNLI: Multi-Genre Natural Language Inference 是一项大规模分类任务。在这个任务中,我们给出了一对句子。目标是确定第二个句子相对于第一个句子是蕴涵、矛盾还是中性。
- QQP :Quora Question Pairs,在这个数据集中,目标是确定两个问题在语义上是否相等。
- QNLI : Question Natural Language Inference,在这个任务中,模型需要确定第二句话是否是第一句话中提出的问题的答案。
- SWAG : Situations With Adversarial Generations 数据集包含 113k 句子分类。任务是确定第二句是否是第一句的延续。
BERT 已经针对许多句子对分类任务对其架构进行了微调,例如:
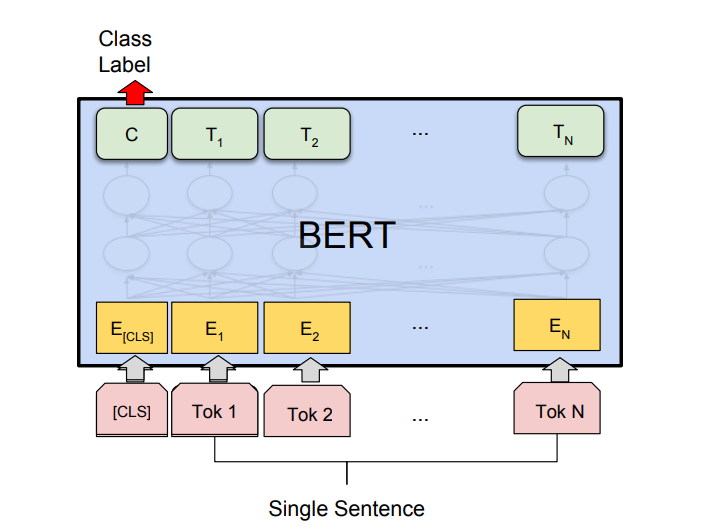
- 单句分类任务:
- SST-2: Stanford Sentiment Treebank 是一个二元句子分类任务,由从电影评论中提取的句子和句子中表达的情感注释组成。 BERT 在 SST-2 上产生了最先进的结果。
- CoLA:语言可接受性语料库是二元分类任务。此任务的目标是预测所提供的英语句子在语言上是否可接受。
- 问答任务: BERT 还生成了最先进的问答任务,例如斯坦福问答数据集(SQuAD v1.1 和 SQuAD v2.0)。在这些问答任务中,模型需要一个问题和一段话。目标是标记问题中的答案文本跨度。
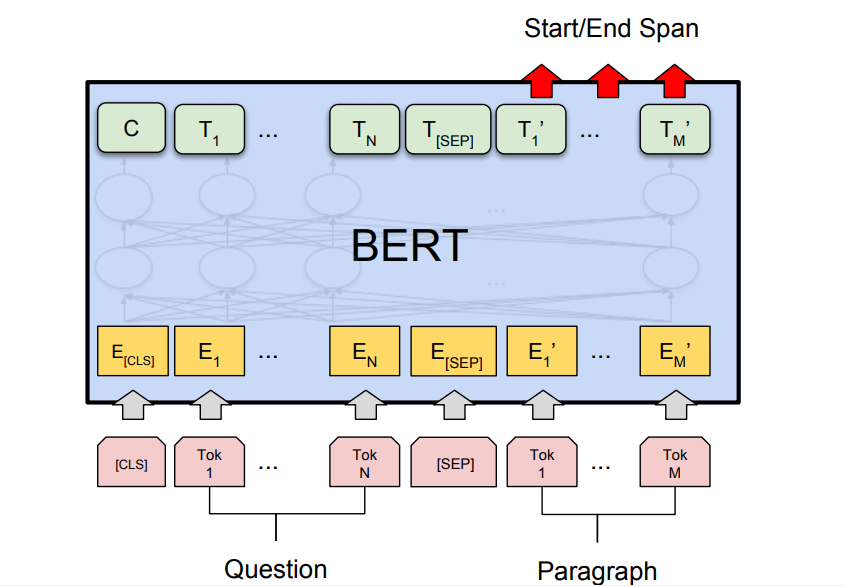
BERT 用于 Google 搜索:
正如我们上面讨论的,BERT 在问答任务上经过训练并生成了最先进的结果。这是特别由于我们在 BERT 架构中使用的变压器模型的结果。这些模型将完整的句子作为输入,而不是逐词输入。这有助于生成单词的完整上下文嵌入,并有助于更好地理解语言。此方法对于理解搜索查询背后的真实意图以提供最佳结果非常有用。 
BERT 搜索查询 从上图可以看出,应用 BERT 模型后,谷歌对搜索查询的理解更好,因此产生了更准确的结果。
结论:
BERT 已经被证明是自然语言处理和语言理解领域的一个突破,类似于 AlexNet 在计算机视觉领域所提供的。它在不同的任务中取得了最先进的结果,因此可用于许多 NLP 任务。自 2019 年 12 月起,它还在 70 种语言的 Google 搜索中使用。参考资料:
- BERT 纸器
- 谷歌博客 : BERT
- BERT 上的 Jay Alammar 博客