Julia 中的基准测试
在 Julia 中,大多数代码都经过了速度和效率检查。 Julia 的标志之一是它比其他科学计算同行( Python、R、Matlab )要快得多。为了验证这一点,我们经常倾向于比较跨各种语言运行的代码块的速度和性能。在我们尝试多种方法来解决问题的情况下,有必要确定最有效的方法,在这种情况下,我们显然会选择最快的方法。
在 Julia 中测试代码块的最传统方法之一是使用@time 宏。在 Julia 中,我们说全局对象会降低性能。
Also, since we use randomly generated values, we will seed the RNG, so that the values are consistent between trials/samples/evaluations.
Python3
# Import the library
using Random
# Using the MersenneTwister rng
# Here 1234 is a seed value
rng = MersenneTwister(1234);
# Generate random data
x = rand(rng, 1000);
# a function that considers
# x as a global variable
function prod_global()
prod = 0.0
for i in x
prod *= i
end
return prod
end;
# a function that accepts
# x as a local variable
function prod_local(x)
prod = 0.0
for i in x
prod *= i
end
return prod
end;Python3
# first run
@time prod_global()
# second run
@time prod_global()Python3
# first run
@time prod_local(x)
# second run
@time prod_local(x)Python3
# Import the library
using Random
# Using the MersenneTwister rng
# Here 1234 is a seed value
rng = MersenneTwister(1234);
# Generate random data
x = rand(rng, 1000);
# a function that considers
# x as a global variable
function sum_global()
sum = 0.0
for i in x
sum += i
end
return sum
end;
# First we force compile the function
sum_global()
# Import profiling library
using Profile
# Profile sum_global
@profile sum_global
# Print the results
Profile.print()Python3
# Make sure you run the following code
# in a fresh repl environment
# This will clear results from previous profiling
# Import the library
using Random
# Using the MersenneTwister rng
# Here 1234 is a seed value
rng = MersenneTwister(1234);
# Generate random data
x = rand(rng, 1000);
# A function that accepts
# x as a local variable
function sum_local(x)
sum = 0.0
for i in x
sum += i
end
return sum
end;
# Force compile the function
sum_local(x)
# Import the library
using Profile
# Profile sum_local()
@profile sum_local(x)
# Print the results
Profile.print()Python3
# Import the library
using Random
# Using the MersenneTwister rng
# Here 1234 is a seed value
rng = MersenneTwister(1234);
# Import the package
using BenchmarkTools
# Generate random data
x = rand(rng, 1000);
# a function that considers
# x as a global variable
function sum_global()
sum = 0.0
for i in x
sum += i
end
return sum
end;
# A function that accepts
# x as a local variable
function sum_local(x)
sum = 0.0
for i in x
sum += i
end
return sum
end;
# Benchmark the sum_global() function
@benchmark sum_global()
# Benchmark the sum_local(x) function
@benchmark sum_local(x)Python3
# @btime for sum_global()
@btime sum_global()
# @btime for sum_local(x)
@btime sum_local(x)
# @belapsed for sum_global()
@belapsed sum_global()
# @belapsed for sum_local(x)
@belapsed sum_local(x)Python3
# apply custom benchmarks
bg = @benchmark sum_global() seconds=1 time_tolerance=0.01
# apply custom benchmarks
bl = @benchmark sum_local(x) seconds=1 time_tolerance=0.01输出:

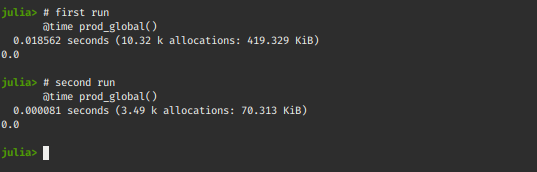
现在比较这两个函数,我们将使用我们的@time 宏。对于新环境,在第一次调用(@time prod_global())时,会编译prod_global()函数和计时所需的其他函数,因此不应认真对待首次运行的结果。
Python3
# first run
@time prod_global()
# second run
@time prod_global()
输出:
让我们尝试用局部 x 测试函数
Python3
# first run
@time prod_local(x)
# second run
@time prod_local(x)
输出:

分析 Julia 代码
对于 Julia 中的分析代码,我们使用@profile 宏。它对正在运行的代码执行测量,并生成帮助开发人员分析每行花费的时间的输出。它通常用于识别阻碍性能的代码块/功能中的瓶颈。
让我们尝试分析我们之前的示例,看看为什么全局变量会阻碍性能!
此外,我们现在将用 sum 替换乘积,这样计算在任何时候都不会趋向于无穷大或零。
Python3
# Import the library
using Random
# Using the MersenneTwister rng
# Here 1234 is a seed value
rng = MersenneTwister(1234);
# Generate random data
x = rand(rng, 1000);
# a function that considers
# x as a global variable
function sum_global()
sum = 0.0
for i in x
sum += i
end
return sum
end;
# First we force compile the function
sum_global()
# Import profiling library
using Profile
# Profile sum_global
@profile sum_global
# Print the results
Profile.print()
输出:

Python3
# Make sure you run the following code
# in a fresh repl environment
# This will clear results from previous profiling
# Import the library
using Random
# Using the MersenneTwister rng
# Here 1234 is a seed value
rng = MersenneTwister(1234);
# Generate random data
x = rand(rng, 1000);
# A function that accepts
# x as a local variable
function sum_local(x)
sum = 0.0
for i in x
sum += i
end
return sum
end;
# Force compile the function
sum_local(x)
# Import the library
using Profile
# Profile sum_local()
@profile sum_local(x)
# Print the results
Profile.print()
输出:

您一定想知道,我们如何才能简单地根据@time和一次分析得出代码的性能,并且许多此类决策是通过对各种试验的一致分析并观察代码块随时间推移的性能而做出的。 Julia 有一个扩展包来运行可靠的基准测试,名为Benchmark Tools.jl
对代码进行基准测试
使用 Benchmark Tools 对代码块进行基准测试的最传统方法之一是@benchmark宏
考虑上面sum_local(x)和sum_global()的例子:
Python3
# Import the library
using Random
# Using the MersenneTwister rng
# Here 1234 is a seed value
rng = MersenneTwister(1234);
# Import the package
using BenchmarkTools
# Generate random data
x = rand(rng, 1000);
# a function that considers
# x as a global variable
function sum_global()
sum = 0.0
for i in x
sum += i
end
return sum
end;
# A function that accepts
# x as a local variable
function sum_local(x)
sum = 0.0
for i in x
sum += i
end
return sum
end;
# Benchmark the sum_global() function
@benchmark sum_global()
# Benchmark the sum_local(x) function
@benchmark sum_local(x)
输出:
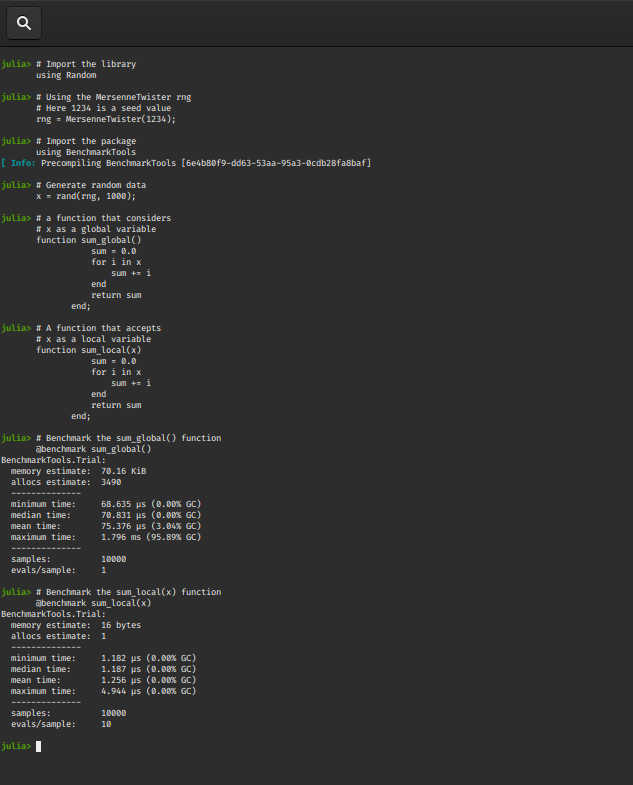
@benchmark 宏给出了许多对许多开发人员派上用场的详细信息(mem.allocs、最短时间、平均时间、中间时间、样本等),但有时我们需要快速的具体参考,例如: @btime 宏在返回表达式的值之前打印最短时间和内存分配, @belapsed 宏以秒为单位返回最短时间。
Python3
# @btime for sum_global()
@btime sum_global()
# @btime for sum_local(x)
@btime sum_local(x)
# @belapsed for sum_global()
@belapsed sum_global()
# @belapsed for sum_local(x)
@belapsed sum_local(x)
输出:

@benchmark 宏为我们提供了配置基准测试过程的方法。
您可以将以下关键字参数传递给@benchmark,并运行以配置执行过程:
- samples: It determines the number of samples to take and defaults to
BenchmarkTools.DEFAULT_PARAMETERS.samples = 10000. - seconds: The number of seconds allocated for the benchmarking process. The trial will terminate if this time is exceeded irrespective of number of samples, but atleast one sample will always be taken.
It defaults to BenchmarkTools.DEFAULT_PARAMETERS.seconds = 5. - evals: It determines the number of evaluations per sample. It defaults to
BenchmarkTools.DEFAULT_PARAMETERS.evals = 1. - overhead: The estimated loop overhead per evaluation in nanoseconds, which is automatically subtracted from every sample time measurement. The default value is
BenchmarkTools.DEFAULT_PARAMETERS.overhead = 0
- gctrial: If true, run gc() (garbage collector)before executing the benchmark’s trial.
Defaults to BenchmarkTools.DEFAULT_PARAMETERS.gctrial = true. - gcsample: If set true, run gc() before each sample.
Defaults to BenchmarkTools.DEFAULT_PARAMETERS.gcsample = false. - time_tolerance: The noise tolerance for the benchmark’s time estimate, as a percentage. This is utilized after benchmark execution, when analyzing results.
Defaults to BenchmarkTools.DEFAULT_PARAMETERS.time_tolerance = 0.05. - memory_tolerance: The noise tolerance for the benchmark’s memory estimate, as a percentage. This is utilized after benchmark execution, when analyzing results.
Defaults to BenchmarkTools.DEFAULT_PARAMETERS.memory_tolerance = 0.01.
Python3
# apply custom benchmarks
bg = @benchmark sum_global() seconds=1 time_tolerance=0.01
# apply custom benchmarks
bl = @benchmark sum_local(x) seconds=1 time_tolerance=0.01
输出:
