如何使用 pandas 在Python中进行 vLookup
Vlookup 本质上是用于垂直排列的数据。 Vlookup 是一种用于根据某些条件合并 2 个不同的数据表的操作,其中两个表之间必须至少有 1 个公共属性(列)。执行此操作后,我们得到一个表,其中包含两个表中与数据匹配的所有数据。
我们可以使用 merge()函数在 pandas 中执行 Vlookup。合并函数与 SQL 中的 Join 功能相同。我们可以对表 1 或表 2 执行合并操作。合并 2 个表可以有不同的方式。
Syntax: dataframe.merge(dataframe1, dataframe2, how, on, copy, indicator, suffixes, validate)
Parameters:
datafram1: dataframe object to be merged with.
dataframe2: dataframe object to be merged.
how: {left, right, inner, outer} specifies how merging will be done
on: specifies column or index names used for performing join.
suffixes: suffix used for overlapping columns.For exception use values (False, False).
validate: If specified, checks the kind of merging.The type of merge could be (one-one, one-many, many-one, many-many).
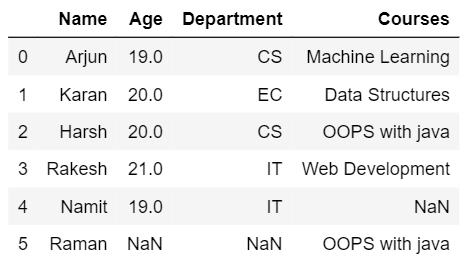
让我们考虑要对其执行操作的 2 个表。第一个表包含学生的信息,第二列包含他们注册的各个课程的信息。下面的代码说明了两个表中包含的信息。
Python3
# import pandas
import pandas as pd
# read csv data
df1 = pd.read_csv('Student_data.csv')
df2 = pd.read_csv('Course_enrolled.csv')
print(df1)
print(df2)Python3
# import pandas
import pandas as pd
# read csv data
df1 = pd.read_csv('Student_data.csv')
df2 = pd.read_csv('Course_enrolled.csv')
inner_join = pd.merge(df1,
df2,
on ='Name',
how ='inner')
inner_joinPython3
# import pandas
import pandas as pd
# read csv data
df1 = pd.read_csv('Student_data.csv')
df2 = pd.read_csv('Course_enrolled.csv')
Left_join = pd.merge(df1,
df2,
on ='Name',
how ='left')
Left_joinPython3
# import pandas
import pandas as pd
# read csv data
df1 = pd.read_csv('Student_data.csv')
df2 = pd.read_csv('Course_enrolled.csv')
Right_join = pd.merge(df1,
df2,
on ='Name',
how ='right')
Right_joinPython3
# import pandas
import pandas as pd
# read csv data
df1 = pd.read_csv('Student_data.csv')
df2 = pd.read_csv('Course_enrolled.csv')
Outer_join = pd.merge(df1,
df2,
on ='Name',
how ='outer')
Outer_join输出

对不同类型的连接执行 Vlook
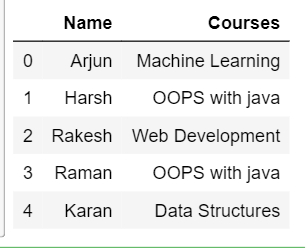
- 内连接:内连接仅生成两行都满足条件的行的输出数据框。要执行内部连接,您可以在 how 中指定inner作为关键字。
例子:
Python3
# import pandas
import pandas as pd
# read csv data
df1 = pd.read_csv('Student_data.csv')
df2 = pd.read_csv('Course_enrolled.csv')
inner_join = pd.merge(df1,
df2,
on ='Name',
how ='inner')
inner_join
- 输出
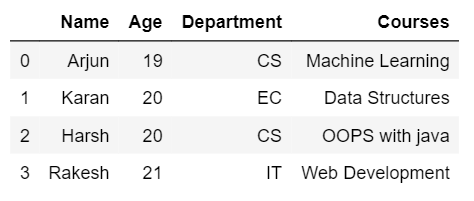
- 左连接:左连接操作提供来自第一个数据帧的所有行和来自第二个数据帧的匹配行。如果第二个数据帧中的行不匹配,那么它们将被 NaN 替换。
例子:
Python3
# import pandas
import pandas as pd
# read csv data
df1 = pd.read_csv('Student_data.csv')
df2 = pd.read_csv('Course_enrolled.csv')
Left_join = pd.merge(df1,
df2,
on ='Name',
how ='left')
Left_join
- 输出:
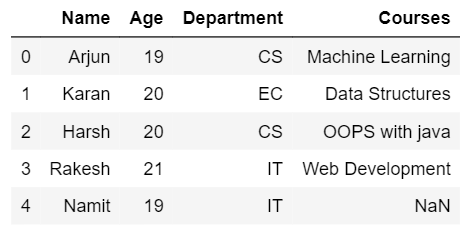
- 右连接:右连接有点类似于左连接,其中输出数据帧将包含来自第二个数据帧的所有行和来自第一个数据帧的匹配行。如果第一行中的行不匹配,则它们将被替换为 NaN
Python3
# import pandas
import pandas as pd
# read csv data
df1 = pd.read_csv('Student_data.csv')
df2 = pd.read_csv('Course_enrolled.csv')
Right_join = pd.merge(df1,
df2,
on ='Name',
how ='right')
Right_join
- 输出
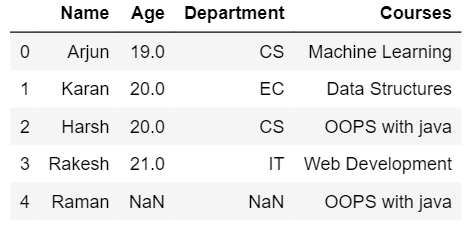
- 外连接:外连接提供由两个数据帧中的行组成的输出数据帧。如果行匹配,则将显示值,否则将为不匹配的行显示 NaN。
例子:
Python3
# import pandas
import pandas as pd
# read csv data
df1 = pd.read_csv('Student_data.csv')
df2 = pd.read_csv('Course_enrolled.csv')
Outer_join = pd.merge(df1,
df2,
on ='Name',
how ='outer')
Outer_join
- 输出