使用 Pandas 计算每组的唯一值
先决条件:熊猫
在本文中,我们将使用 Pandas 查找和计算组/列中存在的唯一值。唯一值是在数据集中仅出现一次的不同值,或者将第一次出现的重复值计为唯一值。
方法:
- 导入熊猫库。
- 使用 DataFrame()函数导入或创建数据帧,其中将数据作为要在其上创建数据帧的参数传递,将其命名为“df”,或用于导入数据集使用 pandas.read_csv()函数,其中传递路径和数据集的名称。
- 选择要检查或计算唯一值的列。
- 为了查找唯一值,我们使用了 pandas 提供的 unique()函数并将其存储在一个变量中,命名为“unique_values”。
Syntax: pandas.unique(df(column_name)) or df[‘column_name’].unique()
- 它将给出该组/列中存在的唯一值。
- 为了计算唯一值的数量,我们必须首先将名为“count”的变量 let 初始化为 0,然后必须为“unique_values”运行 for 循环并计算循环运行的次数并增加“count”的值' 由 1
- 然后打印“计数”,此存储值是该特定组/列中存在的唯一值的数量。
- 为了查找唯一值在特定列中重复的次数,我们使用了 Pandas 提供的 value_counts()函数。
Syntax: pandas.value_counts(df[‘column_name’] or df[‘column_name’].value_counts()
- 这将给出每个唯一值在该特定列中重复的次数。
为了更好地理解主题。让我们举一些例子并实现上面在方法中讨论的功能。
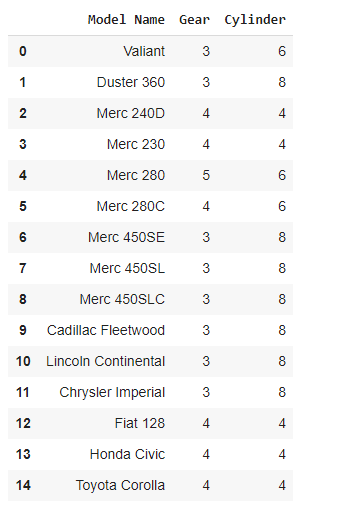
示例 1:使用 Pandas 库创建 DataFrame。
Python
# importing library
import pandas as pd
# storing the data of cars in the dictionary
car_data = {'Model Name': ['Valiant',
'Duster 360',
'Merc 240D',
'Merc 230',
'Merc 280',
'Merc 280C',
'Merc 450SE',
'Merc 450SL',
'Merc 450SLC',
'Cadillac Fleetwood',
'Lincoln Continental',
'Chrysler Imperial',
'Fiat 128',
'Honda Civic',
'Toyota Corolla'],
'Gear': [3, 3, 4, 4, 5, 4, 3, 3,
3, 3, 3, 3, 4, 4, 4],
'Cylinder': [6, 8, 4, 4, 6, 6, 8,
8, 8, 8, 8, 8, 4, 4, 4]}
# creating DataFrame for the data using
# pandas DataFrame function.
car_df = pd.DataFrame(car_data)
# printing the dataframe
car_dfPython
# importing libraries
import pandas as pd
# storing the data of cars in the dictionary
car_data = {'Model Name': ['Valiant',
'Duster 360',
'Merc 240D',
'Merc 230',
'Merc 280',
'Merc 280C',
'Merc 450SE',
'Merc 450SL',
'Merc 450SLC',
'Cadillac Fleetwood',
'Lincoln Continental',
'Chrysler Imperial',
'Fiat 128',
'Honda Civic',
'Toyota Corolla'],
'Gear': [3, 3, 4, 4, 5, 4, 3, 3,
3, 3, 3, 3, 4, 4, 4],
'Cylinder': [6, 8, 4, 4, 6, 6, 8,
8, 8, 8, 8, 8, 4, 4, 4]}
# creating DataFrame for the data using pandas
car_df = pd.DataFrame(car_data)
# printing the unique values present in the Gear column
# finding unique values present
# in the Gear column using unique() function
print(f"Unique values present in Gear column are: {car_df['Gear'].unique()}")
# printing the unique values present
# in the Cylinder column
# finding unique values present in the
# Cylinder column using unique() function
print(f"Unique values present in Cylinder column are: {car_df['Cylinder'].unique()}")Python
# importing libraries
import pandas as pd
# storing the data of cars in the dictionary
car_data = {'Model Name': ['Valiant',
'Duster 360',
'Merc 240D',
'Merc 230',
'Merc 280',
'Merc 280C',
'Merc 450SE',
'Merc 450SL',
'Merc 450SLC',
'Cadillac Fleetwood',
'Lincoln Continental',
'Chrysler Imperial',
'Fiat 128',
'Honda Civic',
'Toyota Corolla'],
'Gear': [3, 3, 4, 4, 5, 4, 3, 3,
3, 3, 3, 3, 4, 4, 4],
'Cylinder': [6, 8, 4, 4, 6, 6, 8, 8,
8, 8, 8, 8, 4, 4, 4]}
# creating DataFrame for the data using pandas
car_df = pd.DataFrame(car_data)
# finding unique values present in the
# groups using unique() function
unique_gear = pd.unique(car_df.Gear)
unique_cyl = pd.unique(car_df.Cylinder)
# printing the unique values present in the Gear column
print(f"Unique values present in Gear column are: {unique_gear}")
# printing the unique values present in the Cylinder column
print(f"Unique values present in Cylinder column are: {unique_cyl}")Python
# importing libraries
import pandas as pd
# storing the data of cars in the dictionary
car_data = {'Model Name': ['Valiant',
'Duster 360',
'Merc 240D',
'Merc 230',
'Merc 280',
'Merc 280C',
'Merc 450SE',
'Merc 450SL',
'Merc 450SLC',
'Cadillac Fleetwood',
'Lincoln Continental',
'Chrysler Imperial',
'Fiat 128',
'Honda Civic',
'Toyota Corolla'],
'Gear': [3, 3, 4, 4, 5, 4, 3,
3, 3, 3, 3, 3, 4, 4, 4],
'Cylinder': [6, 8, 4, 4, 6, 6, 8,
8, 8, 8, 8, 8, 4, 4, 4]}
# creating DataFrame for the data using pandas
car_df = pd.DataFrame(car_data)
# counting number of times each unique values
# present in the particular group using
# value_counts() function
gear_count = pd.value_counts(car_df.Gear)
cyl_count = pd.value_counts(car_df.Cylinder)
# another way of obtaining the same output
g_count = car_df['Gear'].value_counts()
cy_count = car_df['Cylinder'].value_counts()
print('----Output from first method-----')
# printing number of times each unique
# values present in the particular group
print(gear_count)
print(cyl_count)
# printing output from the second method
print('----Output from second method----')
print(g_count)
print(cy_count)Python
# importing libraries
import pandas as pd
# storing the data of cars in the dictionary
car_data = {'Model Name': ['Valiant',
'Duster 360',
'Merc 240D',
'Merc 230',
'Merc 280',
'Merc 280C',
'Merc 450SE',
'Merc 450SL',
'Merc 450SLC',
'Cadillac Fleetwood',
'Lincoln Continental',
'Chrysler Imperial',
'Fiat 128',
'Honda Civic',
'Toyota Corolla'],
'Gear': [3, 3, 4, 4, 5, 4, 3, 3,
3, 3, 3, 3, 4, 4, 4],
'Cylinder': [6, 8, 4, 4, 6, 6, 8,
8, 8, 8, 8, 8, 4, 4, 4]}
# creating DataFrame for the data using pandas
car_df = pd.DataFrame(car_data)
# finding unique values present in the particular group.
name_count = pd.unique(car_df['Model Name'])
gear_count = pd.unique(car_df.Gear)
cyl_count = pd.unique(car_df.Cylinder)
# initializing variable to 0 for counting
name_unique = 0
gear_unique = 0
cyl_unique = 0
# writing separate for loop of each groups
for item in name_count:
name_unique += 1
for item in gear_count:
gear_unique += 1
for item in gear_count:
cyl_unique += 1
# printing the number of unique values present in each group
print(f'Number of unique values present in Model Name: {name_unique}')
print(f'Number of unique values present in Gear: {gear_unique}')
print(f'Number of unique values present in Cylinder: {cyl_unique}')输出:
示例 2:打印每个组中存在的唯一值。
Python
# importing libraries
import pandas as pd
# storing the data of cars in the dictionary
car_data = {'Model Name': ['Valiant',
'Duster 360',
'Merc 240D',
'Merc 230',
'Merc 280',
'Merc 280C',
'Merc 450SE',
'Merc 450SL',
'Merc 450SLC',
'Cadillac Fleetwood',
'Lincoln Continental',
'Chrysler Imperial',
'Fiat 128',
'Honda Civic',
'Toyota Corolla'],
'Gear': [3, 3, 4, 4, 5, 4, 3, 3,
3, 3, 3, 3, 4, 4, 4],
'Cylinder': [6, 8, 4, 4, 6, 6, 8,
8, 8, 8, 8, 8, 4, 4, 4]}
# creating DataFrame for the data using pandas
car_df = pd.DataFrame(car_data)
# printing the unique values present in the Gear column
# finding unique values present
# in the Gear column using unique() function
print(f"Unique values present in Gear column are: {car_df['Gear'].unique()}")
# printing the unique values present
# in the Cylinder column
# finding unique values present in the
# Cylinder column using unique() function
print(f"Unique values present in Cylinder column are: {car_df['Cylinder'].unique()}")
输出:

从上面的输出图像中,我们可以观察到我们从两个组中获得了三个唯一值。
示例 3:另一种查找每个组中存在的唯一值的方法。
Python
# importing libraries
import pandas as pd
# storing the data of cars in the dictionary
car_data = {'Model Name': ['Valiant',
'Duster 360',
'Merc 240D',
'Merc 230',
'Merc 280',
'Merc 280C',
'Merc 450SE',
'Merc 450SL',
'Merc 450SLC',
'Cadillac Fleetwood',
'Lincoln Continental',
'Chrysler Imperial',
'Fiat 128',
'Honda Civic',
'Toyota Corolla'],
'Gear': [3, 3, 4, 4, 5, 4, 3, 3,
3, 3, 3, 3, 4, 4, 4],
'Cylinder': [6, 8, 4, 4, 6, 6, 8, 8,
8, 8, 8, 8, 4, 4, 4]}
# creating DataFrame for the data using pandas
car_df = pd.DataFrame(car_data)
# finding unique values present in the
# groups using unique() function
unique_gear = pd.unique(car_df.Gear)
unique_cyl = pd.unique(car_df.Cylinder)
# printing the unique values present in the Gear column
print(f"Unique values present in Gear column are: {unique_gear}")
# printing the unique values present in the Cylinder column
print(f"Unique values present in Cylinder column are: {unique_cyl}")
输出:

输出是相似的,但不同的是,在这个例子中,我们通过使用 pd.unique()函数建立了每个组中存在的唯一值,我们在其中传递了我们的数据帧列。
示例 4:计算每个唯一值重复的次数。
Python
# importing libraries
import pandas as pd
# storing the data of cars in the dictionary
car_data = {'Model Name': ['Valiant',
'Duster 360',
'Merc 240D',
'Merc 230',
'Merc 280',
'Merc 280C',
'Merc 450SE',
'Merc 450SL',
'Merc 450SLC',
'Cadillac Fleetwood',
'Lincoln Continental',
'Chrysler Imperial',
'Fiat 128',
'Honda Civic',
'Toyota Corolla'],
'Gear': [3, 3, 4, 4, 5, 4, 3,
3, 3, 3, 3, 3, 4, 4, 4],
'Cylinder': [6, 8, 4, 4, 6, 6, 8,
8, 8, 8, 8, 8, 4, 4, 4]}
# creating DataFrame for the data using pandas
car_df = pd.DataFrame(car_data)
# counting number of times each unique values
# present in the particular group using
# value_counts() function
gear_count = pd.value_counts(car_df.Gear)
cyl_count = pd.value_counts(car_df.Cylinder)
# another way of obtaining the same output
g_count = car_df['Gear'].value_counts()
cy_count = car_df['Cylinder'].value_counts()
print('----Output from first method-----')
# printing number of times each unique
# values present in the particular group
print(gear_count)
print(cyl_count)
# printing output from the second method
print('----Output from second method----')
print(g_count)
print(cy_count)
输出:
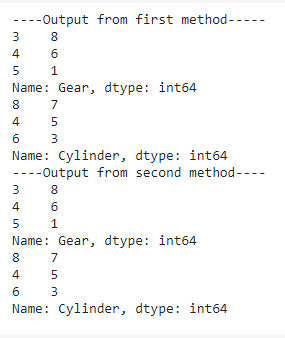
从上面的输出图像中,我们从两种编写代码的方法中得到了相同的结果。
我们可以观察到,在 Gear 列中,我们获得了唯一值 3,4 和 5,它们分别重复了 8,6 和 1 次,而在 Cylinder 列中,我们获得了唯一值 8,4 和 6,它们分别重复了 7,5 和 3 次分别。
示例 5:计算组中存在的唯一值的数量。
Python
# importing libraries
import pandas as pd
# storing the data of cars in the dictionary
car_data = {'Model Name': ['Valiant',
'Duster 360',
'Merc 240D',
'Merc 230',
'Merc 280',
'Merc 280C',
'Merc 450SE',
'Merc 450SL',
'Merc 450SLC',
'Cadillac Fleetwood',
'Lincoln Continental',
'Chrysler Imperial',
'Fiat 128',
'Honda Civic',
'Toyota Corolla'],
'Gear': [3, 3, 4, 4, 5, 4, 3, 3,
3, 3, 3, 3, 4, 4, 4],
'Cylinder': [6, 8, 4, 4, 6, 6, 8,
8, 8, 8, 8, 8, 4, 4, 4]}
# creating DataFrame for the data using pandas
car_df = pd.DataFrame(car_data)
# finding unique values present in the particular group.
name_count = pd.unique(car_df['Model Name'])
gear_count = pd.unique(car_df.Gear)
cyl_count = pd.unique(car_df.Cylinder)
# initializing variable to 0 for counting
name_unique = 0
gear_unique = 0
cyl_unique = 0
# writing separate for loop of each groups
for item in name_count:
name_unique += 1
for item in gear_count:
gear_unique += 1
for item in gear_count:
cyl_unique += 1
# printing the number of unique values present in each group
print(f'Number of unique values present in Model Name: {name_unique}')
print(f'Number of unique values present in Gear: {gear_unique}')
print(f'Number of unique values present in Cylinder: {cyl_unique}')
输出:

从上面的输出图像中,我们可以观察到我们分别在 Model Name、Gear 和 Cylinder 列中获得了 15,3 和 3 个唯一值。