在 ScrapingHub 上部署 Scrapy spider
什么是 ScrapingHub?
Scrapy 是一个用于网络爬虫的开源框架。这个框架是用Python编写的,最初是为网页抓取而设计的。 Web 抓取也可用于使用 API 提取数据。 ScrapingHub 提供从网页抓取数据的整个服务,即使是复杂的网页。
为什么选择 ScrapingHub?
假设一个网站提供 1-input 字段,并根据搜索查询返回一个响应。动机是通过输入输入并获得响应来获取所有数据。现在这个输入字段可以有从“0000”字符串到“9999”字符串的数字,所以简而言之,需要给出10000个输入,以便可以从网站获取所有结果。现在对于每个请求,假设为“0000”,它将需要 4 到 5 分钟,作为响应,您将获得 1000 多个数据字段。它可能会有所不同,因为最后,网站将返回所有数字以“0000”结尾的数据,而对于网站来说,查询和返回它需要时间。所以如果我们做一些小数学,那么,10000 * 5 = 50000 分钟,这意味着大约 35 天。
因此,对于初学者来说,可以使用Python 2.7 的 mechanize 模块并查询它,但最后,它需要 35 天通过不间断地运行 PC/笔记本电脑来完成。另一种解决方案是可以使用多线程和多处理来避免这种情况,但是以有组织的方式保存数据并克服这种复杂性将花费大量时间。但是使用Scrapy会节省大量时间。尽管如此,我们仍然需要运行这个脚本至少 1-3 天,因为我们正在讨论抓取数百万个数据。所以要克服这个问题,最好的选择是借助ScrapingHub 。
ScrapingHub 提供了在云端部署 Scrapy 蜘蛛并执行它的功能。作为回报,它将运行我们的蜘蛛 24 小时(免费用户)或 7 天(付费用户),这是值得的。这就是为什么人们可以使用 ScrapingHub 来节省时间和成本的原因。
这该怎么做 :
第 1 步:在本地机器上创建 Spider
在上一篇文章中,我们创建了一个简单的蜘蛛来抓取网页并获取该网站上存在的所有 URL。同样,只需添加一个额外的功能,通过在脚本中维护 set 并在添加之前进行交叉检查来避免抓取重复的 url。
# importing scrapy module
import scrapy
class ExtractUrls(scrapy.Spider):
# Name of the spider
crawled = set()
# Set to avoiding duplicate url
name = "extract"
def start_requests(self):
# Starting url mentioned
urls = ['https://www.geeksforgeeks.org', ]
for url in urls:
yield scrapy.Request(url = url,
callback = self.parse)
def parse(self, response):
title = response.css('title::text').extract_first()
links = response.css('a::attr(href)').extract()
for link in links:
yield
{
'title': title,
'links': link
}
if ('geeksforgeeks' in link and
link not in self.crawled):
self.crawled.update(link)
yield scrapy.Request(url = link,
callback = self.parse)
scrapy crawl extract -o links.json
运行这个蜘蛛后,应该可以成功抓取并保存在 links.json 中,但我们需要节省时间,至少要运行 24 小时。所以我们将在 ScrapingHub 上部署这个蜘蛛。第 2 步:在 ScrapingHub 创建帐户
进入 ScrapingHub 登录页面,使用 Google 或 Github 登录。它将重定向到仪表板。

现在单击创建项目并提及项目名称。点击 Scrapy 按钮,因为我们的蜘蛛是用 Scrapy 框架构建的。
单击后,您将被重定向到项目仪表板,并将看到两个部署选项。
1. 使用 CLI 部署
2. 使用 Github 部署
使用 CLIm 执行此操作,因为它更受欢迎。所以让我们切换回我们的本地项目配置一些设置。第 3 步:配置
pip install shubshub loginshub deploy ID
在 Spiders 仪表板部分,用户可以看到准备好的蜘蛛。只需单击蜘蛛名称和运行按钮。免费用户将免费获得 1 个单元,这表明用户最多可以运行一个蜘蛛 24 小时。之后,它将自动停止。用户可以购买单位以延长时间段。 
通过单击正在运行的作业部分下的项目,它将被重定向到另一个页面,该页面将显示当时被抓取的所有项目。工作部分将显示图表;显示有关蜘蛛的统计信息。该图是运行蜘蛛 5-6 小时后的完美可视化。
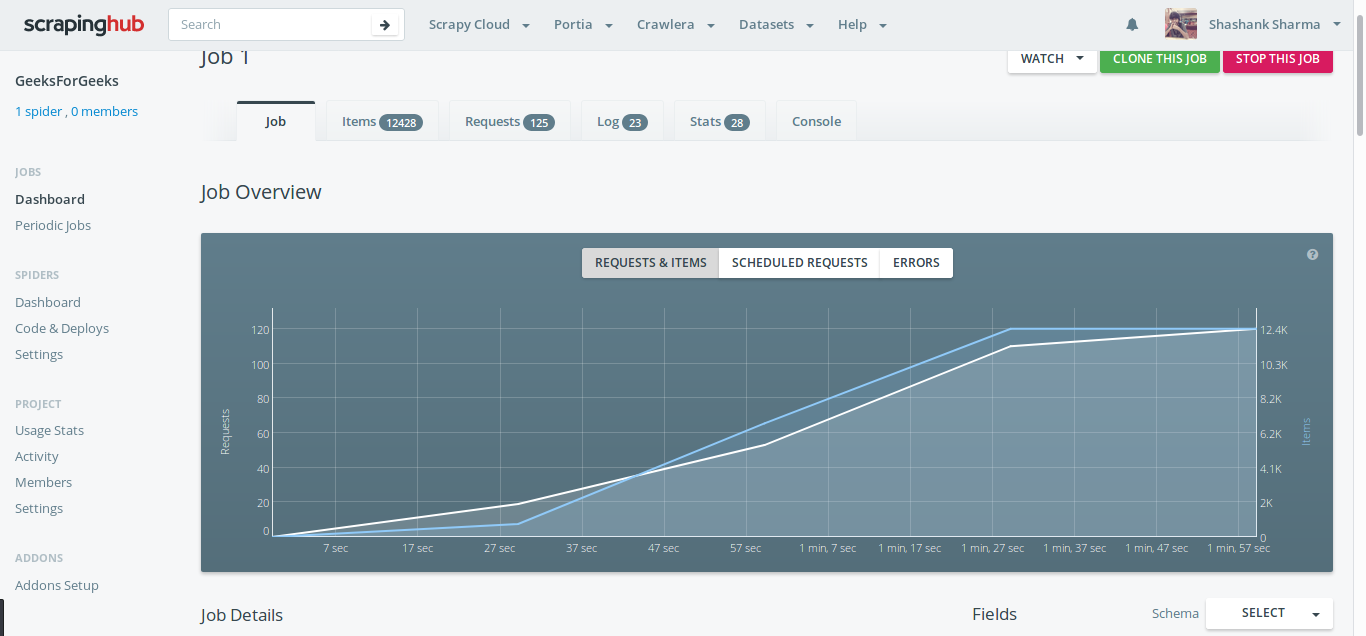
要在本地机器中获取数据,请返回项目部分,然后在右上角单击导出按钮。它将显示各种格式,如 CSV、JSON、JSON 行、XML。值得注意的是,这个功能真的很有用,真的可以节省很多时间。
使用 ScrapingHub,只需部署蜘蛛并以首选格式下载它,就可以在短短几天内抓取大约数百万条数据。
注意:抓取任何网页都不是合法活动。未经许可不得进行任何抓取操作。