Scrapy – 选择器
Scrapy Selectors 顾名思义就是用来选择一些东西的。如果我们谈论 CSS,那么还有用于选择 CSS 效果并将其应用于 HTML 标签和文本的选择器。
在 Scrapy 中,我们使用选择器来提及要被我们的蜘蛛抓取的网站部分。因此,要从站点中抓取正确的数据,选择正确表示数据的标签非常重要。有很多工具可以用来做这件事。
选择器的类型:
在Scrapy中,主要有两种选择器,即CSS选择器和XPath选择器。它们都执行相同的函数并选择相同的文本或数据,但它们传递参数的格式不同。
- CSS 选择器:由于 CSS 语言定义在任何 HTML 文件中,所以我们可以使用它们的选择器作为在 Scrapy 中选择 HTML 文件部分的一种方式。
- XPath 选择器:它是一种用于在 XML 文档中选择节点的语言,因此它也可以在 HTML 文件中使用,因为 HTML 文件也可以表示为 XML 文档。
描述:
让我们有一个 HTML 文件 (index.html),如下所示,我们将使用我们的 Spider 来废弃它,看看选择器是如何工作的。我们将在 Scrapy Shell 上工作以提供选择数据的命令。
HTML
Scrapy-Selectors
This is H1 Tag
This is Class Selectors SPAN tag
HTML
Scrapy-Selectors
This is H1 Tag
This is Second H1 Tag
This is Third H1 Tag
This is Class Selectors SPAN tag
下面给出的是我们将使用的 Scrapy Shell 的视图:
打开shell的命令:
Scrapy shell file:///C:/Users/Dipak/Desktop/index.html
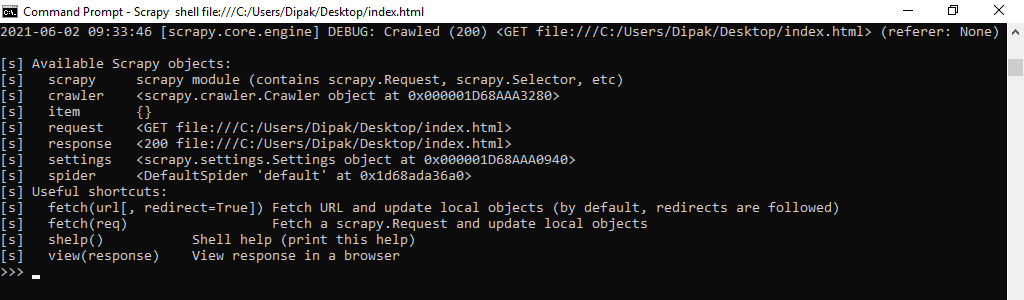
Scrapy Shell 已激活以在 Index.html 文件上抓取蜘蛛。
使用选择器:
现在我们将讨论如何在 Scrapy 中使用选择器。由于主要有两种类型,如下所示:
CSS 选择器:
在不同情况下使用 CSS 选择器有多种格式。它们如下所示:
- 非常基本的开始是从选择 HTML 文件中的基本标签开始,例如 标签、、 等。所以下面给出的是使用 Scrapy 在 HTML 文件中选择任何标签的基本格式。
Shell Command : response.css('html').get()
# Here response object calls CSS selector method to
# target HTML tag and get() method
# is used to select everything inside the HTML tag.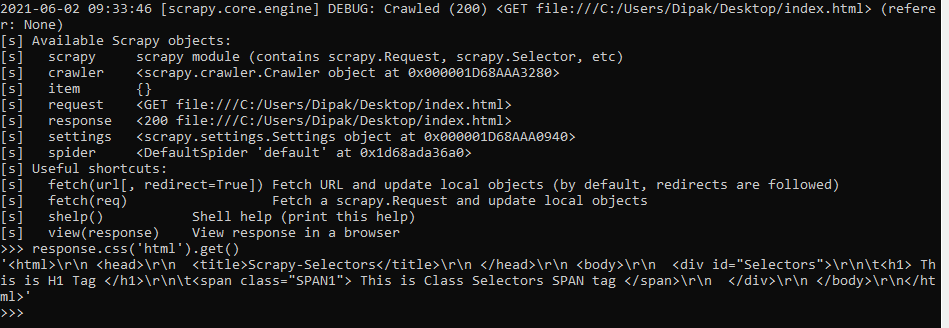
输出:HTML 文件的全部内容被选中。
- 所以,现在是时候修改我们的选择方式了,如果我们只想选择标签的内部文本或者只想选择任何特定标签的属性,那么我们可以遵循以下给出的语法:
# To select the text inside the Tags
# excluding tags we have to use (::text)
# as our extension.
response.css('h1::text').get()
# To select the attributes details of
# any HTML tag we have to use below
# given syntax:
response.css('span').attrib['class']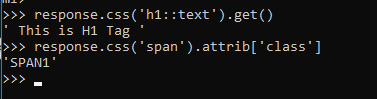
以上命令的输出。
- 如果 HTML 文件中有许多相同类型的标签,那么我们可以使用.getall() 方法而不是.get()来选择所有标签。它返回所选标签及其数据的列表。
- 如果文件中没有提到我们必须选择的标签,那么 CSS 选择器将不返回任何内容。如果未找到任何内容,我们还可以提供要返回的默认数据。

什么都不选。
XPath 选择器:
这些选择器的工作方式类似于 CSS 选择器的工作方式,只是语法不同。
下面是可以写在XPATH中进行选择的附加费,我们之前做过的。
# This is to select the text part of
# title tag using XPATH
response.xpath('//title/text()')
response.xpath('//title/text()').get()
# This is how to select attributes
response.xpath('//span/@class').get()
XPATH 选择器。
特性:
1. 我们可以将选择器相互嵌套。因为如果我们的 HTML 文件可以在 div 标签内包含元素,那么我们可以嵌套选择器来选择其中的特定元素。为了实现这一点,我们首先必须选择 div 标签内的所有元素,然后我们可以从中选择任何特定元素。
div_tag = response.xpath('//div')
div_tag.getall()
for tags in div_tag:
tag = tags.xpath('.//h1').get()
print({tag})
在选择器中使用嵌套
2. 接下来,我们也可以将选择器与正则表达式一起使用。如果我们不知道属性或元素的名称是什么,那么我们也可以使用正则表达式进行选择。为此,我们有一个名为 (.re()) 的方法。
.re()方法用于根据内容匹配选择标签。如果 HTML 标签内的内容与输入的正则表达式匹配,则此方法返回该内容的列表。在上面的 HTML 文件中,我们在 DIV 标签中有两个名为 h1 和 span 的标签,并且这两个标签中的文本具有相同的开头即“This is”。因此,要根据正则表达式选择它们,我们必须形成它们的正则表达式,如下所示:
regexp = r’This\sis\s*(.*)’ and we have to input this in our .re() method
所以我们的代码变成
response.css(‘#Selectors *::text’).re(r’This\sis\s*(.*)’)

使用正则表达式选择文本
3. 刮刮蜘蛛也支持 EXSLT 正则表达式。我们可以使用它的方法根据一些新的正则表达式来选择项目。此扩展提供了两个不同的命名空间以在 XPath 中使用
- re:用于制作正则表达式。
- set:用于设置操作
我们可以使用这些命名空间来修改在我们的 Xpath 方法中指定的 select 语句。
以下是给定示例之一:
假设我们在 HTML 文件中添加了两个 h1 标签并命名它们的类,现在它看起来像:
HTML
Scrapy-Selectors
This is H1 Tag
This is Second H1 Tag
This is Third H1 Tag
This is Class Selectors SPAN tag
现在,如果我们想使用正则表达式选择两个 H1 标签,那么我们可以看到我们必须首先选择在 id 部分具有起始字符串的标签,而结束整数无关紧要。
所以这个代码:
response.xpath(‘//h1[re:test(@class, “FirstH\d$”)]’).getall()
这里我们使用 re:test 方法在 h1 标签的 class 属性上指定和测试我们的正则表达式,regexp 只选择那些类属性值以整数结尾的 h1 标签。

这是在scrapy的选择器中使用EXSLT的一个例子。
4. 如果需要,我们可以将两个选择器合并在一起,以增强选择方式。
response.css('span').xpath('@class').get()
# CSS is used to select tag and XPATH is
# used to select attribute
合并选择器。
笔记:
- 在 XPath 中,当我们使用选择器的嵌套属性时,我们应该注意有关相对 XPath 的事实。考虑我们选择了一个 div 标签,如下所示:
div_tag = response.xpath(‘//div’)
这将选择 div 标签和该标签内的所有元素。现在假设 div 标签中包含一些 标签。现在,如果我们想使用嵌套选择器并选择 标签,那么我们将编写
for a in div_tag.xpath(‘.//a’):
这是一个相对路径,它告诉蜘蛛只从上面选择的 div 标签内的路径中选择标签元素。如果我们写——
for a in div_tag(‘//a’):
它将选择 HTML 文档中的所有标签。所以我们应该注意相对路径。
- 我们可以使用名为SelectorGadget 的Google Chrome 扩展程序来简化选择任务。由于今天的所有网站,如果我们检查它们,都会有非常冗长且难以理解和搜索的代码。因此,在其中,我们可以使用此扩展程序仅在前端选择标签。
