本文讨论了群集的介绍,建议您首先了解群集。
聚类算法有多种类型。以下概述仅列出了最重要的聚类算法示例,因为可能有超过100种已发布的聚类算法。并非所有人都为其集群提供模型,因此不容易对其进行分类。
基于分布的方法
这是一个聚类模型,在该模型中,我们将根据数据可能属于同一分布的概率来拟合数据。完成的分组可以是正常的或高斯的。高斯分布更为突出,因为我们有固定数量的分布,并且所有即将来临的数据都拟合进来,使得数据的分布可以最大化。这导致了分组,如图所示: 
该模型适用于综合数据和大小各异的集群。但是,如果不使用约束条件来限制模型的复杂性,则该模型可能会出现问题。此外,基于分布的聚类产生的聚类假设数据基础明确定义的数学模型,对于某些数据分布而言,这是一个很强的假设。
对于使用多元正态分布的Ex -Expectation-maximization算法,该算法是最受欢迎的示例之一。
基于质心的方法
这基本上是一种迭代聚类算法,其中,聚类是由数据点与聚类的质心之间的接近度形成的。在此,形成簇中心即质心,使得数据点的距离与中心最小。该问题基本上是NP-Hard问题之一,因此,在许多试验中,解决方案通常都是近似的。
对于Ex- K-均值算法是该算法的流行示例之一。 
这种算法的最大问题是我们需要预先指定K。在基于密度的分布聚类中也存在问题。
基于连接的方法
基于连接的模型的核心思想类似于基于质心的模型,该模型基本上是基于数据点的紧密度来定义聚类的。更远。
它不是数据集的单个分区,而是提供了以一定距离彼此合并的广泛的群集层次结构。在此,距离函数的选择是主观的。这些模型很容易解释,但缺乏可伸缩性。
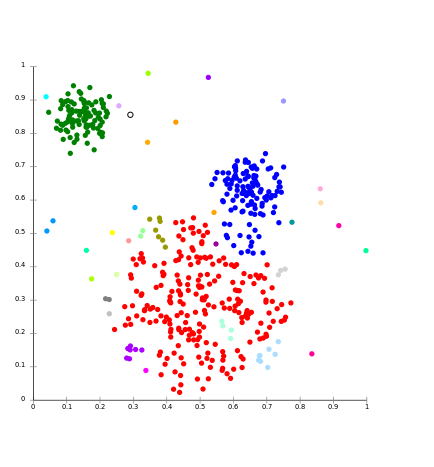
对于Ex-等级算法及其变体。
密度模型
在此聚类模型中,将在数据空间中搜索数据空间中数据点密度不同的区域。它根据数据空间中存在的不同密度来隔离各种密度区域。
对于Ex- DBSCAN和OPTICS 。 
子空间聚类
子空间聚类是一个无监督的学习问题,旨在将数据点分组为多个聚类,以便单个聚类上的数据点大致位于低维线性子空间上。子空间聚类是特征选择的扩展,就像特征选择一样,子空间聚类需要搜索方法和评估标准,但此外,子空间聚类限制了评估标准的范围。子空间聚类算法将对相关维的搜索本地化,并允许他们找到存在于多个重叠子空间中的聚类。子空间聚类最初旨在解决非常具体的计算机视觉问题,在数据中具有子空间结构的并集,但它在统计和机器学习社区中越来越受到关注。人们在社交网络,电影推荐和生物数据集中使用此工具。子空间群集引起了对数据隐私的关注,因为许多此类应用程序涉及处理敏感信息。假定数据点是不连续的,它仅保护用户任何功能的差异隐私,而不是保护数据库的整个配置文件用户。
根据子空间聚类的搜索策略,有两个分支。
- 自上而下的算法在整个维度集中找到一个初始聚类,并评估每个聚类的子空间。
- 自下而上的方法在低维空间中找到密集区域,然后合并形成簇。
参考 :
analyticsvidhya
知识
改良者: Pragya vidyarthi