- Python |多项式回归的实现(1)
- 多项式回归实现python(1)
- Python |多项式回归的实现
- 多项式回归实现python代码示例
- 岭回归实现python(1)
- R 编程中的多项式回归(1)
- R 编程中的多项式回归
- 岭回归实现python代码示例
- Julia 中的多项式回归
- Julia 中的多项式回归(1)
- 多项式回归(使用Python从头开始)(1)
- 多项式回归(使用Python从头开始)
- python中的多项式(1)
- 机器学习-多项式回归(1)
- 机器学习-多项式回归
- 线性回归(Python实现)
- 线性回归(Python实现)
- 线性回归(Python实现)(1)
- python代码示例中的多项式
- 回归python(1)
- 多项式回归 scikit learn - Python (1)
- 多项式回归 scikit learn - Python 代码示例
- 使用 scikit-learn 库的多项式回归 - Python (1)
- 回归python代码示例
- 使用 scikit-learn 库的多项式回归 - Python 代码示例
- 使用 Turicreate 进行多项式回归(1)
- 使用 Turicreate 进行多项式回归
- 在 Python 代码中计算多项式的值 - Python (1)
- 了解逻辑回归 Python实现
📅 最后修改于: 2020-04-23 05:10:59 🧑 作者: Mango
多项式回归是线性回归的一种形式,其中将自变量x和因变量y之间的关系建模为n次多项式。多项式回归拟合x的值与y的相应条件均值之间的非线性关系,表示为E(y | x)
为什么多项式回归:
- 研究人员将假设某些关系是曲线关系。显然,此类情况将包含多项式项。
- 通常的多元线性回归分析中的一个假设是所有自变量都是独立的。在多项式回归模型中,不满足该假设。
多项式回归的用途:
这些基本上用于定义或描述非线性现象,例如:
- 组织的生长速度。
- 疾病流行病的进展
- 湖泊沉积物中碳同位素的分布
回归分析的基本目标是根据自变量x的值对因变量y的期望值进行建模。在简单回归中,我们使用以下方程式:
y = a + bx + e
此处y是因变量,a是y截距,b是斜率,e是错误率。
在许多情况下,这种线性模型无法解决问题。例如,如果我们根据发生这种情况的温度来分析化学合成的产物,则使用二次模型
y = a + b1x + b2 ^ 2 + e
此处y是x的因变量,a是y截距,e是错误率。
通常,我们可以为第n个值建模。
y = a + b1x + b2x ^ 2 + …. + bnx ^ n
由于回归函数在未知变量方面是线性的,因此这些模型从估计的角度来看是线性的。
因此,通过最小二乘技术,让我们计算响应值y。
Python中的多项式回归:
要获得用于分析多项式回归的数据集,请单击此处。
步骤1:导入库和数据集
导入用于执行多项式回归的重要库和数据集。
# 导入库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 导入数据集
datas = pd.read_csv('data.csv')
datas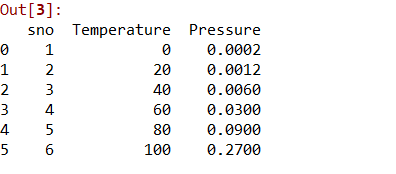
步骤2:将资料集分为2个部分
将数据集分为两个部分,即X和y. X将包含1到2之间的列。y将包含2列。
X = datas.iloc[:, 1:2].values
y = datas.iloc[:, 2].values步骤3:将线性回归拟合到数据集
在两个组件上拟合线性回归模型。
# 将线性回归拟合到数据集
from sklearn.linear_model import LinearRegression
lin = LinearRegression()
lin.fit(X, y)步骤4:将多项式回归拟合到数据集
在两个分量X和y上拟合多项式回归模型。
# 将多项式回归拟合到数据集
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree = 4)
X_poly = poly.fit_transform(X)
poly.fit(X_poly, y)
lin2 = LinearRegression()
lin2.fit(X_poly, y)步骤5:在这一步中,我们使用散点图可视化线性回归结果。
# 可视化线性回归结果
plt.scatter(X, y, color = 'blue')
plt.plot(X, lin.predict(X), color = 'red')
plt.title('Linear Regression')
plt.xlabel('Temperature')
plt.ylabel('Pressure')
plt.show()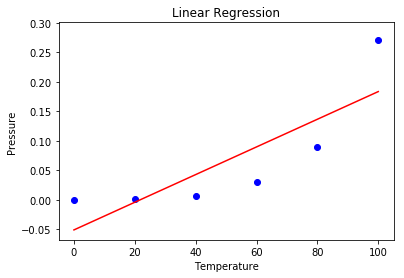
步骤6:使用散点图可视化多项式回归结果。
# 可视化多项式回归结果
plt.scatter(X, y, color = 'blue')
plt.plot(X, lin2.predict(poly.fit_transform(X)), color = 'red')
plt.title('Polynomial Regression')
plt.xlabel('Temperature')
plt.ylabel('Pressure')
plt.show()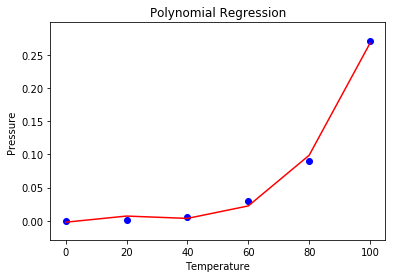
步骤7:使用线性和多项式回归预测新结果。
# 用线性回归预测新结果
lin.predict(110.0)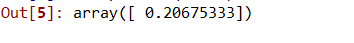
# 用多项式回归预测新结果
lin2.predict(poly.fit_transform(110.0))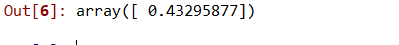
使用多项式回归的优势:
- 它的功能范围很广。
- 多项式基本上适合广泛的曲率范围。
- 多项式提供了因变量和自变量之间关系的最佳近似值。
使用多项式回归的缺点:
- 这些对异常值过于敏感。
- 数据中存在一两个异常值会严重影响非线性分析的结果。
- 另外,不幸的是,与线性回归相比,用于非线性回归中离群值检测的模型验证工具要少。