深度人脸识别
DeepFace 是 Facebook 用于标记图像的面部识别系统。它是由Facebook AI Research (FAIR)的研究人员在2014 年 IEEE 计算机视觉和模式识别会议 (CVPR) 上提出的。
在现代人脸识别中有4个步骤:
- 探测
- 对齐
- 代表
- 分类
这种方法侧重于面部图像的对齐和表示。我们将详细讨论这两部分。
结盟:
这个对齐部分的目标是从输入图像生成正面人脸,其中可能包含来自不同姿势和角度的人脸。本文提出的方法使用基于基准(人脸特征点)的人脸3D正面化来提取正面人脸。整个对齐过程分以下步骤完成:
- 给定输入图像,我们首先使用六个基准点识别人脸。这六个基准点是 2 个眼睛、鼻尖和嘴唇上的 3 个点。这些特征点用于检测图像中的人脸。

6个基准点
- 在这一步中,我们使用 6 个基准点从原始图像中裁剪出2D 人脸图像。

2D 裁剪的脸
- 在第三步中,我们在二维对齐的裁剪图像上应用67 个基准点图及其对应的德洛尼三角剖分。完成此步骤是为了对齐平面外旋转。在这一步中,我们还使用通用 2D 到 3D 模型生成器生成 3D 模型,并在其上手动绘制 67 个基准点。

Delaunay 三角剖分的 67 个基准点

从对齐 2D 裁剪图像生成的 3D 形状
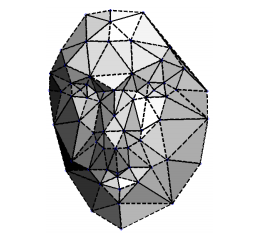
3D 中 2D 形状的可见性图(与升降三角形相比,较暗的三角形不太明显)
- 然后我们尝试使用给定的关系建立2D 和 3D 之间的关系
这里为了改进这个转换,我们需要最小化损失
 可以通过以下关系计算:
可以通过以下关系计算: 
在哪里,
和∑
*** QuickLaTeX cannot compile formula: *** Error message: Error: Nothing to show, formula is empty是协方差矩阵,维度为(67 x 2) x (67 x 2) ,X 3d
*** QuickLaTeX cannot compile formula: *** Error message: Error: Nothing to show, formula is empty是(67 x 2) x 8和
*** QuickLaTeX cannot compile formula: *** Error message: Error: Nothing to show, formula is empty[Tex]\overrightarrow{P} [/Tex] 的尺寸为(2 x 4) 。我们正在使用Cholesky 分解将该损失函数转换为普通最小二乘法。
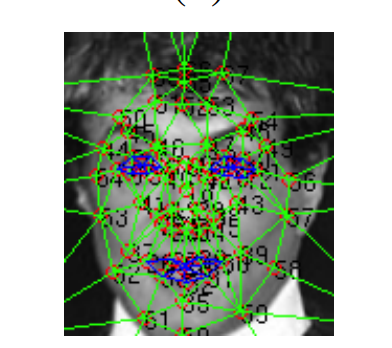
2D-3D 仿射面上的 67 个基准点映射。
- 最后阶段是对齐的正面化。但是在实现正面化之前,我们将残差分量添加到 3D 扭曲的 xy 坐标,因为它减少了 3D 扭曲中的损坏。最后,通过对我们在 67 个基准点上生成的德洛尼三角剖分进行分段仿射来实现正面化。

最后正面化
表示和分类架构:
DeepFace 被训练用于多类人脸识别,即根据他们的身份对多人的图像进行分类。
它将输入输入为152*152的 3D 对齐 RGB 图像。然后该图像通过具有32 个过滤器和大小为11*11*3的卷积层和一个3*3 的最大池化层,步长为2 。接下来是另一个包含16 个过滤器和大小为9*9*16 的卷积层。这些层的目的是从图像边缘和纹理中提取低级特征。
接下来的三层是局部连接层,一种全连接层,在不同的特征图中具有不同类型的过滤器。这有助于改进模型,因为人脸的不同区域具有不同的辨别能力,因此最好使用不同类型的特征图来区分这些面部区域。

DeepFace 全架构
模型的最后两层是全连接层。这些层有助于建立面部两个远处部分之间的相关性。示例:眼睛的位置和形状以及嘴巴的位置和形状。倒数第二个全连接层的输出用作人脸表示,最后一层的输出是用于人脸分类的 softmax 层K类。
该网络中的参数总数约为1.2 亿,其中大部分(~95%)来自最终的全连接层。这个网络的有趣特性是在这个模型的训练过程中生成的特征图/向量非常稀疏。例如,最顶层75%的值是 0。这可能是因为该网络在每个卷积网络中都使用了 ReLU 激活函数,它本质上是max(0, x) 。该网络还使用了Drop-out 正则化,这也导致了稀疏性。但是,Dropout 仅适用于第一个全连接层。
在该网络的最后阶段,我们还将特征归一化为 0 和 1 之间。这也减少了光照变化的影响。在此归一化之后,我们还执行L2 正则化。
验证指标:
我们需要定义一些度量来衡量两个输入图像是否属于同一类。有两种方法:监督和无监督,监督比无监督具有更好的准确性。这是直观的,因为在特定目标数据集上进行训练时,可以通过根据它微调模型来提高准确性。例如,野外标记人脸(LFW)数据集有75%的人脸是男性,LFW 的训练可能会引入一些偏差并添加一些泛化,这在其他人脸识别数据集上进行测试时不适合。但是,在其他数据集上使用时,使用小数据集进行训练可能会降低泛化能力。在这些情况下,无监督的相似性度量更好。本文使用表示架构生成的两个特征向量的内积来实现无监督相似度。本文还使用了两个监督验证指标。这些是
- 加权
*** QuickLaTeX cannot compile formula: *** Error message: Error: Nothing to show, formula is empty[Tex]\chi ^{2} [/Tex]距离:
加权 相似度定义为:
相似度定义为: ![\chi^{2}_{f_1, f_2} = \sum _{i}\omega_{i} \dfrac{\left ( f_1\left [ i \right ] - f_2\left [ i \right ]\right )^2}{f_1\left [ i \right ] + f_2\left [ i \right ]}](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/Deep_Face_Recognition_13.jpg "由 QuickLaTeX.com 渲染")
在哪里
是人脸表示向量和
 是我们可以使用线性 SVM 学习的权重。
是我们可以使用线性 SVM 学习的权重。 - 连体网:
Siamese 网络是一种非常常见的方法,用于预测两张人脸是否属于同一类。如果距离在容差范围内,它会计算两个人脸表示之间的连体距离,如果距离在容差范围内,那么它预测两个人脸属于同一类,否则不属于同一类。连体距离定义为![d_{\left ( f_1, f_2 \right )} = \sum_{i}\alpha_i\left | f_1\left [ i \right ] - f_2\left [ i \right ] \right |](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/Deep_Face_Recognition_16.jpg "由 QuickLaTeX.com 渲染")
培训和结果
DeepFace 在以下三个数据集上进行了训练和实验
- 证监会数据集:
这是 Facebook 自己生成的数据集。它包含近440 万张图像,包含4030 个人,每个人有800 到 1200 张人脸图像。出于测试目的,他们从每个类中获取5% 的最新图像。该模型使用标准前馈网络进行训练,SGD动量 = 0.9 ,批量大小 = 128 ,所有层的学习率相同,即0.01 。
该模型在数据集1.5k 人(1.5M 图像) 、 3k 人(3.3M 图像)和4k 人(4.4M 图像)的三个子集上进行训练。这些子集的分类错误率分别为7% 、 7.2%和8.7% 。 - LFW 数据集:
它是人脸识别领域最流行的数据集之一。它包含5700多位名人的13000 多张网络图片。使用三种方法测量性能:- 提供给模型的一对图像和目标是识别图像是否相同的受限方法。
- 不受限制的方法,其中可以训练的图像多于一对。
- 模型未在 LFW 数据集上训练的无监督方法。
结果如下:
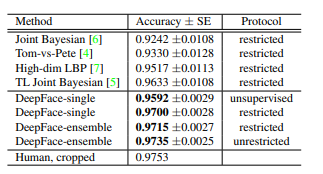
这里,DeepFace-ensamble 代表使用我们上面讨论的不同验证指标的不同 DeepFace-single 模型的组合。
我们可以得出结论,DeepFace-ensemble 达到了97.35% 的最大准确率,非常接近人类水平的 97.53%
- YTF数据集:
它包含1595 位名人(来自 LFW 的名人子集)的3425 个视频。这些视频分为10 个分割的5000 个视频对,用于评估视频级人脸验证的性能。 YTF数据集上的结果如下:
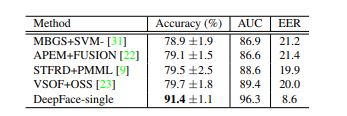
YTF的结果
请注意,由于运动模糊等因素,视频数据集的图像质量通常比图像数据集差。但是, 91.4%仍然是当时最先进的准确率,并且将错误率降低了50% 以上。
在测试时间方面,DeepFace在单核2.2GHz Intel 处理器上测试耗时0.33 秒。这包括0.05 秒对齐和0.18 秒特征提取。
结论:
在发布时,它是目前最好的人脸识别模型之一,当然还有 Google-FaceNet 等模型,在 LFW 数据集上的准确率高达99.6% 。 DeepFace 能够解决的主要问题是建立一个对光效、姿势、面部表情等保持不变的模型,这就是为什么它被用于 Facebook 的大部分人脸识别任务。使用 3D 对齐的新方法也有助于提高模型的准确性。
参考:
- 深面纸