📌 相关文章
- 用于模式搜索的Boyer Moore算法
- 用于模式搜索的Boyer Moore算法(1)
- Boyer-Moore 多数投票算法
- Boyer-Moore 多数投票算法
- Boyer-Moore 多数投票算法(1)
- Boyer-Moore 多数投票算法(1)
- Boyer Moore算法|良好的后缀启发式
- Boyer Moore算法|良好的后缀启发式(1)
- DAA算法(1)
- DAA算法
- DAA-算法分析(1)
- DAA-算法分析
- 算法的DAA复杂度
- DAA算法需求
- DAA算法需求(1)
- DAA算法设计技术(1)
- DAA算法设计技术
- DAA主方法
- DAA |约翰逊算法(1)
- DAA |约翰逊算法
- DAA桶排序(1)
- DAA桶排序
- DAA-爬山算法(1)
- DAA-爬山算法
- DAA |流网络和流(1)
- DAA |流网络和流
- DAA分析算法控制结构
- DAA分析算法控制结构(1)
- DAA-生成树(1)
📜 DAA Boyer-Moore算法
📅 最后修改于: 2020-12-11 01:45:39 🧑 作者: Mango
Boyer-Moore算法
Robert Boyer和J Strother Moore于1977年成立了它。BM字符串搜索算法是一种特别有效的算法,自那时以来一直作为字符串搜索算法的标准基准。
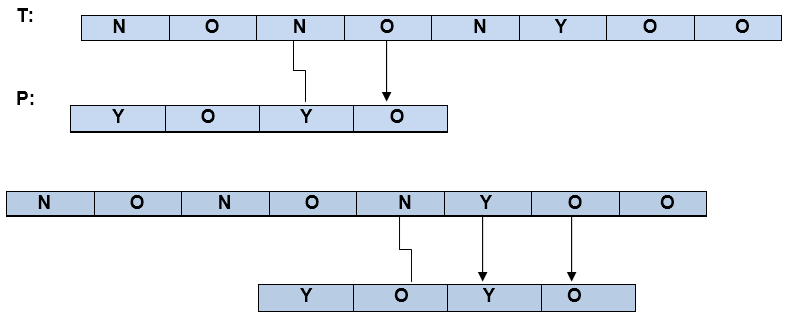
的BM算法需要一个“落后”的方法:模式字符串(P)与所述文本字符串的开始(T)对准,并且然后比较的图案的字符从右到左,以最右边的字符开始。
如果比较的字符不在模式中,则无法通过分析此位置上的任何其他方面找到匹配项,因此可以完全在不匹配字符更改模式。
为了确定可能的偏移,BM算法同时使用了两种预处理策略。每当发生不匹配时,如果每种情况都使用最有效的策略,则该算法会使用两种方法来计算偏差并选择更为显着的偏移。
这两种策略被称为B-M的启发式算法,因为它们用于减少搜索。他们是:
- 错误字符启发法
- 良好的后缀启发式
1.坏字符启发法
这种启发式方法有两个含义:
- 假设文本中根本没有字符出现在模式中。当此字符发生不匹配(称为坏字符)时,可以更改整个模式,开始匹配此“坏字符”旁边的表单子字符串。
- 另一方面,可能是模式中存在不良字符,在这种情况下,请将模式的性质与文本中的不良字符对齐。
因此,在任何情况下,偏移都可能大于一个。
示例1:让文本T =

示例2:如果不存在错误字符,则使用该模式。
坏字符启发法中的问题:
在某些情况下,坏字符启发法会产生一些负面变化。
例如:
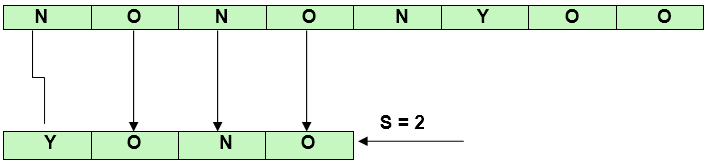
这意味着我们需要一些额外的信息,以便在遇到坏字符有所转变。该信息与模式中各个方面的最后位置有关,也与模式中使用的字符集(通常称为模式的字母∑)有关。
2.良好的后缀启发法:
良好的后缀是已成功匹配的后缀。在不匹配之后,不良字符启发法会发生负向偏移,请查看是否匹配的模式子串直到不良字符具有良好的后缀为止,如果是这样,则我们向前跳的次数等于找到的后缀的长度。
例:

字符串匹配算法的复杂度比较:
| Algorithm | Preprocessing Time | Matching Time |
|---|---|---|
| Naive | O | (O (n – m + 1)m) |
| Rabin-Karp | O(m) | (O (n – m + 1)m) |
| Finite Automata | O(m|∑|) | O (n) |
| Knuth-Morris-Pratt | O(m) | O (n) |
| Boyer-Moore | O(|∑|) | (O ((n – m + 1) + |∑|)) |