FaceNet – 使用面部识别系统
FaceNet 是谷歌研究人员在 2015 年在题为FaceNet: A Unified Embedding for Face Recognition and Clustering的论文中提出的面部识别系统的名称。它在许多基准人脸识别数据集中取得了最先进的结果,例如野外标记人脸 (LFW) 和 Youtube 人脸数据库。
他们提出了一种方法,该方法使用 ZF-Net 和 Inception 等深度学习架构从图像中生成高质量的人脸映射。然后它使用一种称为triplet loss的方法作为损失函数来训练这个架构。让我们更详细地看一下架构。
建筑学:

FaceNet 架构
FaceNet 在其架构中采用端到端学习。它使用 ZF-Net 或 Inception 作为其底层架构。它还增加了几个1*1的卷积来减少参数的数量。这些深度学习模型输出图像f(x)的嵌入,并对其执行L 2归一化。然后将这些嵌入传递到损失函数中以计算损失。该损失函数的目标是使两个图像嵌入之间的平方距离与图像条件无关,并且相同身份的姿态很小,而两个不同身份的图像之间的平方距离很大。因此使用了一种称为Triplet loss的新损失函数。在我们的架构中使用三元组损失的想法是,它使模型在不同身份的人脸之间强制执行一个边距。
三重损失:
图像的嵌入由f(x)表示,例如x  .这个嵌入是大小为128的向量的形式,并且它被归一化,使得
.这个嵌入是大小为128的向量的形式,并且它被归一化,使得

我们要确保锚图像(
*** QuickLaTeX cannot compile formula:
*** Error message:
Error: Nothing to show, formula is empty
)的人更接近正面形象(
*** QuickLaTeX cannot compile formula:
*** Error message:
Error: Nothing to show, formula is empty
) (同一个人的图像)与负面图像(
*** QuickLaTeX cannot compile formula:
*** Error message:
Error: Nothing to show, formula is empty
) (另一个人的图像)这样:


在哪里 是强制区分正负对的边距,并且
是强制区分正负对的边距,并且 是图像空间。
是图像空间。
因此损失函数定义如下:
![L = \sum_{i}^{N}\left [ \left \| f\left ( x_i^a \right ) - f\left ( x_i^p \right ) \right \|_{2}^{2} - \left \| f\left ( x_i^a \right ) - f\left ( x_i^n \right ) \right \|_{2}^{2} +\alpha \right ]](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/FaceNet_%E2%80%93_Using_Facial_Recognition_System_7.png "由 QuickLaTeX.com 渲染")
如果三元组很容易满足以上属性,那么它对训练没有帮助,所以有违反上述方程的三元组是很重要的。
三胞胎选择:
为了确保更快的学习,我们需要采用违反上述等式的三元组。这意味着给定 我们需要选择三元组,使得
我们需要选择三元组,使得 是最大值并且
是最大值并且 是最小值。基于整个训练集生成三元组的计算成本很高。有两种生成三元组的方法。
是最小值。基于整个训练集生成三元组的计算成本很高。有两种生成三元组的方法。
- 根据之前的检查点在每一步生成三元组并计算最小值和最大值
在数据子集上。 - 选择硬阳性 (
 ) 和硬否定 (
) 和硬否定 (  ) 通过在小批量上使用最小值和最大值。
) 通过在小批量上使用最小值和最大值。
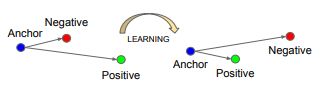
三元组损失和学习
训练 :
该模型使用带有反向传播和 AdaGrad 的随机梯度下降 (SGD) 进行训练。该模型在 CPU 集群上训练1k-2k 小时。在 500 小时的训练后,观察到损失的稳步下降(以及准确性的提高)。该模型使用两个网络进行训练:
- 采埃孚网:
下面的可视化显示了此架构中使用的 ZF-Net 的不同层及其内存要求:
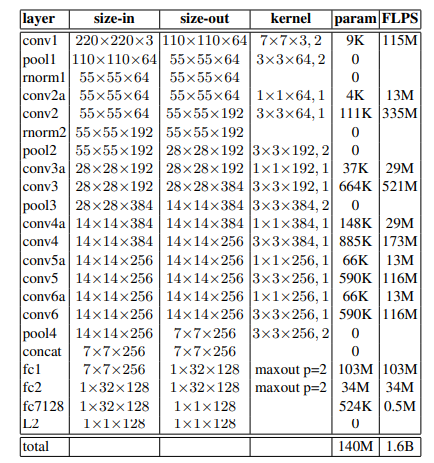
FaceNet 中的 ZF-Net 架构
- 正如我们注意到的那样,该架构中有1.4 亿个参数,并且需要 16 亿个 FLOPS 内存来训练这个模型。
- 开始:
下面的可视化显示了此架构中使用的 Inception 模型的不同层及其内存要求:
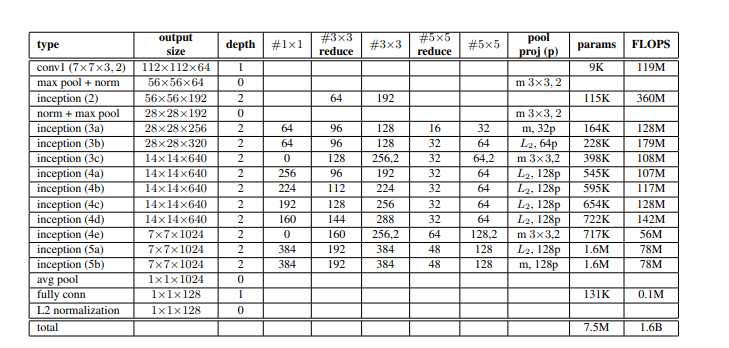
FaceNet 中使用的初始架构
- 我们注意到架构中只有750 万个参数,但需要 16 亿次 FLOPS 内存来训练这个模型(类似于 ZF-Net)。
结果:
该模型在野外的 Labeled Faces 和 Youtube Face DB 数据集上使用了 4 种不同类型的架构。
- Wild 数据集中的标记人脸:
该架构在 LFW 数据集上使用标准的、无限制的协议。首先,该模型使用 9 次训练分割来设置L 2距离阈值,然后在第 10 次分割时,它将两个图像分类为相同或不同。
报告准确性的图像和数据集有两种预处理方法:- 修复了 LFW 中提供的图像的中心裁剪
- 如果失败,则在 LFW 图像上使用人脸检测器,然后使用 LFW 人脸对齐
该模型实现了98.87%的分类准确度和 0.15% 的标准误差,在第二种情况下达到99.63%的准确度和0.09%的标准误差。这将DeepFace报告的错误率降低了7倍以上,将其他最先进的 DeepId 报告的错误率降低了30% 。
- Youtube 人脸数据库:
在 Youtube Face Dataset 上,它使用前 100 帧报告了95.12%的准确度,标准误差为 0.39 。它优于 DeepFace 提出的91.4%准确率和 DeepId 在 100 帧上报告的93.5%

使用 FaceNet 进行人脸聚类
来自 FaceNet 论文的人脸聚类(同一个人的图像聚类)的结果表明,该模型对遮挡、姿势、光照甚至年龄等都是不变的。
参考:
- FaceNet 论文