RNN及其变体的数学理解
介绍:
专家期望人工智能 (AI) 致力于创造更美好的生活。他们表示,随着未来将有更多的计算能力可用,即更多的图形处理单元,人工智能将为人类带来更多进步和生产力。今天,人们可以看到很多这样的人工智能应用,比如打击人口贩卖、医疗顾问、自动驾驶汽车、入侵检测和预防、对象跟踪和计数、人脸检测和识别、疾病预测和人类虚拟援助。帮助。这篇特别的文章讨论了 RNN、它的变体(LSTM、GRU)和它背后的数学。 RNN 是一种接受可变长度输入并产生可变长度输出的神经网络。它用于开发各种应用程序,例如文本转语音、聊天机器人、语言建模、情感分析、时间序列股票预测、机器翻译和 nam 实体识别。
表中的内容:
- 什么是 RNN,它与前馈神经网络有何不同
- RNN 背后的数学
- RNN 变体(LSTM 和 GRU)
- RNN 的实际应用
- 最后说明
什么是 RNN 以及它与前馈神经网络有何不同:
RNN 是一种循环神经网络,其当前输出不仅取决于其当前值还取决于过去的输入,而对于前馈网络,当前输出仅取决于当前输入。看看下面的例子,以更好的方式理解 RNN。
Rahul belongs to congress.
Rahul is part of indian cricket team.
如果有人问到 Rahul 是谁,他/她会说 Rahul 是不同的,即一个来自印度国民大会,另一个来自印度板球队。现在,如果将相同的任务交给机器以给出输出,它在知道完整上下文之前无法说出,即预测单个单词的身份取决于了解整个上下文。此类任务可以通过作为 RNN 变体的 Bi-LSTM 来实现。由于 RNN 具有学习上下文的能力,因此它们适用于此类工作。其他应用包括语音到文本的转换、构建虚拟辅助、时间序列股票预测、情感分析、语言建模和机器翻译。另一方面,前馈神经网络产生的输出仅取决于当前输入。此类示例包括图像分类任务、图像分割或对象检测任务。一种此类网络是卷积神经网络 (CNN)。请记住,RNN 和 CNN 都是有监督的深度学习模型,即它们在训练阶段需要标签。
RNN 背后的数学
1.) RNN的数学方程
要了解 RNN 背后的数学原理,请看下图
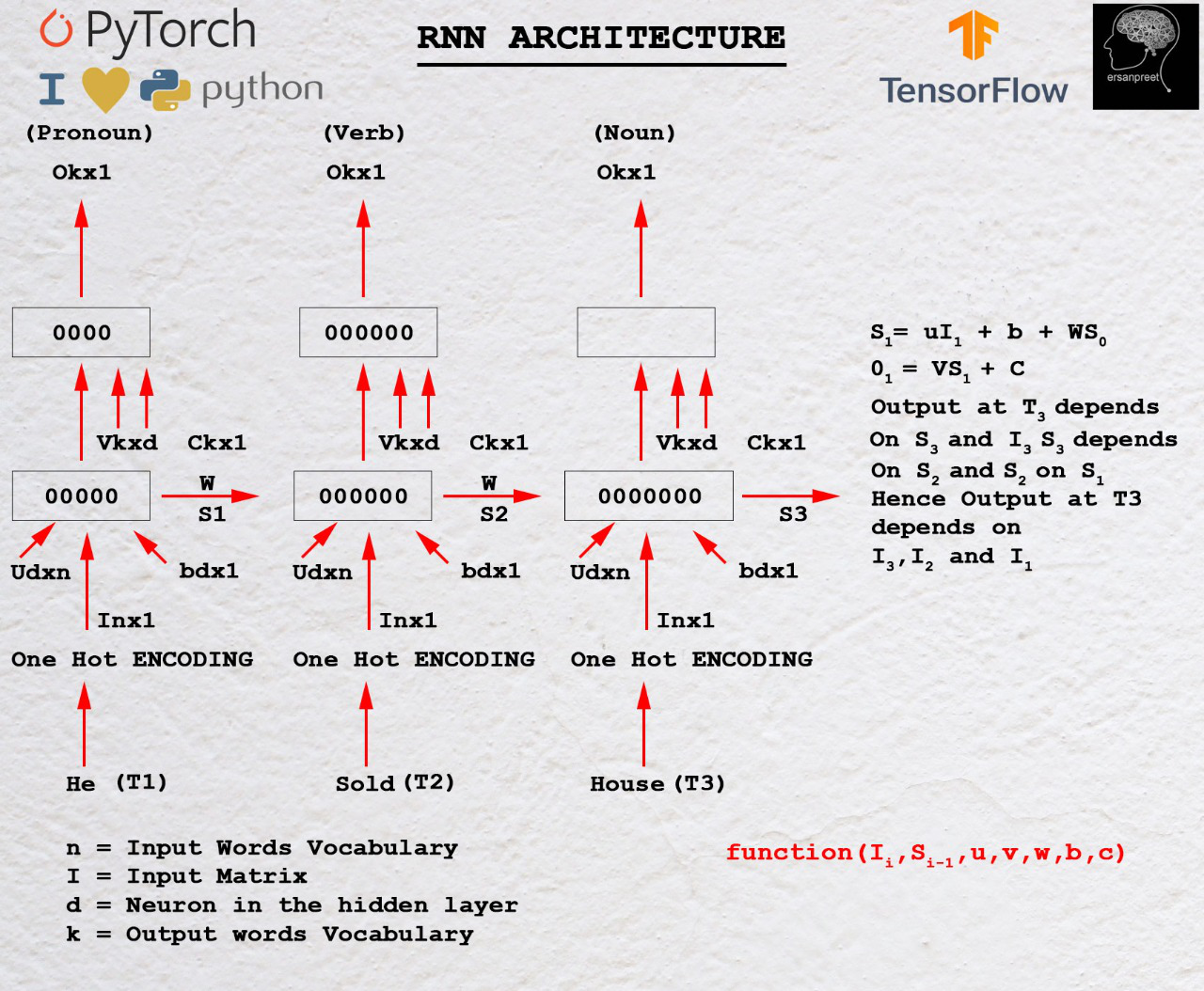
RNN 背后的数学
正如第一个标题中所讨论的,输出取决于当前和过去的输入。让I 1是第一个输入,其维度为n*1 ,其中 n 是词汇表的长度。 S 0是具有 d 个神经元的第一个 RNN 单元的隐藏状态。对于每个单元格,输入隐藏状态应该是前一个。对于第一个单元格,用零或某个随机数初始化S 0 ,因为没有看到以前的状态。 U是另一个维度为d*n的矩阵,其中d是第一个 RNN 单元中的神经元数量, n是输入词汇表的大小。 W是另一个矩阵,其维度为d*d 。 b是偏差,其维度为d*1 。为了找到第一个单元格的输出,采用另一个矩阵V ,其维度为k*d ,其中c是维度为k*1的偏差。
在数学上,第一个 RNN 单元的输出如下
S1= UI1+ WS0 + b
O1= VS1+c一般来说,
Sn= UIn+ WSn-1 + b
On= VSn+c上述等式的关键要点
通常,输出 O n取决于 S n并且 S n取决于 S n-1 。 S n-1取决于 S n-2 。过程一直进行到达到 S 0为止。这清楚地表明第 n个时间步的输出取决于所有先前的输入。
2.) 参数和梯度
RNN 中的参数是U、V、b、c、W在所有 RNN 单元之间共享。共享的原因是创建一个可以在所有时间步骤中应用的通用函数。参数是可学习的,负责训练模型。在每个时间步,都会计算损失并通过梯度下降算法进行反向传播。
2.1)关于V的损失梯度
梯度表示切线的斜率,指向函数增长率最大的方向。我们有兴趣找到损失最小的 V。从损失来看,它意味着成本函数或错误。简单来说,代价函数就是真实值与预测值的差值。移动与 V 的损失梯度方向相反。 V 的数学新值使用以下数学公式获得

其中d(L)/d(V)是从时间步长获得的所有损失的总和。有两种更新权重的方法。一种是计算定义批次的梯度然后更新它(Mini Batch)或计算每个样本并更新(Stochastic)。在计算d(L)/d(V)期间,应用链式法则。查看下图以了解计算和链式法则。
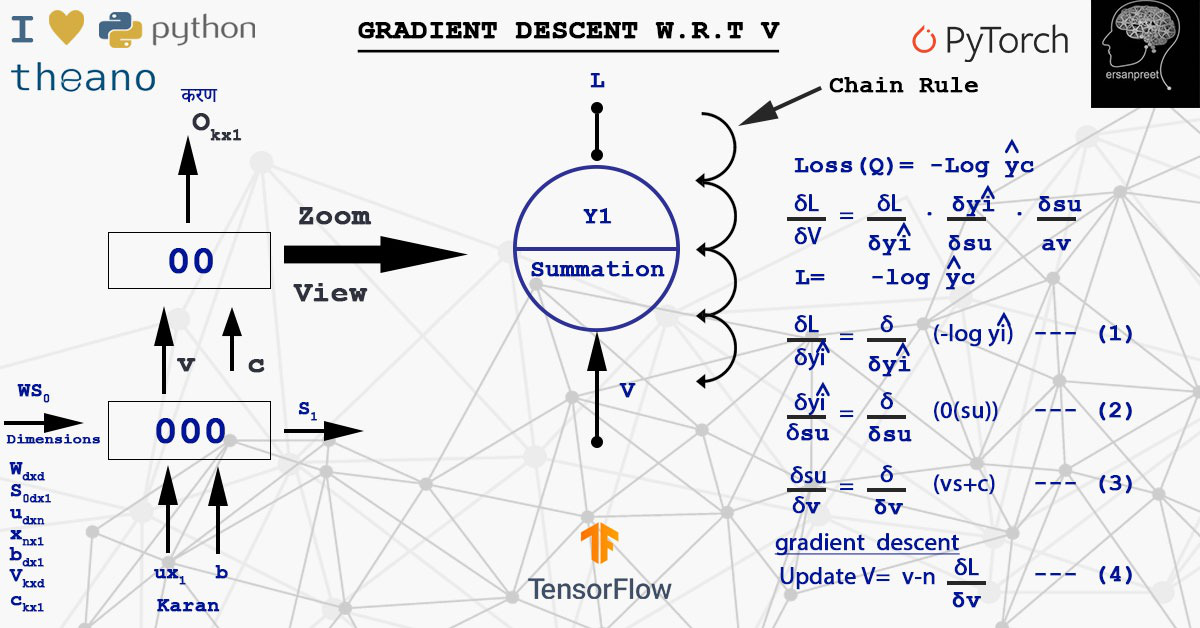
计算损失wrt V梯度的链式规则实现
2.2)关于W的损失梯度
W乘以S。为了在任何时间步计算损失对权重的导数,应用链式法则来考虑从S n到S 0到达 W 的所有路径。这意味着由于任何错误的 S n ,W 都会受到影响。换句话说,一些错误的信息来自于导致损失的隐藏状态。数学上,权重更新如下

要记住的关键点是梯度和权重在每个样本或批次后更新。这取决于算法是选择随机还是小批量。看看下面的截图,以更精致的方式形象化这个概念。
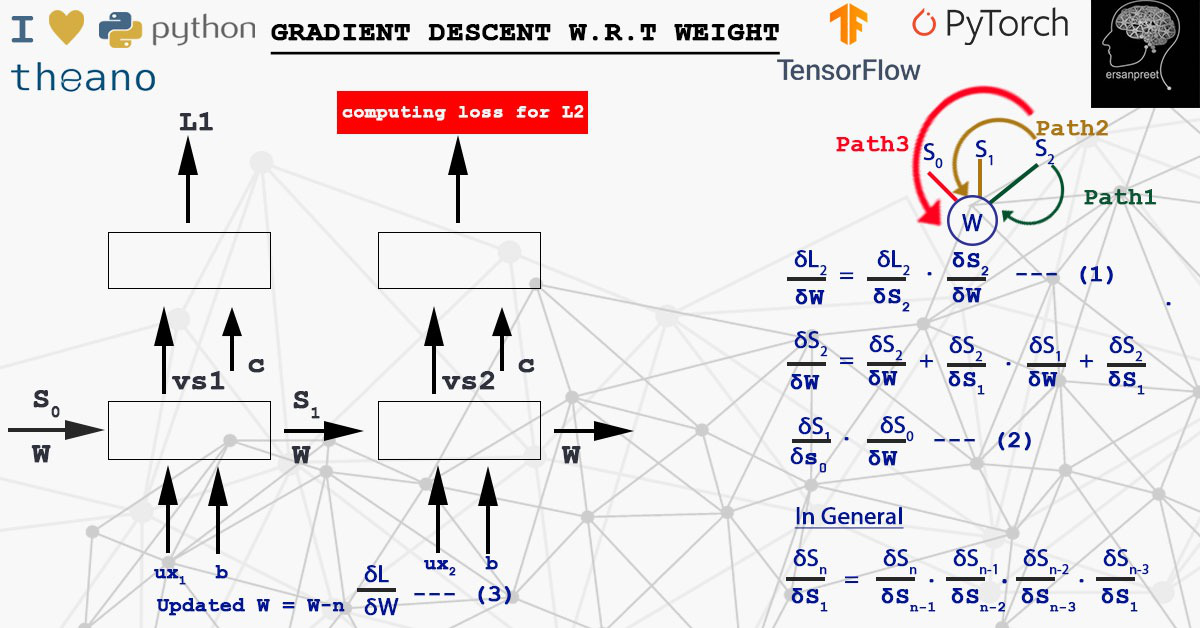
关于 W 的梯度下降
RNN 变体(LSTM 和 GRU)
从上面的讨论中,我希望 RNN 背后的数学现在已经清楚了。 RNN 的主要缺点是无论序列的长度如何,状态向量的维数都保持不变。考虑到一种情况,如果输入序列的长度很长,新的信息就会被添加到同一个状态向量中。当到达距离第一个时间步很远的第 n 个时间步时,信息非常混乱。在这样的位置,时间步骤1或2提供的信息是什么不清楚。它类似于一块尺寸固定的白板,一个人在上面不停地写字。在某些位置,它变得非常混乱。人们甚至无法阅读船上所写的内容。为了解决这些问题,开发了它的变体,即所谓的 LSTM 和 GRU。他们根据选择性读、写和忘记的原则工作。现在白板(类似于状态向量)是相同的,但在时间步只写入所需的信息,过滤掉不必要的信息,使序列神经网络适合长序列的训练。可以从这里了解 LSTM 和 GRU 之间的区别。
LSTM(长短期记忆)
数学表示:
遵循的策略是选择性写入、读取和忘记。
选择性写入
选择性写入:
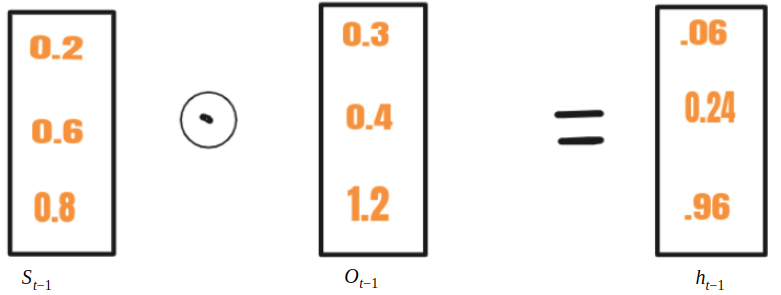
在 RNN 中, S t - 1与x t一起输入 到一个单元格,而在 LSTM S t-1 转化为h t-1 使用另一个向量O t-1 。这个过程称为选择性写入。选择性写入的数学方程式如下

选择性阅读:
看看下面的图片来理解这个概念
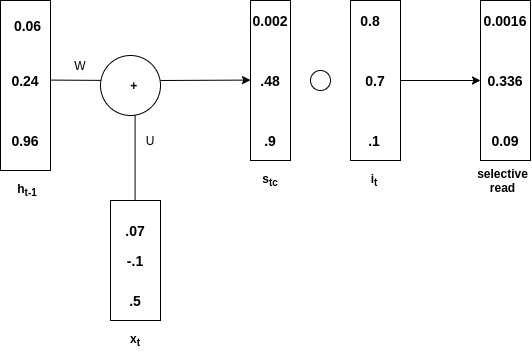
选择性阅读
ht -1 与x t相加产生 s t 。那么哈达玛积 (在图中写为s tc )并获得s t 。这称为输入门。在st只有选择性信息去,这个过程被称为选择性读取。在数学上,选择性读取的方程如下
(在图中写为s tc )并获得s t 。这称为输入门。在st只有选择性信息去,这个过程被称为选择性读取。在数学上,选择性读取的方程如下

选择性遗忘:
看看下面的图片来理解这个概念
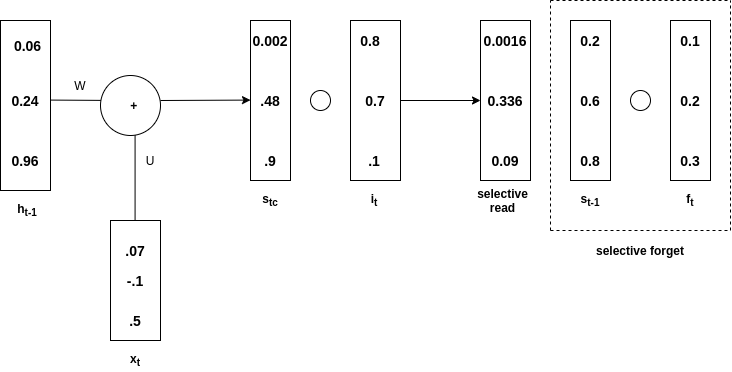
选择性遗忘
t-1 是与 f t的哈达玛积,称为选择性遗忘。总体s t是通过添加选择性读取和选择性遗忘获得的。看下图来理解上面的说法
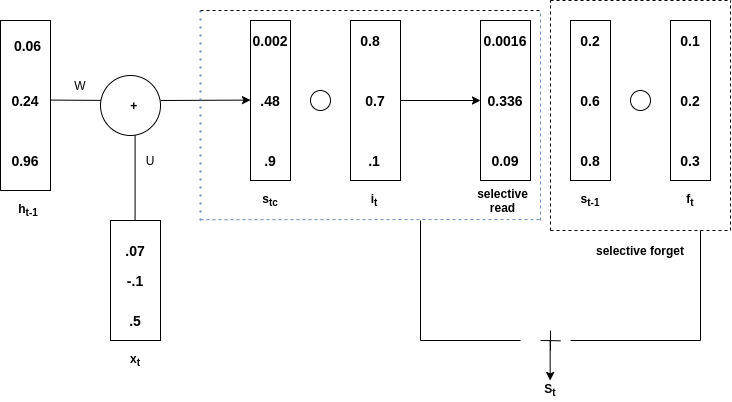
添加选择性阅读和忘记
在数学上,选择性遗忘的方程如下

注意:在 GRU(门控循环单元)的情况下没有遗忘门。它只有输入和输出门。
RNN的实际应用:
RNN 在语音到文本的转换、构建虚拟辅助、情感分析、时间序列股票预测、机器翻译、语言建模中找到了它的用例。更多的研究正在使用 RNN 及其变体创建生成聊天机器人。其他应用程序包括图像字幕、从一个小段落生成大文本和文本摘要器(像 Inshorts 这样的应用程序正在使用它)。音乐创作和呼叫中心分析是使用 RNN 的其他领域。
最后说明:
简而言之,从开头一段,然后深入研究 RNN 背后的数学,就可以理解 RNN 和前馈神经网络之间的区别。最后,通过解释RNN的不同变体和RNN的一些实际应用来完成本文。为了研究 RNN 的应用,人们必须掌握微积分、导数,尤其是链式法则的工作原理方面的丰富知识。一旦研究了理论,就应该用你最喜欢的编码语言编写一些关于这些主题的代码。这将为您提供优势。