- Python中的sort
- Python的sort()
- Python中的sort(1)
- Python的sort()(1)
- 如何在C#中对列表进行排序List.Sort()方法集-1(1)
- 如何在C#中对列表进行排序List.Sort()方法集-2(1)
- 如何在C#中对列表进行排序List.Sort()方法集-2
- 如何在C#中对列表进行排序List.Sort()方法集-1
- c++ sort - C++ (1)
- c++ sort - C++ (1)
- C++中unordered_map中的bucket_count和bucket_size(1)
- C++中unordered_map中的bucket_count和bucket_size
- c++ sort - C++ 代码示例
- c++ sort - C++ 代码示例
- Python列表sort()(1)
- Python列表sort()
- .sort((a, b) - Javascript (1)
- .sort javascript(1)
- javascript sort (1)
- pandas 数据框中的 sort 函数对特定属性进行排序 - Python (1)
- 在 python 中对字符串进行排序(1)
- pandas 数据框中的 sort 函数对特定属性进行排序 - Python 代码示例
- 存储桶排序以对带有负数的数组进行排序(1)
- 存储桶排序以对带有负数的数组进行排序
- Python numpy.sort(1)
- Python中的 numpy.sort()(1)
- Python numpy.sort
- Python中的 numpy.sort()
- 使用Javascript进行存储桶排序可视化
📅 最后修改于: 2020-08-04 04:22:29 🧑 作者: Mango
介绍
在本教程中,我们将深入探讨Python中Bucket Sort的理论和实现。
Bucket Sort是一种比较类型的算法,可将要排序的列表中的元素分配给Buckets或Bins。然后,通常使用另一种算法对这些存储桶中的内容进行排序。排序后,将存储桶中的所有内容,形成一个已排序的集合。
由于元素首先分散在存储桶中,在其中排序,最后收集到新的已排序列表中,因此可以将“存储桶排序”视为对列表进行排序的分散顺序-聚集方法。
我们将在Python中实现存储桶排序,并分析其时间复杂度。
Bucket Sort如何工作?
在深入了解其具体实现之前,让我们逐步介绍该算法的步骤:
- 设置一个空桶列表。为数组中的每个元素初始化一个存储桶。
- 遍历存储桶列表,并从数组中插入元素。每个元素插入的位置取决于输入列表及其最大元素。我们可以
0..n在每个存储桶中添加元素。这将在算法的可视化表示中进行详细说明。 - 对每个非空桶进行排序。您可以使用任何排序算法来执行此操作。由于我们使用的是小型数据集,因此每个存储桶将没有太多元素,因此插入排序在这里为我们带来了奇迹。
- 按顺序访问存储桶。对每个存储桶的内容进行排序后,将它们串联后,将产生一个列表,其中根据您的条件对元素进行了排列。
让我们看一下算法工作原理的直观展示。例如,假设这是输入列表:
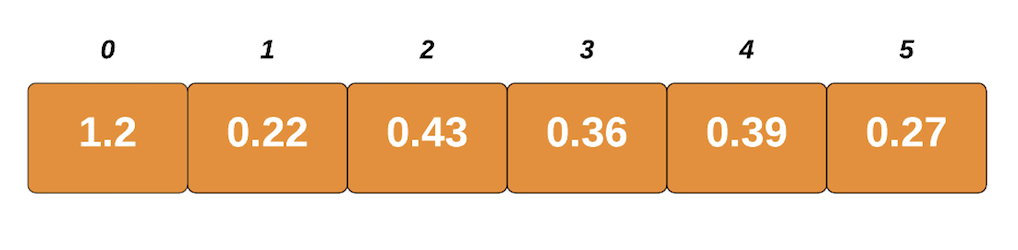
最大的元素是1.2,列表的长度是6。使用这两个,我们将找出size每个存储桶的最佳状态。我们通过将最大元素除以列表的长度来获得此数字。在我们的例子中,1.2/6是0.2。
通过将元素的值除以this size,我们将获得每个元素各自的存储桶的索引。
现在,我们将创建空的存储桶。我们将拥有与列表中的元素相同数量的存储桶:

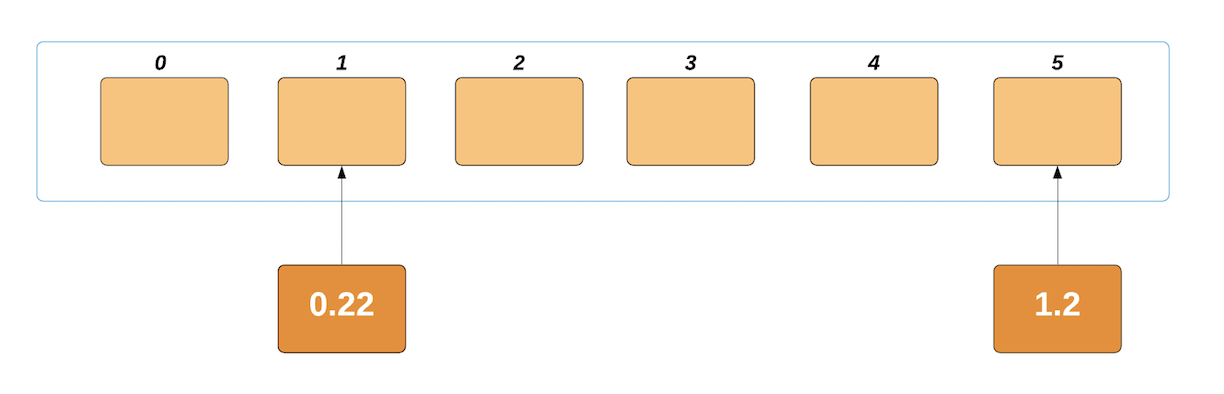
我们将元素插入各自的存储桶中。考虑到第一个元素- 1.2/0.2 = 6,其相应存储区的索引为6。如果此结果大于或等于列表的长度,我们将减去1并很好地适合列表。这仅在最大数时发生,因为我们size通过将最大元素除以长度来获得。
我们将此元素放入索引为的存储桶中5:

同样,下一个元素将被索引到0.22/0.2 = 1.1。由于这是一个十进制数字,因此我们将其作为下限。这四舍五入为1,我们的元素放置在第二个存储桶中:
重复此过程,直到我们将最后一个元素放入其各自的存储桶中为止。现在,我们的存储桶看起来类似于:

现在,我们将对每个非空存储桶的内容进行排序。我们将使用插入排序,因为它在像这样的小列表中保持不变。插入排序后,存储桶如下所示:
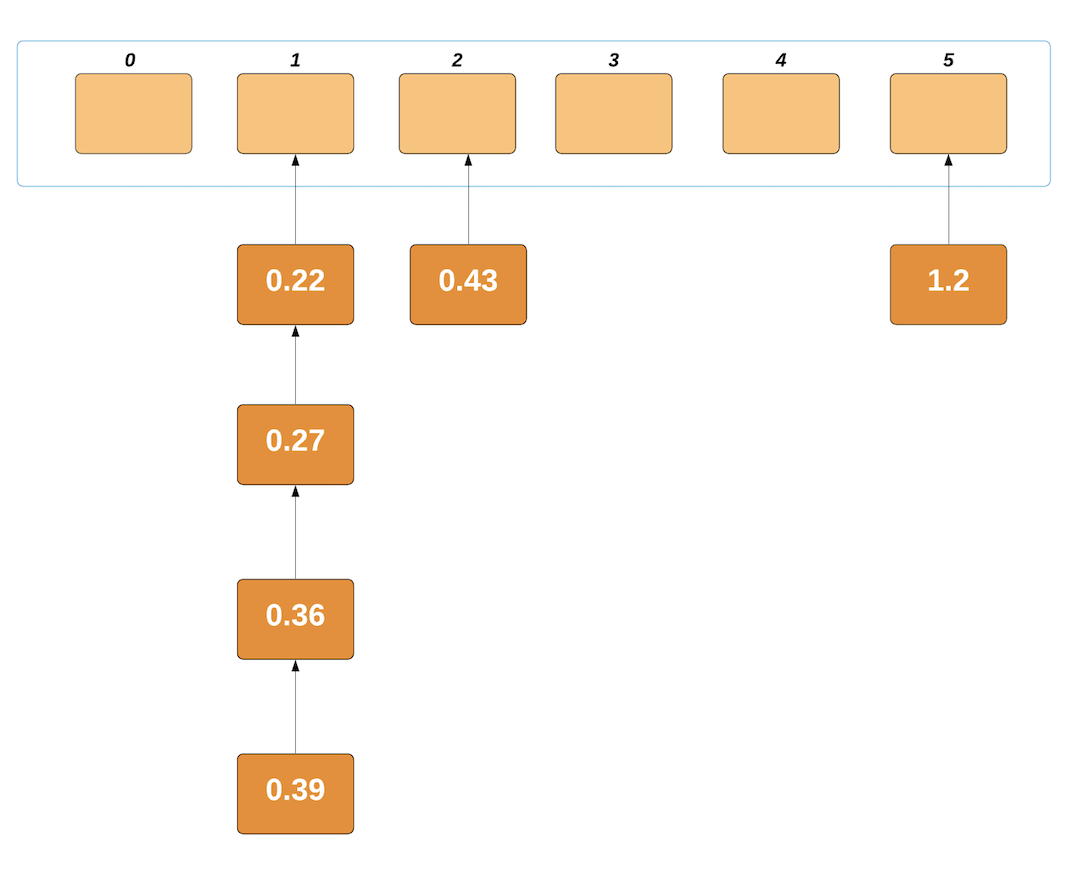
现在,只需遍历非空存储桶并连接列表中的元素即可。他们经过排序,可以开始使用:

Python中的值区排序实作
顺便说一句,让我们继续在Python中实现该算法。让我们从bucket_sort()函数本身开始:
def bucket_sort(input_list):
# Find maximum value in the list and use length of the list to determine which value in the list goes into which bucket
max_value = max(input_list)
size = max_value/len(input_list)
# Create n empty buckets where n is equal to the length of the input list
buckets_list= []
for x in range(len(input_list)):
buckets_list.append([])
# Put list elements into different buckets based on the size
for i in range(len(input_list)):
j = int (input_list[i] / size)
if j != len (input_list):
buckets_list[j].append(input_list[i])
else:
buckets_list[len(input_list) - 1].append(input_list[i])
# Sort elements within the buckets using Insertion Sort
for z in range(len(input_list)):
insertion_sort(buckets_list[z])
# Concatenate buckets with sorted elements into a single list
final_output = []
for x in range(len (input_list)):
final_output = final_output + buckets_list[x]
return final_output实现非常简单。我们已经计算了size参数。然后,我们实例化了一个空桶的列表,并根据它们的值和size每个桶的插入元素。
插入后,我们将调用insertion_sort()每个存储桶:
def insertion_sort(bucket):
for i in range (1, len (bucket)):
var = bucket[i]
j = i - 1
while (j >= 0 and var < bucket[j]):
bucket[j + 1] = bucket[j]
j = j - 1
bucket[j + 1] = var有了这个,让我们填充一个列表并对其执行Bucket Sort:
def main():
input_list = [1.20, 0.22, 0.43, 0.36,0.39,0.27]
print('ORIGINAL LIST:')
print(input_list)
sorted_list = bucket_sort(input_list)
print('SORTED LIST:')
print(sorted_list)运行此代码将返回:
Original list: [1.2, 0.22, 0.43, 0.36, 0.39, 0.27]
Sorted list: [0.22, 0.27, 0.36, 0.39, 0.43, 1.2]桶排序时间复杂度
最坏情况的复杂性
如果我们正在使用的集合的范围很短(例如我们在示例中使用的集合),则通常在一个存储桶中有很多元素,而很多存储桶都是空的。
如果所有元素都属于同一个存储桶,那么复杂度将完全取决于我们用来对存储桶本身的内容进行排序的算法。
由于我们使用的是插入排序-当列表按相反顺序排列时,它的最坏情况下的复杂性就会显现出来。因此,存储桶排序的最坏情况复杂度也是O(n 2)。
最佳情况的复杂性
最好的情况是所有元素都已排序。另外,元素均匀分布。这意味着每个存储桶将具有相同数量的元素。
话虽这么说,创建存储桶将花费O(n),而插入排序将花费O(k),这给我们带来了O(n + k)的复杂度。
平均情况复杂度
平均情况发生在绝大多数现实生活中。当我们要排序的集合是随机的时。在这种情况下,存储桶排序需要O(n)来完成,因此效率很高。
结论
总而言之,我们首先介绍了Bucket的种类,然后讨论了在使用Python实现之前需要了解的内容。实施之后,我们进行了快速的复杂性分析。