Omniglot 分类任务
在深入分类任务之前,让我们先定义 Omniglot 的含义。
Omniglot 数据集:这是一个包含来自 50 个不同字母表的 1623 个字符的数据集,每个字符由一组 20 个不同的人手绘。创建此数据集是为了研究人类和机器如何适应一次性学习,即仅从一个示例中学习一项任务。

来源:https://paperswithcode.com/dataset/omniglot-1
omniglot 数据集的准备方式是,上图中的每个字符都由 20 个不同的人编写。
Omniglot 挑战:向机器学习和人工智能社区发布的Omniglot 挑战集中在 5 个主要任务上:
- 一次性分类
- 解析
- 产生新的范例
- 产生新概念(从类型)
- 产生新概念(无约束)
在本文中,我们将重点关注分类任务。我们将使用一次性分类技术来执行此任务。在进入分类技术之前,让我们了解 One-Shot Learning 背后的直觉。
一次性学习
当人类第一次看到一个物体时,他们能够记住该物体的一些特征。因此,每当他们看到其他同类物体时,他们都能立即识别出来。即使他们只见过那个物体一次,人类也能将它与那个类别联系起来。这被称为一次性学习。让我们举个例子。
假设一个人第一次在电视上看到冰箱并希望购买它。当那个人访问电子产品商店时,他/她能够立即识别出哪些电器是冰箱,哪些不是。人脑的这一原理被称为一次性学习。
根据定义,一次性学习是一种机器用来将新对象分类为不同类别的技术,前提是它在训练期间只从每个类别中看到一个对象。
直觉:
一次性学习使用连体神经网络模型。在这里,模型的目标是找到 2 个图像之间的“相似度” (d) 。我们使用以下公式找到d :

where,
d -> degree of similarity
f(xi) -> 128-D feature vector现在,我们通过 CNN 模型找到每张图像的 128 维特征向量。通过这种方式,我们可以获得特定图像中存在的所有关键特征。 (如图2所示)

图 2:从输入图像中提取 128-D FV
训练阶段:
在 Siamese Network 模型的训练阶段,我们使用了三元组损失函数。在这个过程中,我们采用了两个相似图像(正和锚)和一个来自数据集的不同图像(负)的 128 维特征向量。
我们基于这组 3 张图像训练模型,其中两幅相似图像之间的相似距离非常小。因此,距离越小,两幅图像越相似。 (如图3-步骤7所示)
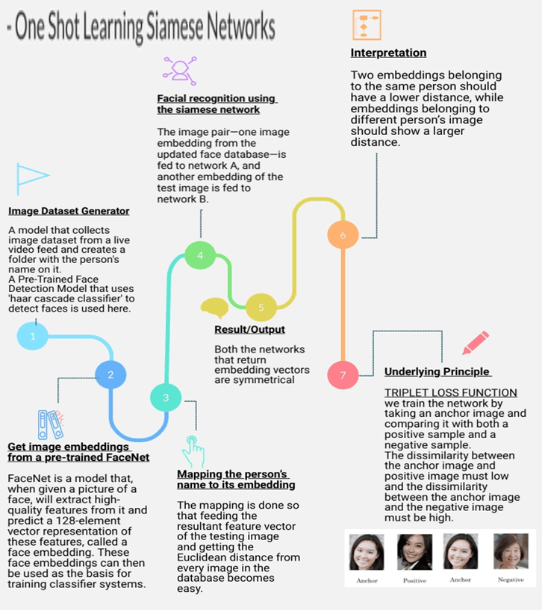
图 3:一次性学习 Siamese 网络
Fig 3 shows the steps involved in properly implementing the Siamese Network Model.
测试阶段:
如上所述,三元组损失函数使用 3 个图像(锚、正负)的多种组合进行训练。在此阶段,我们将研究具有不同大小支持集的一次性分类的不同方法。
N 支持集:是在测试阶段与新接收到的图像匹配的 N 个图像的集合。
我们找到支持集中的每个图像与新输入图像之间的相似距离 d。显示出最大相似度(d 的最小值)的图像决定了新图像将被分类到的类别。
N-way 分类的类型
这些是下面给出的一些 N 路分类版本:
- 4路一次性分类
- 10路一次性分类
- 20路一次性分类
请参阅图 4 以更好地理解 N 路分类的工作原理。
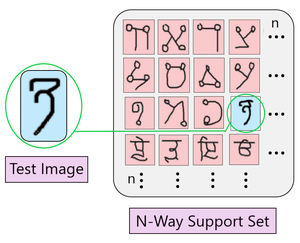
图 4:通过 N-way one Shot 分类进行测试
如上图所示,在 N-way one-shot 分类中,将有一个图像与输入测试图像最相似,与其余 (N-1) 对图像相比。我们可以根据需要设置 N 的值。我们必须了解在此处选择 N 的最佳值的重要性。
N的重要性:
随着 N 值的增加,支持集的复杂度也随之增加。因此,测试图像落入错误类别的可能性更高。如果 N 的值很小,则支持集中图像的特征很容易区分。因此,使分类任务更容易。
因此,根据我们的要求,我们在测试阶段选择合适的 N-way one-shot 分类模型以获得最佳结果。如有任何疑问/疑问,请在下方评论。