Perquisite – 卡桑德拉
在本文中,我们将讨论如何排列表数据以及如何在表中按降序排列聚类列。
为了首先按降序排列聚簇列,我们将创建一个带有聚簇列的表。
首先,我们将在不使用 order by 子句的情况下查看结果。
我们来看一下。
CREATE TABLE Emp_track (
emp_no int,
dept text,
name text,
PRIMARY KEY (dept, emp_no)
); 现在,我们将向表中插入一些数据。
我们来看一下。
insert into Emp_track(emp_no, dept, name) values (101, 'database', 'Ashish');
insert into Emp_track(emp_no, dept, name) values (102, 'database', 'rana');
insert into Emp_track(emp_no, dept, name) values (103, 'database', 'zishan');
insert into Emp_track(emp_no, dept, name) values (104, 'database', 'abi');
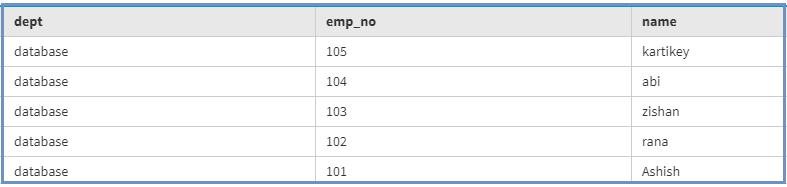
insert into Emp_track(emp_no, dept, name) values (105, 'database', 'kartikey'); 现在,要查看使用下面给出的以下 CQL 查询的结果。
select *
from Emp_track; 输出:
现在,我们将使用 order by 子句。
我们来看一下。
CREATE TABLE Emp_track (
emp_no int,
dept text,
name text,
PRIMARY KEY (dept, emp_no)
)
WITH CLUSTERING ORDER BY (emp_no desc); 在这里,我们将看到 emp_no 是一个集群列,为了按降序排列,我们将在创建表时使用 order by 子句。
现在,我们将向表中插入一些数据。
我们来看一下。
insert into Emp_track(emp_no, dept, name) values (101, 'database', 'Ashish');
insert into Emp_track(emp_no, dept, name) values (102, 'database', 'rana');
insert into Emp_track(emp_no, dept, name) values (103, 'database', 'zishan');
insert into Emp_track(emp_no, dept, name) values (104, 'database', 'abi');
insert into Emp_track(emp_no, dept, name) values (105, 'database', 'kartikey');
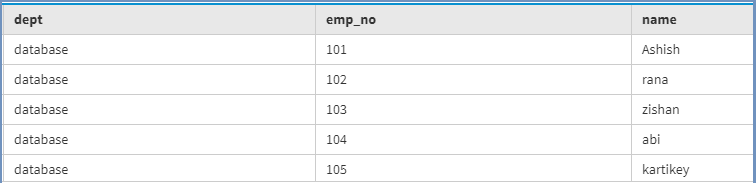
现在,要查看使用下面给出的以下 CQL 查询的结果。
select *
from Emp_track; 输出: