在文章中,我们已经讨论了用于模式搜索的 KMP 算法。在本文中,讨论了一种实时优化的 KMP 算法。
从上一篇文章可知,KMP(aka Knuth-Morris-Pratt)算法对模式P进行了预处理,并构造了一个失败函数F(也称为lps[])来存储子模式的最长后缀的长度P[1..l],也是 P 的前缀,对于 l = 0 到 m-1。请注意,子模式从索引 1 开始,因为后缀可以是字符串本身。在索引 P[j] 处发生不匹配后,我们将 j 更新为 F[j-1]。
原始 KMP 算法的运行时复杂度为 O(M + N),辅助空间为 O(M),其中 N 是输入文本的大小,M 是模式的大小。预处理步骤花费 O(M) 时间。很难实现比这更好的运行时复杂性,但我们仍然能够消除一些低效的转变。
原始KMP算法的低效率:考虑使用原始KMP算法的以下情况:
Input: T = “cabababcababaca”, P = “ababaca”
Output: Found at index 8
上述测试用例的最长适当前缀或 lps[] 是 {0, 0, 1, 2, 3, 0, 1}。让我们假设红色代表发生不匹配,绿色代表我们跳过的检查。因此,按照原KMP算法的搜索过程如下: 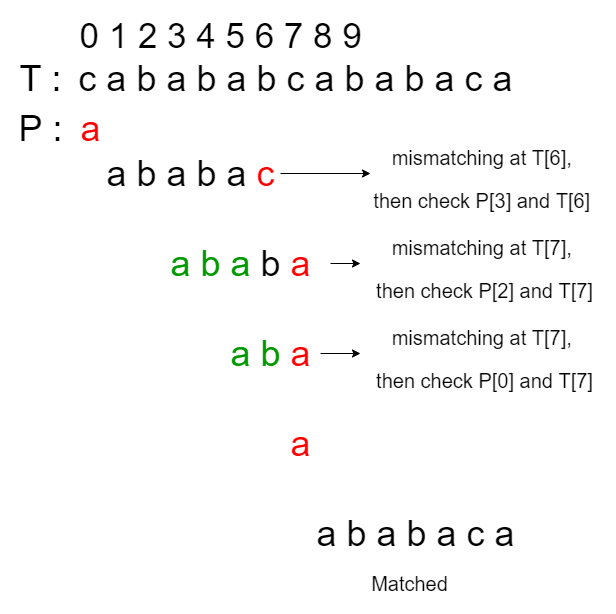
可以注意到的一件事是,在第三次、第四次和第五次匹配中,不匹配发生在同一位置 T[7]。如果我们可以跳过第四次和第五次匹配,那么可以进一步优化原始KMP算法来回答实时查询。
实时优化:在这种情况下,术语实时可以解释为最多检查文本 T 中的每个字符一次。在这种情况下,我们的目标是正确地移动模式(就像 KMP 算法一样),但不需要再次检查不匹配的字符。也就是说,对于上面相同的例子,优化后的 KMP 算法应该以如下方式工作: 
方法:实现目标的一种方法是修改预处理过程。
- 令K为模式P的字母大小。我们将构建一个故障表来包含K 个故障函数(即 lps[])。
- 故障表中的每个故障函数都映射到模式 P 的字母表中的一个字符(故障表中的键)。
- 回想一下,原始失效函数F[l] (或 lps[])存储的是 P[1..l] 的最长后缀的长度,它也是P的前缀,对于 l = 0 到 m-1,其中m 是图案的大小。
- 如果在T[i]和P[j]处发生不匹配,则j的新值将更新为F[j-1]并且计数器“i”将保持不变。
- 在我们新的故障表FT[][] 中,如果故障函数F’ 被映射为字符c,则F'[l]应存储 P[1..l] + c (‘+ ‘ 表示appending),也是P 的前缀,对于l = 0 到m-1。
- 直觉是进行适当的转换,但也取决于不匹配的字符。这里的字符c 也是失败表中的一个键,是我们对文本 T 中不匹配字符的“猜测”。
- 也就是说,如果不匹配的字符是c,我们应该如何正确地移动模式?由于我们在预处理步骤中构建故障表,因此我们必须对不匹配的字符进行足够的猜测。
- 因此,失败表中 lps[] 的数量等于模式字母表的大小,并且每个值,失败函数,应该与键不同,键是P 中的一个字符。
- 假设我们已经构建了所需的故障表。令FT[][]为故障表, T为文本, P为模式。
- 那么,在匹配过程中,如果在T[i]和P[j]处出现不匹配(即T[i] != P[j]):
- 如果T[i]是P 中的字符,则j将更新为FT[T[i]][j-1] ,’ i ‘ 将更新为 ‘ i + 1 ‘。我们这样做是因为我们保证T[i]被匹配或跳过。
- 如果 T[i] 不是字符,则 ‘j’ 将更新为 0,’i’ 将更新为 ‘i + 1’。
- 请注意,如果不发生不匹配,则行为与原始 KMP 算法完全相同。
构建故障表:
- 为了构建失效表 FT[][],我们需要原始 KMP 算法中的失效函数F(或 lps[])。
- 由于 F[l] 告诉我们子模式 P[1..l] 的最长后缀的长度,它也是 P 的前缀,所以存储在故障表中的值比它多一步。
- 也就是说,对于失效表FT[][]中的任意键t,FT[t]中存储的值是满足字符’t’的失效函数,FT[t][l]存储的是子模式 P[1..l] + t(‘+’ 表示追加) 的最长后缀,也是 P 的前缀,表示 l 从 0 到 m-1。
- F[l] 已经保证 P[0..F[l]-1] 是子模式 P[1..l] 的最长后缀,所以我们需要检查 P[F[l] ] 是 t。
- 如果为真,那么我们可以将 FT[t][l] 分配为 F[l] + 1,因为我们保证 P[0..F[l]] 是子模式 P[1] 的最长后缀..l] + t。
- 如果为假,则表示 P[F[l]] 不是 t。也就是说,我们在字符P[F[l]] 与字符t 的匹配失败,但 P[0..F[l]-1] 匹配 P[1..l] 的后缀。
- 借用 KMP 算法的思想,就像我们在原始 KMP 算法中如何计算失败函数,如果不匹配发生在 P[F[l]] 且不匹配字符t,我们希望更新从 FT[ 开始的下一个匹配t][F[l]-1]。
- 即我们利用KMP算法的思想来计算故障表。注意 F[l] – 1 总是小于 l,所以当我们计算 FT[t][l] 时,FT[t][F[l] – 1] 已经为我们准备好了。
- 一种特殊情况是,如果 F[l] 为 0 且 P[F[l]] 不是 t,则 F[l] – 1 的值为 -1,在这种情况下,我们将更新 FT[t][l ] 到 0。(即不存在 P[1..l] + t 的后缀,因此它是 P 的前缀。)
- 作为故障表构建的结论,当我们计算FT[t][l]时,对于从0到m-1的任意键t和l,我们将检查:
If P[F[l]] is t, if yes: FT[t][l] <- F[l] + 1; if no: check if F[l] is 0, if yes: FT[t][l] <- 0; if no: FT[t][l] <- FT[t][F[t] - 1];这是上述示例的所需输出,输出包括故障表以便更好地说明。
例子:
Input: T = “cabababcababaca”, P = “ababaca”
Output: Failure Table:
Key Value
‘a’ [1 1 1 3 1 1 1]
‘b’ [0 0 2 0 4 0 2]
‘c’ [0 0 0 0 0 0 0]
Found pattern at index 8下面是上述方法的实现:
// C++ program to implement a // real time optimized KMP // algorithm for pattern searching #include#include #include #include using std::string; using std::unordered_map; using std::set; using std::cout; // Function to print // an array of length len void printArr(int* F, int len, char name) { cout << '(' << name << ')' << "contain: ["; // Loop to iterate through // and print the array for (int i = 0; i < len; i++) { cout << F[i] << " "; } cout << "]\n"; } // Function to print a table. // len is the length of each array // in the map. void printTable( unordered_map & pattern_alphabet, int* F, unordered_map & pattern_alphabet) { // Size of the pattern int m = P.size(); // Size of the text int n = T.size(); // Initialize the Failure Function int F[m]; // Constructing the failure function // using KMP algorithm constructFailureFunction(P, F); printArr(F, m, 'F'); unordered_map pattern_alphabet = { 'a', 'b', 'c' }; KMP(T, P, pattern_alphabet); } 输出:(F)contain: [0 0 1 2 3 0 1 ] Failure Table: { (c)contain: [0 0 0 0 0 0 0 ] (a)contain: [1 1 1 3 1 1 1 ] (b)contain: [0 0 2 0 4 0 2 ] } Found at index 8注意:上面的源代码会找到第一次出现的模式。稍加修改,它可以用于查找所有出现。
时间复杂度:
- 新的预处理步骤的运行时间复杂度为 O(
 , 在哪里
, 在哪里 是模式P的字母集,M是P的大小。
是模式P的字母集,M是P的大小。 - 整个改进的 KMP 算法的运行时间复杂度为 O(
 )。 O(
)。 O(  )。
)。 - 运行时间和空间使用情况看起来比原始 KMP 算法“更糟”。但是,如果我们在多个文本中搜索相同的模式或者模式的字母集很小,因为预处理步骤只需要进行一次,并且文本中的每个字符最多会比较一次(实时) .因此,它比原来的 KMP 算法更有效,并且在实践中很好。
如果您想与行业专家一起参加直播课程,请参阅Geeks Classes Live
- 新的预处理步骤的运行时间复杂度为 O(